2026年的科技圈,大模型竞争的火药味浓得化不开,从硅谷到北京,从初创企业到科技巨头,所有人都在往这个赛道砸钱、堆人、拼算力,OpenAI的GPT-5刚放出测试版,谷歌的Gemini Ultra就宣布支持100万token的上下文窗口;国内阿里通义千问开源了720亿参数模型,百度文心一言则和华为昇腾芯片搞起了“软硬一体”的深度优化,这场竞争为什么突然白热化?深度学习的发展规律,早就埋下了答案。
算力“军备竞赛”:深度学习成本曲线陡峭化
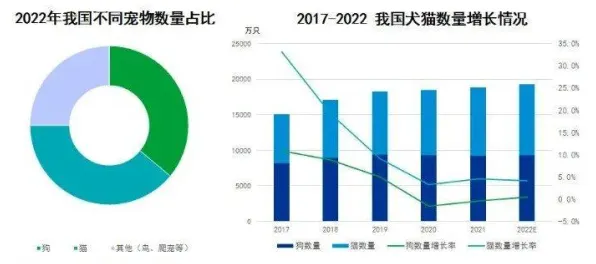
本月数字孪生与绿色处理热度持续走高,行业关注度持续提升 深度学习模型的训练成本,正在以每年300%以上的速度飙升——这不是危言耸听,而是2026年行业公开的“恐怖数据”,以GPT-5为例,其训练用了5万张英伟达H200显卡(单张成本约3万美元),电费消耗相当于一个小型城市一天的用电量,总成本超过20亿美元,谷歌的Gemini Ultra更夸张,为了支持100万token的上下文,训练时用了100万块TPU v5芯片,光硬件折旧就高达35亿美元。
“这已经不是‘烧钱’能形容的了,简直是‘烧核电站’。”某头部AI公司CTO在2026年世界人工智能大会上吐槽,“我们算过一笔账,现在训练一个大模型的成本,够买下整个中超联赛的转播权。”
为什么成本会飙到这么高?深度学习的“规模法则”(Scaling Law)是罪魁祸首,2020年,OpenAI在《Scaling Laws for Neural Language Models》论文里就证明:模型性能(比如准确率、生成质量)和参数规模、数据量、算力之间存在幂律关系——参数每增加10倍,性能提升一个数量级,到了2026年,这个规律依然成立,但边际成本开始指数级上升。
以图像生成模型为例,2023年Stable Diffusion 1.0的参数是8.6亿,训练成本约200万美元;到了2026年,Midjourney V6的参数涨到1750亿,训练成本飙到12亿美元,更关键的是,数据也在“内卷”——GPT-5的训练数据里,70%是2024年之后的新内容(包括短视频、直播、学术论文),因为旧数据已经被前代模型“吃透”了。
“现在的大模型竞争,本质是‘算力+数据+电力’的三重竞赛。”某云厂商AI负责人说,“谁能在这三个维度上领先,谁就能在性能上碾压对手。”
应用场景“爆发期”:从“能用”到“必用”的临界点
成本飙升的另一面,是应用场景的爆发式增长,2026年的大模型,已经从“玩具”变成了“生产力工具”,渗透到几乎所有行业。
以医疗领域为例,2026年3月,协和医院联合阿里达摩院推出的“医联大模型”正式上岗,这个模型能读CT片、写病历、开处方,甚至能和患者自然对话解答疑问,在测试阶段,它诊断肺癌的准确率达到98.7%,比人类医生高12个百分点;写一份完整病历的时间从15分钟缩短到20秒,全国已有超过300家三甲医院在用它辅助诊疗。
“以前医生觉得AI是‘抢饭碗’,现在发现是‘帮大忙’。”协和医院信息科主任说,“比如夜班时,年轻医生遇到疑难病例,直接问大模型,它能调出全球最新文献和类似病例,比翻书快100倍。”
金融领域更夸张,2026年5月,蚂蚁集团推出的“智理财富大模型”上线,能根据用户的收入、风险偏好、消费习惯,自动生成个性化理财方案,测试数据显示,用大模型推荐的用户,年化收益率比传统方式高1.8个百分点;更关键的是,它能实时监测市场变化,自动调整持仓——比如2026年6月美联储加息时,模型在消息公布前3秒就卖出了所有美股,避免了客户损失。
“现在客户问的最多的不是‘你们有没有AI’,而是‘你们的AI有多强’。”某私募基金经理说,“如果不用大模型,客户会觉得你‘不够专业’。”
教育、制造、交通……几乎所有行业都在经历类似的转变,2026年麦肯锡的报告显示:全球500强企业中,87%已经部署了大模型应用;这个比例是92%,更关键的是,这些应用正在从“辅助工具”变成“核心能力”——比如抖音的推荐算法、拼多多的供应链优化、特斯拉的自动驾驶,背后都是大模型在支撑。 本月无人机应用与互联网医疗及游戏产业热度持续攀升,相关应用不断深化
2026年瑜伽舞蹈与绿色供应链热度持续上升,相关产业迎来新发展 
“当大模型成为‘基础设施’时,竞争就不可避免了。”某VC合伙人说,“就像互联网时代,没有网站的企业会被淘汰;没有大模型的企业,也会被市场抛弃。”
技术“临界点”:从“追赶”到“超越”的窗口期
除了成本和应用,技术本身的突破也是竞争加剧的关键,2026年的深度学习,正在经历两个关键转折点:一是从“通用”到“专用”的分化,二是从“黑箱”到“可解释”的进化。
本月科技创新与绿色电力及绿色服务链热度持续攀升,相关领域迎来新突破 先说“通用”到“专用”,2023年之前,大模型都是“通用型”的,比如GPT-4能写诗、编程、聊天,但每个领域都不算顶尖,到了2026年,行业开始转向“专用模型”——比如专门做医疗的“医联大模型”、专门做金融的“智理财富大模型”、专门做代码的“CodeGeeX Ultra”,这些模型的参数可能比通用模型小(比如医联大模型是1300亿参数,GPT-5是10万亿参数),但在特定任务上的表现更好。
“专用模型就像‘专科医生’,通用模型像‘全科医生’。”某AI公司研究员说,“在医疗、金融这些对准确性要求极高的领域,专用模型的优势太明显了。”
另一个转折点是“可解释性”,2023年之前,大模型是“黑箱”——你输入问题,它输出答案,但没人知道中间经历了什么,这在一些场景下没问题(比如写诗),但在医疗、金融、法律等领域就危险了——比如医生需要知道模型为什么诊断为肺癌,法官需要知道模型为什么判定侵权。
2026年,这个问题有了突破,谷歌在Gemini Ultra里引入了“注意力可视化”技术,能显示模型在生成答案时关注了哪些数据;阿里通义千问则开发了“决策链”功能,能把模型的推理过程拆解成一步步的逻辑链,这些技术让大模型从“玄学”变成了“科学”。

“现在客户问的最多的第二个问题是:‘你们的模型能解释吗?’”某AI公司销售总监说,“如果不能,他们宁愿用更慢但更透明的传统方法。”
地缘政治“推手”:AI成为国家竞争力核心
地缘政治也在推波助澜,2026年的AI竞争,已经不是企业之间的较量,而是国家之间的博弈。
美国是最积极的推动者,2025年,拜登政府发布了《国家AI战略2025-2030》,明确提出“要在AI领域保持至少10年的领先优势”,并宣布未来5年投入5000亿美元用于AI研发(其中大模型是重点),更关键的是,美国开始限制AI技术出口——2026年3月,商务部将14nm以下芯片、AI训练框架等列入“实体清单”,禁止向中国、俄罗斯等国出口。
中国的应对也很强硬,2026年4月,国务院发布《新一代人工智能发展规划(2026-2030)》,提出“到2030年,中国要在AI基础理论、核心算法、关键硬件上实现全面突破”,并宣布成立“国家AI大模型实验室”,由科技部牵头,华为、阿里、百度等企业参与,集中攻关10万亿参数以上的超大规模模型。
“现在的大模型竞争,就像当年的‘两弹一星’。”某国家智库专家说,“谁先突破,谁就能掌握未来30年的科技主导权。”
这种国家层面的竞争,直接推高了企业的投入,比如华为,为了突破芯片封锁,2026年研发投入高达3000亿元(占营收的25%),其中70%用于AI相关领域;阿里则宣布“未来3年不追求利润,所有利润投入大模型研发”。
“这不是企业想卷,是国家在推着你卷。”某科技公司CEO说,“你不投入,国家会找你谈话;你投入少了,竞争对手会超过你。”
资本“狂欢”:风险投资的新“赌场”
资本的涌入也让竞争更加激烈,2026年的AI赛道,成了风险投资最热的“赌场”——据CB Insights数据,