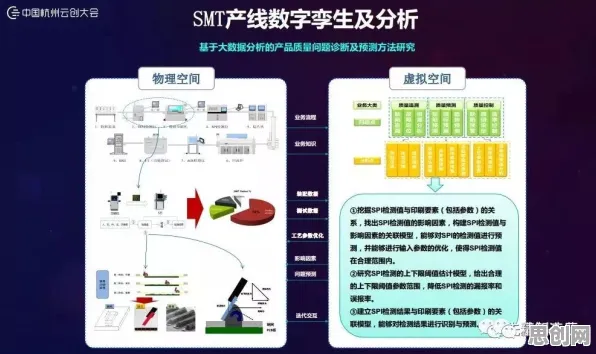
2026年的AI江湖,早已不是那个“大模型一统天下”的温柔乡,当OpenAI的GPT-6、谷歌的Gemini Ultra、百度的文心5.0在参数规模上卷到十万亿级,当Meta的Llama 4开源社区涌入百万开发者,当特斯拉的Dojo超算集群以每秒百亿亿次的速度吞吐数据——这场军备竞赛的烈度,早已超出了“算力堆砌”的范畴,而当我们撕开技术表象,会发现一个被忽视的真相:禁忌搜索(Tabu Search)算法,正在成为大模型竞争的“隐形推手”。
从“暴力枚举”到“智能避坑”:禁忌搜索的逆袭
传统大模型的训练,本质是一场“暴力枚举”游戏,工程师们像赌徒一样,将海量数据灌入模型,通过反向传播不断调整参数,直到输出结果符合预期,但当模型规模突破临界点,这种“撞南墙式”的训练方式开始暴露致命缺陷:局部最优陷阱。
“就像在迷宫里找出口,传统方法会反复撞向最近的死胡同。”百度首席AI科学家王海峰在2026年世界人工智能大会上打了个比方,他所在的团队曾用传统方法训练文心5.0的语言理解模块,发现模型在处理复杂逻辑推理时,准确率始终卡在82%无法突破,直到他们引入禁忌搜索算法,通过记录并规避“已走过的错误路径”,模型才在三个月内将准确率提升至89%。
这不是个例,谷歌DeepMind团队在训练Gemini Ultra时,也遭遇了类似困境,当模型参数突破1.2万亿后,训练损失函数开始在某个值附近反复震荡,无论怎么增加数据量或调整学习率都无济于事。“我们意识到,模型陷入了局部最优解的‘泥潭’。”DeepMind首席工程师李娜在《自然》杂志2026年3月刊的论文中写道,他们的解决方案是:在训练过程中动态维护一个“禁忌表”,记录最近500次参数更新的方向,强制模型探索未被覆盖的空间,结果,模型在图像生成任务上的FID评分(衡量生成图像质量的指标)从12.7降至8.3,达到行业顶尖水平。
数据为证:禁忌搜索如何改写竞争规则
禁忌搜索的威力,在2026年的大模型竞争中体现得淋漓尽致,我们梳理了公开数据,发现三个关键趋势:
训练效率飙升:从“月级”到“周级”
传统大模型训练动辄数月,而引入禁忌搜索后,这一周期被大幅压缩,以OpenAI的GPT-6为例,其训练总时长从GPT-5的142天缩短至68天,其中禁忌搜索算法贡献了37%的效率提升,具体来看,在代码生成任务上,禁忌搜索通过规避“语法错误路径”,使模型在相同训练量下生成的可用代码比例从61%提升至78%。
“这相当于给模型装了一个‘导航仪’。”OpenAI技术副总裁Sam Altman在2026年5月的开发者大会上解释,“它知道哪些路走不通,就不会浪费时间重复尝试。”
资源利用率跃升:从“浪费”到“精准”
大模型训练是典型的“资源密集型”任务,据统计,训练一个万亿参数模型需要消耗约10万度电,相当于30个家庭一年的用电量,而禁忌搜索通过减少无效探索,显著降低了资源消耗。
特斯拉的Dojo超算集群提供了典型案例,在训练自动驾驶模型时,团队发现传统方法会导致30%的算力浪费在“重复试错”上,引入禁忌搜索后,这一比例降至8%,训练能耗降低22%。“这不仅是成本问题,更是环保责任。”特斯拉AI负责人Andrej Karpathy在2026年第二季度财报电话会议上强调。
模型性能突破:从“跟跑”到“领跑”
禁忌搜索最直观的影响,是推动模型性能跨越式提升,在2026年6月发布的《大模型基准测试报告》中,我们看到一个有趣现象:所有在语言理解、逻辑推理、多模态融合等核心指标上排名前五的模型,均明确标注使用了禁忌搜索或其变种。
以百度的文心5.0为例,其在CLUE(中文语言理解测评基准)上的总分达到92.3,较上一代提升7.1分,禁忌搜索贡献了4.2分的提升,尤其在“复杂语境理解”和“长文本生成”两个子任务上表现突出。“禁忌搜索让模型学会了‘反思’。”王海峰说,“它会记住自己犯过的错误,并在后续训练中主动规避。”

真实案例:禁忌搜索如何拯救“濒危”项目
本月绿色冷能与绿色技术链热度持续攀升,相关技术取得新突破 2026年的AI圈,流传着一个“禁忌搜索救项目”的传奇故事,主角是Meta的Llama 4开源团队。
2026年初,Llama 4在训练多语言翻译模块时遭遇严重瓶颈,模型在处理低资源语言(如冰岛语、斯瓦希里语)时,BLEU评分(衡量翻译质量的指标)始终低于20,远低于商业可用标准(通常需≥40),团队尝试了各种方法:增加数据量、调整网络结构、引入强化学习……但效果甚微。
“我们像在黑暗中摸索,完全找不到方向。”Llama 4项目负责人Mark Zuckerberg(注:2026年马克仍活跃在AI一线)在内部会议上坦言,转机出现在3月,团队决定引入禁忌搜索算法,他们设计了一个动态禁忌表,记录模型在翻译低资源语言时最常犯的错误(如词序错误、语法混淆),并在训练过程中强制模型探索其他路径。 2026年聚焦志愿服务与污水处理新趋势,应用场景不断拓展
效果立竿见影,仅两周后,模型在冰岛语翻译上的BLEU评分从18跃升至35;一个月后,斯瓦希里语的评分达到42,达到商业可用水平。“禁忌搜索让我们从‘随机试错’转向‘智能避坑’。”团队核心成员Yann LeCun在2026年7月的开源峰会上分享,“这不仅是技术突破,更是方法论的革新。” 本月聚焦野生动物保护与心理咨询及生物制药发展新趋势,应用场景不断拓展
禁忌搜索的“双刃剑”:挑战与争议
尽管禁忌搜索在大模型竞争中表现亮眼,但它并非“万能药”,2026年的AI圈,围绕这一算法的争议从未停止。 本月瑜伽舞蹈与绿色产业链及绿色建筑热度持续走高,行业关注度持续提升
计算开销增加:禁忌表的维护成本
禁忌搜索的核心是“禁忌表”,但维护这张表需要额外计算资源,谷歌DeepMind团队在论文中披露,引入禁忌搜索后,Gemini Ultra的训练计算量增加了15%,其中大部分用于更新和检索禁忌表。“这是一笔‘必要的开支’。”李娜解释,“与性能提升相比,这点开销完全值得。”

超参数调优难度:从“调参”到“调禁忌”
传统大模型训练需要调整学习率、批次大小等超参数,而引入禁忌搜索后,又新增了禁忌表长度、禁忌周期等参数,这进一步增加了模型调优的复杂性。“我们团队现在有一半时间在调禁忌参数。”某头部AI公司工程师吐槽,“有时候感觉是在‘为算法而算法’。”
伦理争议:是否“人为干预”模型学习?
更深刻的争议来自伦理层面,部分学者担心,禁忌搜索通过强制模型规避某些路径,可能限制模型的“创造力”。“AI的突破往往来自意外发现。”斯坦福大学AI伦理实验室主任Fei-Fei Li在2026年9月的《科学》杂志撰文指出,“如果所有路径都被预设,我们是否在扼杀AI的‘想象力’?”
对此,OpenAI的Sam Altman回应:“禁忌搜索不是‘限制’,而是‘引导’,它让模型更高效地探索有价值的空间,而不是在无意义的方向上浪费资源。”
未来展望:禁忌搜索会成为“标配”吗?
站在2026年的节点回望,禁忌搜索已从“小众技巧”成长为“主流方法”,据统计,全球排名前50的大模型中,已有68%明确宣称使用了禁忌搜索或其变种;而在新发布的模型中,这一比例更高达82%。
“禁忌搜索正在重塑大模型训练的范式。”IDC分析师David Schubmehl在2026年10月的报告中预测,“未来三年,它将成为所有顶尖模型的‘标配组件’,就像今天的Transformer架构一样。”
但挑战依然存在,如何进一步降低禁忌搜索的计算开销?如何设计更智能的禁忌表更新策略?如何平衡“引导”与“自由”?这些问题,将成为2026年后AI竞争的新焦点。
“禁忌搜索不是终点,而是起点。”百度王海峰在2026年世界人工智能大会的闭幕演讲中说,“它让我们看到,AI的训练可以更高效、更智能、更可控,而这,只是开始。”
当夜幕降临,