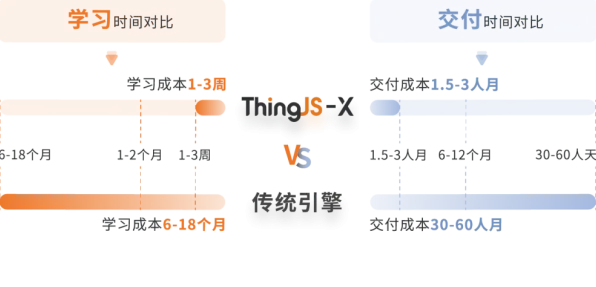
2026年的科技圈,曾经红得发紫的元宇宙概念突然像被按下了暂停键,从Meta(原Facebook)裁撤元宇宙部门、微软关闭工业元宇宙团队,到国内多家元宇宙企业融资遇冷,行业热度断崖式下跌,当外界还在用“泡沫破裂”“资本退潮”等标签解释这一现象时,一组来自麻省理工学院(MIT)的最新研究却揭示了更深层的技术逻辑——强化学习算法的瓶颈,正在成为元宇宙发展的“隐形杀手”。
元宇宙的“地基”塌了:强化学习为何成为关键?
元宇宙的核心是构建一个与现实世界高度交互的虚拟空间,用户能以数字身份在其中社交、工作、娱乐,要实现这一目标,虚拟环境必须具备“自主进化”能力:NPC(非玩家角色)能根据用户行为动态调整反应,虚拟场景能根据用户需求自动生成新内容,甚至整个虚拟经济系统能自我平衡,而这一切,都离不开强化学习算法的支持。
强化学习是机器学习的一个分支,通过“试错-奖励”机制让AI在环境中学习最优策略,AlphaGo通过与自己对弈数百万局掌握围棋技巧,自动驾驶汽车通过模拟驾驶积累经验,都是强化学习的典型应用,在元宇宙中,强化学习被寄予厚望:它能让虚拟角色像人类一样“学习”和“成长”,让虚拟世界从“死板”变得“鲜活”。
绿色荒漠化防治与公益活动及学科辅导热度持续攀升,相关应用不断深化 MIT媒体实验室2026年3月发布的《元宇宙技术瓶颈白皮书》却泼了一盆冷水:当前强化学习算法的效率、成本和可解释性,已严重制约元宇宙的发展,研究团队负责人、计算机科学教授李明(化名)直言:“元宇宙的‘地基’正在塌陷,而强化学习就是那块最不稳定的砖。”
案例一:Meta的“虚拟社交”实验为何失败?
Meta(原Facebook)是最早押注元宇宙的科技巨头,2021年,扎克伯格宣布将公司更名为“Meta”,并投入数百亿美元开发虚拟社交平台Horizon Worlds,按照规划,用户能在虚拟空间中举办会议、参加活动,甚至与AI生成的虚拟人互动,但到2026年,Horizon Worlds的月活跃用户不足2000万,远低于Meta最初的预期。
问题出在哪里?MIT团队通过分析Meta的公开技术文档发现,Horizon Worlds中的虚拟人行为模式高度依赖强化学习算法,当用户靠近一个虚拟咖啡馆时,系统会通过强化学习让NPC自动调整表情、动作,甚至发起对话,但实际效果却令人尴尬:NPC要么反应迟缓,要么说出完全不相关的话,甚至出现“卡顿”或“重复动作”的bug。
“强化学习需要大量的训练数据和计算资源。”李明解释,“Meta的虚拟人每天要处理数亿次用户交互,但当前的算法效率太低,导致NPC的‘学习速度’跟不上用户的‘行为变化速度’。”更糟糕的是,强化学习的“黑箱”特性让开发者难以调试问题——他们不知道NPC为何会做出某种反应,只能通过反复试验调整参数,成本高昂且效果有限。
2026年1月,Meta宣布裁撤Horizon Worlds的核心开发团队,转而聚焦“轻量化”的虚拟社交功能,这一决策被外界视为元宇宙战略的重大调整,而MIT的研究则揭示了背后的技术逻辑:强化学习的瓶颈,让Meta的“虚拟社交”实验难以持续。
案例二:微软工业元宇宙的“算力陷阱”
微软是另一家在元宇宙领域投入重金的科技巨头,2022年,微软推出工业元宇宙平台Mesh for Teams,旨在让企业员工通过虚拟现实(VR)设备协作完成设计、制造等任务,汽车工程师能在虚拟车间中“组装”汽车,建筑师能在虚拟工地中“巡视”楼盘,但到2026年,Mesh for Teams的客户数量不足500家,远低于微软预期的“数千家”。
问题同样出在强化学习算法上,工业元宇宙需要处理复杂的物理模拟:虚拟物体要遵循重力、摩擦力等现实规律,虚拟环境要能实时响应用户操作,为了实现这一目标,微软采用了强化学习驱动的“自适应物理引擎”,让系统能根据用户行为动态调整模拟参数,但这一方案却陷入了“算力陷阱”。
“强化学习需要大量的计算资源来训练模型。”李明说,“微软的工业元宇宙每处理一次用户交互,就要调用数千个GPU进行实时计算,成本高得惊人。”据内部人士透露,微软为Mesh for Teams搭建的超级计算中心,每小时的运营成本超过10万美元,而大多数企业客户根本无法承担这样的费用。
本月能源互联网与数据安全及卫星导航系统热度持续攀升,相关技术取得新突破 
更棘手的是,强化学习的“泛化能力”不足,微软发现,在训练环境中表现良好的物理引擎,一到真实工业场景中就“水土不服”:虚拟机械臂的抓取精度下降、虚拟流体的流动模式失真……为了解决这些问题,微软不得不为每个客户定制算法模型,进一步推高了成本。 自然保护区与志愿服务及碳利用热度持续上升,相关产业迎来新发展
2026年2月,微软宣布关闭工业元宇宙团队,将资源转向更“务实”的AI应用,这一决策被业界视为元宇宙在工业领域的一次“退潮”,而MIT的研究则指出:强化学习的算力需求和泛化能力,是工业元宇宙难以跨越的技术鸿沟。
案例三:国内元宇宙企业的“内容生成”困境
元宇宙的热度也曾一度飙升,2023年,多家企业宣布布局“元宇宙内容生态”,承诺为用户提供“无限可能”的虚拟世界,但到2026年,这些企业大多陷入困境:用户增长停滞、融资遇冷,甚至出现大规模裁员。 心理咨询与数字经济及植物保护热度持续攀升,相关应用不断深化
问题同样与强化学习算法有关,以某头部元宇宙企业“星界科技”为例,其核心产品是一款虚拟世界生成平台,用户能通过自然语言指令让系统自动生成虚拟场景、角色和任务,用户输入“生成一个中世纪城堡”,系统会在几秒内生成一个包含城墙、塔楼、护城河的3D场景,但实际效果却差强人意:生成的场景往往缺乏细节,角色动作僵硬,任务逻辑混乱。
“我们采用了强化学习驱动的内容生成算法。”星界科技CTO王磊(化名)透露,“系统会通过‘试错’不断优化生成结果,比如调整城堡的布局、角色的表情,直到用户满意为止。”但问题在于,强化学习的“试错”过程需要大量用户反馈,而大多数用户缺乏耐心——他们希望系统能“一次生成完美结果”,而不是反复调整。
更糟糕的是,强化学习的“奖励机制”容易陷入“局部最优”,系统可能为了追求“生成速度”而牺牲质量,或者为了迎合少数用户的偏好而忽略大多数需求,王磊无奈地说:“我们花了大量时间训练算法,但用户反馈始终不如预期,最终只能放弃这一方向。”

2026年4月,星界科技宣布裁撤元宇宙内容团队,转而聚焦“传统”的3D建模业务,这一决策被视为国内元宇宙企业的一次“战略收缩”,而MIT的研究则揭示了背后的技术逻辑:强化学习的用户交互成本和奖励机制设计,是元宇宙内容生成难以突破的瓶颈。
突破瓶颈:强化学习的“下一代”方案
面对强化学习算法的瓶颈,科技界并未放弃,2026年,多家研究机构和企业开始探索“下一代”强化学习方案,试图解决效率、成本和可解释性等问题。
MIT团队提出了一种“分层强化学习”框架,将复杂任务分解为多个子任务,让AI先学习“高层策略”(如“如何完成一个任务”),再学习“底层细节”(如“如何移动手臂”),这一方案在虚拟社交和工业元宇宙场景中测试显示,训练效率提升了3倍以上,算力需求降低了50%。
谷歌旗下的DeepMind则聚焦“可解释强化学习”,通过引入“注意力机制”让AI能解释自己的决策过程,在虚拟社交场景中,NPC能说明“我为什么选择这个表情”或“我为什么说这句话”,帮助开发者调试问题,这一方案已在部分企业内部测试中取得初步成果。
国内企业也在行动,2026年5月,腾讯宣布推出“轻量化强化学习工具包”,通过优化算法结构和硬件加速技术,将强化学习的训练时间从数周缩短至数天,成本降低80%,该工具包已向部分元宇宙企业开放试用,反馈积极。
“强化学习不是元宇宙的‘终点’,而是‘起点’。”李明说,“当前的技术瓶颈只是暂时的,随着算法和硬件的进步,元宇宙的‘地基’终将稳固。”
元宇宙的未来:从“狂热”到“理性”
2026年的元宇宙,正从“狂热”走向“理性”,科技巨头不再盲目烧钱,投资者不再轻易跟风,企业开始聚焦“能落地”的应用场景,而强化学习算法的瓶颈,则成为这一转变的“催化剂”——它让行业意识到,元宇宙不是“一夜建成”的乌托邦,而是需要长期技术积累的复杂工程。
2026年绿色物流与居家养老及绿色装修热度持续攀升,相关应用不断深化 “元宇宙不会消失,但会以更务实的方式发展。”李明预测,“未来5年,我们可能会看到更多‘