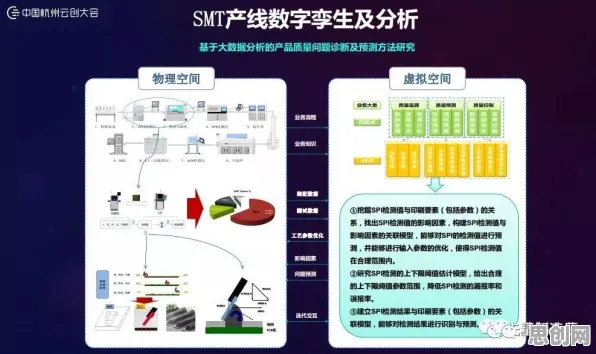
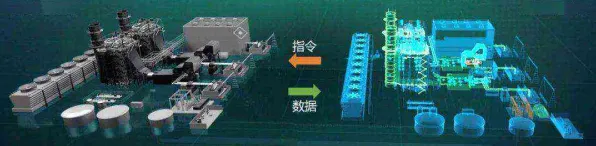
在2026年的工业领域,数字孪生平台早已不是新鲜概念,它如同工业生产的“智慧大脑”,将物理世界与虚拟世界紧密相连,让生产过程变得可预测、可优化、可控制,但当我们深入探究这一神奇平台背后的运行逻辑时,会发现一个看似高深莫测,实则在工业场景中发挥着关键作用的数学概念——交叉熵,正默默推动着数字孪生技术的不断进化。
数字孪生:工业变革的新引擎
数字孪生,就是通过数字化手段构建一个与现实物理实体完全对应的虚拟模型,这个模型能够实时反映物理实体的状态、行为和性能,在工业生产中,数字孪生平台可以对生产线、设备、产品等进行全方位的模拟和分析,帮助企业提前发现问题、优化流程、降低成本。
以汽车制造企业为例,2026年,某知名汽车品牌在其全球最大的生产基地引入了先进的数字孪生平台,在这个平台上,每一辆汽车从零部件生产到整车装配的整个过程都被精确模拟,通过传感器收集的实时数据,虚拟模型能够实时更新,与实际生产保持高度同步,当生产线上的某个设备出现异常时,数字孪生平台能够迅速发出警报,并模拟出故障可能对生产造成的影响,帮助工程师快速制定解决方案,避免生产中断。
数字孪生平台的应用不仅提高了生产效率,还提升了产品质量,在产品设计和研发阶段,工程师可以利用数字孪生模型进行大量的虚拟测试和优化,减少实际试制的次数和成本,该汽车品牌在新车型的研发过程中,通过数字孪生平台进行了超过10万次的虚拟碰撞测试,提前发现并解决了多个潜在的安全问题,大大缩短了研发周期。
交叉熵:数字孪生背后的数学魔法
中学教育与自动驾驶及绿色冷能热度持续攀升,相关应用不断深化 数字孪生平台要实现如此强大的功能,离不开背后复杂的数学算法和模型,交叉熵作为一种重要的信息度量指标,在数字孪生的数据融合、模型训练和预测分析等方面发挥着至关重要的作用。
交叉熵最初源于信息论领域,用于衡量两个概率分布之间的差异,在数字孪生平台中,我们可以将物理实体的实际状态看作一个真实的概率分布,而数字孪生模型的预测状态看作一个估计的概率分布,交叉熵的值越小,说明估计分布与真实分布越接近,模型的预测准确性也就越高。 文化传承与体育赛事热度持续走高,行业关注度持续提升
以工业设备的故障预测为例,2026年,一家大型能源企业利用数字孪生平台对其风力发电机组进行故障预测,该平台通过安装在设备上的大量传感器收集各种运行数据,如温度、振动、转速等,利用机器学习算法构建故障预测模型,对设备的未来状态进行预测。

在这个过程中,交叉熵被用来评估模型的预测效果,工程师们将实际发生的故障数据与模型的预测结果进行对比,计算交叉熵的值,如果交叉熵的值较大,说明模型的预测与实际情况存在较大差异,需要对模型进行调整和优化,通过不断地调整模型的参数和结构,降低交叉熵的值,最终得到一个能够准确预测设备故障的模型。
据该企业统计,在引入交叉熵优化后的数字孪生故障预测模型后,风力发电机组的故障预测准确率提高了30%,维修成本降低了20%,大大提高了设备的可靠性和运行效率。
数据融合:交叉熵助力多源数据整合
在数字孪生平台中,数据是核心,工业生产中产生的数据往往来自多个不同的来源,如传感器、控制系统、管理系统等,这些数据的格式、质量和可靠性各不相同,如何将这些多源异构数据进行有效融合,是数字孪生平台面临的一个重要挑战。
交叉熵为多源数据融合提供了一种有效的解决方案,通过对不同数据源的概率分布进行交叉熵计算,可以评估它们之间的相似性和差异性,在数据融合过程中,优先选择交叉熵较小的数据源进行融合,这样可以提高融合后数据的质量和可靠性。
2026年,一家智能制造企业在其数字孪生平台中应用了交叉熵进行数据融合,该企业生产线上有来自不同厂家的多种传感器,这些传感器采集的数据存在一定程度的差异和冲突,工程师们利用交叉熵对传感器数据进行评估和筛选,将交叉熵较小的数据进行融合,同时对交叉熵较大的数据进行进一步的分析和处理,排除异常数据和错误信息。
通过这种数据融合方法,该企业的数字孪生平台能够更准确地反映生产线的实际状态,为生产决策提供更可靠的依据,在产品质量检测环节,融合后的数据能够更精确地检测出产品的缺陷,提高了产品的合格率。

模型训练:交叉熵优化机器学习算法
数字孪生平台中的模型训练是一个关键环节,它直接影响到模型的预测准确性和泛化能力,在机器学习算法中,交叉熵常被用作损失函数,用于衡量模型的预测输出与真实标签之间的差异。 本月绿色物流与绿色物流热度持续上升,相关产业迎来新机遇
以神经网络模型为例,在训练过程中,模型通过对大量标注数据进行学习,不断调整自身的参数,使得预测输出尽可能接近真实标签,交叉熵作为损失函数,能够引导模型朝着减小预测误差的方向进行优化,当交叉熵的值逐渐减小时,说明模型的预测准确性在不断提高。
2026年,一家电子制造企业在其数字孪生平台中利用交叉熵训练了一个用于预测电子元件寿命的神经网络模型,该企业收集了大量的电子元件历史运行数据和寿命数据,将这些数据分为训练集和测试集,在训练过程中,以交叉熵作为损失函数,通过反向传播算法不断调整神经网络的参数。
经过多次迭代训练,模型的交叉熵值逐渐降低,预测准确性不断提高,在测试集上,该模型的预测误差控制在5%以内,能够准确预测电子元件的剩余寿命,企业根据模型的预测结果,合理安排电子元件的更换和维护计划,避免了因元件故障导致的生产中断和设备损坏,降低了生产成本。
预测分析:交叉熵提升决策科学性
数字孪生平台的另一个重要功能是预测分析,通过对历史数据和实时数据的分析,预测未来的生产趋势和可能出现的风险,交叉熵在预测分析中可以帮助企业评估不同预测方案的可靠性和准确性,从而做出更科学的决策。 2026年居家养老与社区公益热度持续上升,相关产业迎来新机遇
在市场预测方面,2026年,一家化工企业利用数字孪生平台对其产品的市场需求进行预测,该平台收集了历史销售数据、市场动态信息、宏观经济数据等多源数据,构建了多个不同的市场需求预测模型。

为了评估这些模型的预测效果,企业使用交叉熵对每个模型的预测结果与实际市场需求进行对比,通过比较不同模型的交叉熵值,企业选择了交叉熵最小的模型作为最终的预测模型,根据该模型的预测结果,企业合理安排了生产计划,避免了库存积压和缺货现象的发生,提高了企业的经济效益。
在生产过程优化方面,交叉熵同样发挥着重要作用,一家食品加工企业利用数字孪生平台对其生产流程进行优化,该平台通过模拟不同的生产参数组合,预测产品的质量和生产效率,在模拟过程中,使用交叉熵评估不同参数组合下预测结果与实际生产情况的差异,选择交叉熵最小的参数组合作为最优方案。
通过实施该最优方案,该企业的产品合格率提高了15%,生产效率提高了10%,实现了生产过程的优化和升级。
尽管交叉熵在工业数字孪生平台中发挥着重要作用,但在实际应用中也面临着一些挑战,交叉熵的计算需要大量的高质量数据作为支撑,而工业生产中的数据往往存在噪声和缺失值,这会影响交叉熵计算的准确性和可靠性,交叉熵的应用需要专业的数学知识和算法技能,对企业的技术人员提出了较高的要求。
随着人工智能、大数据、物联网等技术的不断发展,这些问题将逐步得到解决,交叉熵有望在工业数字孪生平台中发挥更大的作用,推动工业生产向智能化、数字化、绿色化方向发展。
通过结合深度学习和交叉熵优化算法,可以构建更加精确和可靠的数字孪生模型,实现对工业生产的实时监测和精准控制,交叉熵还可以与其他数学方法和工具相结合,如贝叶斯网络、模糊逻辑等,进一步提高数字孪生平台的性能和功能。
本月绿色冷能与社会责任及健康中国热度持续上升,相关领域迎来新发展 在2026年及未来的工业领域,数字孪生平台将成为企业提升竞争力的核心工具,而交叉熵作为背后的数学魔法,将继续为数字孪生技术的发展和应用提供强大的支持,助力工业生产迈向新的高度。