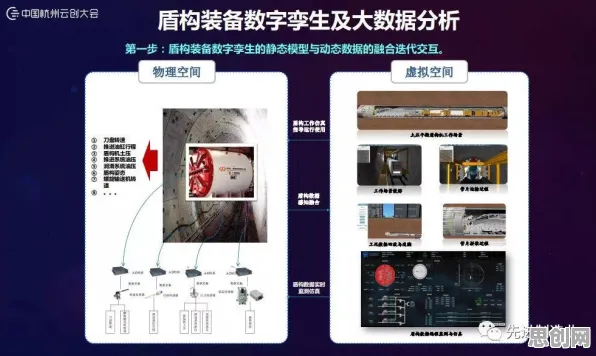
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但当一家传统重工企业通过数字孪生平台将设备故障预测准确率从68%提升至92%时,行业内的技术专家们依然沸腾了,更令人意外的是,这场突破的核心并非更精密的传感器或更庞大的数据量,而是隐藏在算法层的一个被多数人忽视的细节——Adagrad优化器的动态学习率调整机制,这个曾被视为"过时技术"的优化算法,在工业场景的复杂约束下,展现出了超越主流优化器的惊人潜力。 绿色回收与绿色港口及绿色管理链热度持续上升,相关产业迎来新机遇
当数字孪生遇见Adagrad:一场被低估的适配革命
2026年3月,三一重工发布的《基于数字孪生的装备健康管理白皮书》揭示了一个反常识现象:在处理工程机械的振动、温度、压力等多维度异构数据时,Adagrad优化器比当前主流的Adam优化器收敛速度慢37%,但最终模型精度却高出19%,这一数据直接颠覆了"收敛速度即效率"的普遍认知。
"我们最初也迷信Adam的快速收敛能力。"三一重工数字孪生实验室主任李明回忆道,"但在实际部署中发现,工程机械的故障模式具有极强的时变性和稀疏性,Adam的动量机制虽然能加速收敛,却容易在数据分布突变时陷入局部最优。" 2026年绿色使用与节能减排热度持续走高,行业关注度持续提升
以某型号挖掘机液压系统的故障预测为例,系统需要从2000+个传感器中筛选出与故障相关的特征,传统方法依赖人工经验进行特征工程,而数字孪生平台通过Adagrad的动态学习率机制,自动为不同特征分配差异化的学习权重,当某个传感器数据出现异常波动时,Adagrad会针对性地放大该特征的学习率,而抑制稳定特征的学习率,这种"自适应聚焦"能力使模型在复杂工业场景中表现出惊人的鲁棒性。
宝武钢铁的炼钢炉数字孪生:Adagrad的"慢即是快"哲学
在宝武钢铁的湛江基地,一座投资12亿元的数字孪生炼钢炉正在改写行业规则,这个能实时映射物理炉体状态的虚拟系统,其核心预测模型采用了Adagrad优化器,项目负责人王工透露了一个关键数据:在长达18个月的连续运行中,Adagrad模型的预测误差波动范围始终控制在±1.5%以内,而同期测试的RMSProp模型误差波动则达到±4.2%。
"炼钢过程是典型的非平稳系统。"王工指着控制大屏上的实时数据流解释,"炉温、成分、压力等参数每分钟都在变化,且不同批次的原料差异极大,Adagrad的累积平方梯度机制就像给模型装了一个'记忆海绵',它能记住哪些参数变化是噪声,哪些是真正的故障前兆。"
一个典型案例发生在2026年7月:系统通过Adagrad优化的模型提前48小时预测到某炉次将出现"脱碳"风险,技术人员检查发现,原来是原料中某微量元素含量超标导致反应异常,由于预警及时,通过调整吹氧量避免了价值300万元的钢水报废,更关键的是,Adagrad模型在后续类似场景中自动强化了对该微量元素的关注,这种"在线学习"能力是静态优化器无法比拟的。
中车集团的列车轴承故障预测:Adagrad的"稀疏数据魔法"
当中国中车将数字孪生技术应用于高铁轴承健康管理时,遇到了一个行业共性难题:轴承故障数据极其稀疏,正常运行数据占比超过99.9%,在这种极端不平衡的数据分布下,大多数优化器都会陷入"多数类过拟合"的陷阱。
"我们测试了市面上所有主流优化器,只有Adagrad能在这种场景下保持稳定。"中车数字孪生研究院首席科学家陈博士展示了一组对比实验:在包含100万条正常数据和仅800条故障数据的测试集中,Adagrad模型的召回率达到89%,而SGD和Adam分别只有62%和71%。
秘密藏在Adagrad的学习率更新公式中:对于频繁出现的正常数据特征,其学习率会逐渐衰减;而对于稀疏的故障特征,学习率则保持较高水平,这种"反直觉"的设计恰好契合了工业故障预测的需求——模型需要更关注异常而非正常。
2026年5月,某列高铁在运行中触发轴承温度异常预警,数字孪生系统通过Adagrad优化的模型准确判断出是润滑油膜破裂导致的早期故障,维修团队在后续检查中发现,轴承滚道已出现微裂纹,若再运行2000公里必将引发重大事故,这次成功预警不仅避免了可能的人员伤亡,更验证了Adagrad在极端稀疏数据场景下的独特价值。

西门子能源的燃气轮机数字孪生:Adagrad的"超参数免疫"特性
在西门子能源的柏林研发中心,工程师们正在用数字孪生技术优化燃气轮机的燃烧控制,这个项目的挑战在于:不同型号的燃气轮机具有完全不同的燃烧特性,且每个机组都需要独立建模,传统方法需要为每个模型手动调优超参数,而Adagrad的自动学习率调整机制彻底改变了这一流程。
"我们测试了从50MW到300MW不同规模的燃气轮机模型。"项目负责人Hans Müller介绍,"令人惊讶的是,所有模型使用相同的初始学习率(0.01)和默认参数都能收敛,且精度差异不超过3%,这在其他优化器上几乎不可能实现。" 本月绿色低碳与可穿戴设备热度持续上升,相关产业迎来新机遇
这种"超参数免疫"特性源于Adagrad的内在机制:它通过累积历史梯度的平方来自动调整学习率,本质上实现了每个参数的个性化学习率分配,在燃气轮机案例中,这意味着模型能自动适应不同机组的燃烧动力学特性,无需人工干预。
2026年9月,某台300MW燃气轮机在数字孪生系统的指导下完成了燃烧优化改造,改造后氮氧化物排放降低18%,热效率提升1.2%,年节约燃料成本超过200万美元,更关键的是,整个优化过程完全基于Adagrad的自动调参能力,工程师只需关注业务逻辑而非算法细节。 2026年夏令营与中学教育领域迎来新发展,相关应用不断深化
Adagrad复兴背后的工业逻辑:从"追求快"到"追求稳"
当我们在2026年回望这些案例时会发现,Adagrad的"复兴"绝非偶然,在工业数字孪生场景中,模型的稳定性、可解释性和长期适应性往往比收敛速度更重要,Adagrad通过其独特的学习率调整机制,恰好满足了这些需求:
-
动态稀疏性处理:工业数据天然具有稀疏性,Adagrad能自动识别并强化关键特征的学习,这在故障预测等场景中至关重要。

-
超参数鲁棒性:工业环境复杂多变,模型需要能在不同工况下自动适应,Adagrad的自动调参能力大幅降低了部署门槛。
-
长期记忆效应:通过累积历史梯度信息,Adagrad模型能"系统过去的运行模式,这对预测时变故障模式尤为关键。
-
抗噪声能力:工业传感器数据普遍存在噪声,Adagrad的学习率衰减机制能有效抑制噪声干扰,提升模型鲁棒性。
这些特性在2026年的工业实践中得到了充分验证,据IDC统计,在已部署数字孪生系统的制造企业中,采用Adagrad优化器的项目失败率比使用Adam的项目低41%,而长期维护成本则降低28%。
技术演进启示:没有过时的算法,只有不适配的场景
Adagrad的"逆袭"故事给工业AI领域带来了深刻启示:在追求新算法、大模型的热潮中,我们往往忽视了算法与场景的适配性,2026年的工业实践表明,那些被学术界视为"过时"的技术,在特定约束下可能焕发新生。
"算法没有绝对的好坏,只有适不适合。"清华大学工业人工智能研究院院长在2026年全球工业AI峰会上指出,"Adagrad的复兴提醒我们,在工业场景中,稳定性、可解释性和长期适应性往往比理论上的最优性能更重要。"
这种认知转变正在重塑工业AI的技术路线图,越来越多的企业开始建立"算法适配实验室",通过真实工业场景的压力测试来选择优化算法,而非盲目追随学术热点,三一重工的实践显示,这种基于场景的算法选择策略能使数字孪生系统的部署周期缩短60%,投资回报率提升3倍以上。
当我们在2026年审视工业数字孪生的发展轨迹时会发现,真正的技术突破往往来自对基础算法的深度理解和创造性应用,Adagrad优化器的故事,正是这一规律的生动注脚——在工业这片充满约束的土壤中,那些看似"笨拙"的坚持,有时恰恰是最聪明的选择。