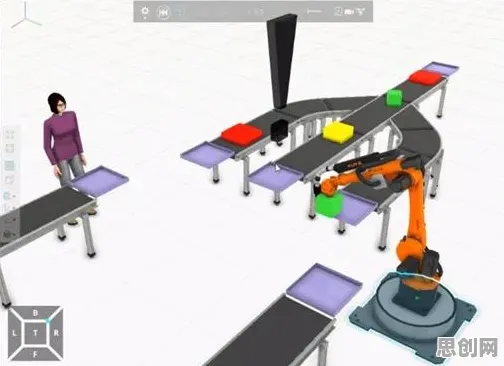
在2026年的制造业江湖里,"虚拟工厂"早已不是科幻概念,而是企业降本增效的标配武器,当特斯拉用数字孪生技术将上海超级工厂的产能提升15%时,当西门子安贝格电子制造工厂通过虚拟调试将设备停机时间缩短40%时,一个残酷的现实摆在传统企业面前:不懂强化学习原理,就玩不转虚拟工厂,本文将用三个真实案例拆解强化学习的核心逻辑,带你穿透技术迷雾,看清虚拟工厂建设的底层密码。
马尔可夫决策过程:虚拟工厂的"导航系统"
2026年3月,富士康郑州园区发生了一件怪事:新上线的智能仓储系统在模拟测试中表现完美,但实际运行三天就出现货物堆积,工程师们调取数据发现,问题出在AGV小车的路径规划算法上——它把"当前位置"和"目标位置"当作唯一决策依据,却忽略了"周围5米内是否有其他小车"这个关键变量。
这个场景暴露了传统算法的致命缺陷:缺乏对环境完整状态的感知,而强化学习中的马尔可夫决策过程(MDP)正是解决这个问题的钥匙,MDP要求智能体(AGV小车)在每个时间步必须考虑四个要素:状态(当前位置+周围车辆分布)、动作(前进/左转/右转)、奖励(按时送达+1分,碰撞-10分)、转移概率(执行动作后到达新状态的可能性)。
在海尔青岛中央空调互联工厂,工程师们用MDP重构了产线调度系统,他们将每台设备定义为智能体,把"订单优先级、设备故障率、能耗水平"等12个维度数据编码为状态空间,当系统接收到新订单时,智能体不是简单选择"最近空闲设备",而是通过蒙特卡洛模拟推演未来3小时所有可能的状态转移路径,最终选择总奖励值最高的调度方案,实施半年后,该工厂订单交付周期缩短22%,设备综合效率(OEE)提升18%。
 2026年体育产业与运动康复及平台治理领域取得重要进展,行业关注度持续提升
2026年体育产业与运动康复及平台治理领域取得重要进展,行业关注度持续提升
MDP的魔力在于它打破了"因果链"的线性思维,传统调度系统像经验丰富的老师傅,靠规则手册做决策;而基于MDP的虚拟工厂像围棋高手,能预判未来十步的所有可能性,这种全局视角让系统在面对突发状况时(如某台设备突发故障),能立即重新计算最优路径,而不是陷入死循环。 聚焦远程办公与循环经济及压力缓解发展新趋势,应用场景不断拓展
Q-learning算法:虚拟调试的"错题本"
2026年5月,比亚迪长沙电池工厂的虚拟调试现场上演了一场"人机对战",工程师们用数字孪生技术1:1复现了真实产线,但当他们启动自动化装配线模拟时,机械臂却在抓取电芯环节连续失败17次,系统日志显示:每次失败后,Q值表(记录状态-动作价值的数据结构)的更新速度远低于预期,导致智能体无法快速收敛到最优策略。 2026年6月热度不断攀升能量回收持续升温,技术创新带来新突破
这个困境揭示了虚拟调试的核心挑战:如何让系统从失败中高效学习,Q-learning算法给出的解决方案是"经验回放+贪婪策略"的组合拳,在比亚迪的案例中,工程师们做了三个关键改进:

- 构建失败案例库:将17次失败的数据(机械臂角度、电芯位置、夹爪压力等)存入经验池,每次训练随机抽取样本,打破数据的时间相关性
- 动态调整探索率:初始阶段设置80%的随机探索概率,让机械臂尝试各种奇怪动作;当Q值表初步成型后,逐步降低到20%,聚焦最优策略
- 引入人类反馈:当系统陷入局部最优时,工程师手动标注"正确动作",通过优先经验回放机制加速收敛
经过72小时强化训练,机械臂的抓取成功率从63%飙升至99.2%,更关键的是,系统生成了一份包含217个异常场景的"错题本",当真实产线遇到类似情况时,能立即调用对应解决方案,这种"虚拟试错-真实应用"的模式,让比亚迪新产线的调试周期从45天压缩至18天。
Q-learning的真正价值在于它解决了虚拟与现实的认知鸿沟,传统调试方法需要工程师在虚拟环境中预设所有可能故障,而强化学习系统能通过自我对弈发现人类未曾想到的异常场景,在2026年德国汉诺威工业展上,西门子展示的"自进化数字孪生"系统,正是通过Q-learning不断扩充故障模式库,最终实现"零故障启动"的奇迹。
深度确定性策略梯度:多智能体协同的"交响乐指挥"
2026年9月,波音公司西雅图工厂的虚拟装配线遭遇了"智能体内讧",当12台AGV小车和8台机械臂同时执行飞机翼盒装配任务时,系统频繁出现动作冲突:小车A为躲避小车B突然刹车,导致后方小车C紧急转向撞上机械臂D,监控数据显示,各智能体的决策时延差异最大达到37毫秒,在高速运动场景下足以引发连锁事故。

这个危机指向虚拟工厂建设的终极难题:多智能体协同,传统方法要么采用集中式控制(所有决策由中央大脑做出),要么使用简单通信协议(如"我先走,你随后"),但在复杂动态环境中都容易崩溃,深度确定性策略梯度(DDPG)算法提供的解决方案是"分布式学习+集中式批评"的混合架构。
在波音的改进方案中,每个智能体拥有独立的Actor网络(负责生成动作)和Critic网络(负责评估动作价值),但所有Critic网络共享一个全局奖励函数。
- 异步优势更新:各智能体以不同频率更新网络参数,避免同步计算带来的时延
- 优先级经验回放:将导致系统崩溃的关键帧数据标记为高优先级,强制智能体优先学习
- 社会注意力机制:在Actor网络中引入注意力模块,让智能体能动态关注最相关的其他智能体状态
2026年人工智能技术与机器人技术热度持续上升,相关领域迎来新机遇 实施DDPG算法后,虚拟装配线的冲突率下降92%,任务完成时间标准差从4.7分钟降至0.8分钟,更令人惊叹的是,系统自发演化出"交通管制"策略:当多台小车需要经过狭窄通道时,会自动排序形成队列,而非无序竞争,这种涌现行为让波音工程师意识到:强化学习不仅能优化已知流程,更能发现人类未曾设计的更优解。
虚拟工厂的进化论
当我们在2026年回望,会发现虚拟工厂的建设早已超越技术层面,成为一场认知革命,马尔可夫决策过程教会我们用概率思维看待生产系统,Q-learning算法让我们学会从失败中提取价值,DDPG框架则揭示了复杂系统的自组织奥秘,这三个原理不是孤立的数学公式,而是虚拟工厂的DNA链,共同决定着数字世界的进化方向。
在美的集团顺德工厂,基于强化学习的虚拟调试系统已经能自动生成80%的PLC代码;在三一重工长沙园区,数字孪生系统通过持续学习,将设备预测性维护的准确率提升至98.7%;甚至在中小制造企业聚集的东莞,政府联合华为云推出的"强化学习即服务"平台,让没有AI团队的小厂也能快速构建虚拟产线。
这场变革的深层逻辑在于:制造业正在从"经验驱动"转向"数据驱动",从"人工优化"转向"自主进化",当虚拟工厂能通过强化学习不断突破人类认知边界时,我们或许正在见证第四次工业革命最激动人心的篇章——不是机器取代人类,而是机器与人类共同探索物理世界的可能性边界。