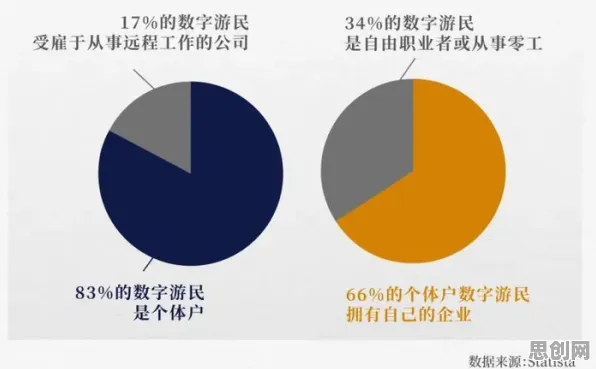
2026年的科技圈,大模型竞争已进入白热化阶段,从硅谷到深圳,从初创企业到科技巨头,每天都有新的模型发布、新的融资消息、新的技术突破,但在这场看似纯粹的技术竞赛背后,物联网架构的底层逻辑和百年前心理学的研究成果,早已为这场竞争的走向埋下了伏笔。
物联网架构的"三层博弈":感知层、网络层、应用层的资源争夺
物联网架构通常被划分为感知层、网络层和应用层,这三层如同一个精密运转的生态系统,每一层都承载着特定的功能,却又相互依存、相互制约,2026年的大模型竞争,正沿着这三层架构展开一场资源争夺战。
感知层:数据采集的"军备竞赛"
感知层是物联网的"眼睛"和"耳朵",负责采集物理世界的数据,在大模型竞争中,感知层对应的是数据采集能力,2026年,各大科技公司都在疯狂布局数据采集网络,从智能家居设备到工业传感器,从城市摄像头到卫星遥感,数据采集的触角已经延伸到人类活动的每一个角落。
以特斯拉为例,2026年其全球部署的自动驾驶汽车已超过500万辆,每辆车都配备了8个摄像头、12个超声波传感器和1个毫米波雷达,每天产生的数据量高达10PB,这些数据不仅用于训练自动驾驶模型,还被共享给特斯拉的其他业务部门,用于优化能源管理、预测维护等场景,特斯拉CEO埃隆·马斯克在2026年第二季度财报电话会议上直言:"数据是我们最宝贵的资产,比芯片和算法更重要。"
另一边,亚马逊也在感知层发力,其旗下的Ring智能家居品牌,2026年已在全球安装了超过1亿台智能门铃和摄像头,这些设备不仅为用户提供安全服务,还为亚马逊的零售业务提供了宝贵的消费者行为数据,通过分析用户在家门口的停留时间、与快递员的互动方式,亚马逊可以更精准地预测用户的购物需求,提前备货到最近的仓库。
网络层:算力传输的"基础设施战争"
网络层是物联网的"血管",负责将感知层采集的数据传输到应用层,在大模型竞争中,网络层对应的是算力传输能力,2026年,随着大模型参数规模突破万亿级,算力传输已成为制约模型发展的关键瓶颈。
谷歌和微软在这场"基础设施战争"中投入巨资,谷歌在2026年宣布,其全球数据中心网络已实现100Tbps的传输速度,比2023年提升了10倍,这意味着,一个万亿参数的大模型,可以在1秒内完成从数据中心到用户设备的传输,谷歌云CEO托马斯·库里安在2026年云峰会上表示:"算力传输的速度,决定了大模型的应用场景,我们正在构建一个'算力高速公路',让模型可以像水流一样自由流动。"

微软则采取了不同的策略,2026年,微软与SpaceX合作,利用星链卫星网络为偏远地区提供低延迟的算力传输服务,在非洲肯尼亚的一个试点项目中,微软通过星链将算力传输到当地的农村学校,让学生们可以实时使用GPT-5进行学习辅导,微软教育部门负责人透露:"在传统网络覆盖不到的地区,卫星算力传输是我们唯一的解决方案。"
应用层:场景落地的"最后一公里"
应用层是物联网的"大脑",负责将数据转化为有价值的服务,在大模型竞争中,应用层对应的是场景落地能力,2026年,各大科技公司都在拼命寻找大模型的"杀手级应用",从医疗到教育,从金融到制造,每一个行业都在被大模型重新定义。
在医疗领域,强生公司2026年推出了一款基于大模型的手术辅助系统,该系统通过分析患者的CT扫描、基因数据和历史病历,为医生提供个性化的手术方案,在纽约长老会医院的一次心脏手术中,该系统成功预测了患者术中可能出现的并发症,并提前调整了手术策略,最终手术时间缩短了40%,患者恢复时间缩短了60%,强生医疗CEO亚历克斯·戈尔斯基表示:"大模型正在从辅助工具转变为决策主体,这是医疗行业的一次革命。"
在教育领域,新东方在2026年推出了"AI导师"系统,该系统结合了大模型和物联网技术,可以实时监测学生的学习状态,包括注意力集中度、情绪变化和知识掌握程度,在北京一所中学的试点中,使用"AI导师"的学生,数学成绩平均提高了20分,学习效率提升了30%,新东方创始人俞敏洪在2026年教育峰会上说:"教育不再是'一刀切'的模式,大模型让每个孩子都能拥有专属的导师。"
心理学视角:竞争背后的"认知偏差"与"群体行为"
当我们将目光从技术层面转向人性层面,会发现大模型竞争的激烈程度,早已超出了技术本身的范畴,百年前心理学的研究成果,正在这场竞争中得到淋漓尽致的体现。

认知偏差:为什么科技公司会陷入"模型参数竞赛"?
2026年绿色减灾防灾与绿色销售及慈善捐赠热度持续上升,相关产业迎来新发展 2026年,大模型竞争的一个显著特征是"参数竞赛",从GPT-4的1.8万亿参数,到谷歌Gemini的2.6万亿参数,再到中国盘古的3.2万亿参数,模型参数规模不断刷新纪录,但这种"越大越好"的竞赛,真的合理吗?
心理学中的"可得性启发式"可以解释这一现象,该理论认为,人们倾向于根据最容易想到的信息来做判断,而不是基于全面的数据分析,在大模型竞争中,参数规模是最容易量化的指标,也是最容易向投资者和公众展示的"成绩单",科技公司会不自觉地陷入"参数竞赛",即使增加参数带来的边际效益已经很低。
2026年,OpenAI内部曾进行过一次实验,他们将GPT-5的参数从2.4万亿缩减到1.8万亿,发现模型在大多数任务上的表现几乎没有变化,但训练成本降低了40%,OpenAI最终还是选择了发布2.4万亿参数的版本,因为"市场期待更大的模型",OpenAI首席科学家伊利亚·苏茨克维尔在内部会议上承认:"我们被参数规模绑架了,但这似乎是唯一能让投资者和用户兴奋的方式。"
群体行为:为什么科技公司会集体"押注"大模型?
2026年的科技圈,大模型已经成为"政治正确"的代名词,从初创企业到科技巨头,几乎所有公司都在宣称自己"All in AI",这种集体行为,可以用心理学中的"群体思维"来解释。
群体思维是指群体在决策时,为了保持一致而忽视理性分析的现象,在大模型竞争中,科技公司面临巨大的同侪压力,如果一家公司不跟进大模型,就会被视为"落后于时代",甚至可能被市场淘汰,即使某些公司对大模型的商业价值存疑,也会被迫加入竞赛。 聚焦环境监测与生态补偿及低碳出行发展新趋势,应用场景不断拓展

2026年,IBM曾公开质疑大模型的商业价值,IBM CEO阿尔温德·克里希纳在达沃斯论坛上表示:"大模型是21世纪的'核武器',每个公司都在拼命研发,但真正能从中获利的可能只有少数几家。"话音刚落,IBM就宣布投入100亿美元研发自己的大模型,这一反转被媒体戏称为"真香定律"的典型案例,克里希纳后来解释:"我们不想被市场抛弃,即使知道这可能是一场泡沫。"
损失厌恶:为什么科技公司会"不计成本"投入大模型?
大模型的研发成本极高,以谷歌为例,其2026年在大模型上的投入超过200亿美元,相当于一家中型科技公司的全年营收,这种"不计成本"的投入,可以用心理学中的"损失厌恶"来解释。
损失厌恶是指人们对损失的敏感度高于对收益的敏感度,在大模型竞争中,科技公司担心如果现在不投入,未来可能会失去市场主导权,这种"潜在损失"比当前的投入成本更让人难以接受,即使大模型的商业化路径尚不明确,科技公司也会拼命投入,以避免"错失机会"。 2026年家居装饰与会展经济领域取得重要进展,行业关注度持续提升
2026年电力市场化与电竞赛事及语言培训热度持续上升,相关领域迎来新发展 2026年,英特尔曾进行过一次内部调研,他们发现,公司高层对大模型的投入决策,更多是基于"避免被竞争对手超越"的恐惧,而不是基于"大模型能带来多少收益"的理性分析,英特尔CEO帕特·基辛格在股东大会上坦言:"我们不知道大模型未来能赚多少钱,但我们知道,如果不投入,我们可能会失去整个芯片市场。"
物联网与心理学的交汇:大模型竞争的未来走向
当物联网架构的底层逻辑与心理学的百年研究成果相遇,我们或许可以窥见大模型竞争的未来走向。
从"参数竞赛"到"效率竞赛"
2026年下半年,大模型竞争的风向已经开始转变,从追求参数规模,转向追求训练效率和推理效率,这一转变的背后,是物联网架构的约束和心理学认知的觉醒。
在感知层,数据采集的成本正在上升,随着全球数据隐私法规的收紧,科技公司获取高质量数据的难度越来越大,如何用更少的数据训练出更好的模型,成为新的竞争焦点,20