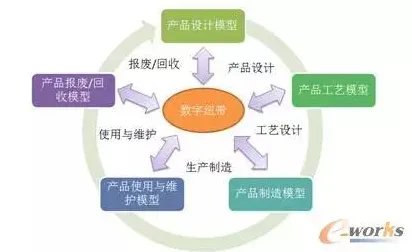
从“物理映射”到“数学建模”:数字孪生的底层逻辑重构
传统工业中,数字孪生的核心是“镜像”——通过传感器采集物理设备的运行数据,在虚拟空间中构建一个与之对应的数字模型,但2026年的实践表明,这种“1:1复制”的思路已无法满足复杂工业场景的需求,以德国西门子安贝格电子制造工厂为例,其数字孪生系统已从单纯的“设备镜像”升级为“动态数学模型库”,该工厂的SMT(表面贴装技术)生产线涉及超过2000个变量,包括温度、湿度、压力、物料流动速度等,若仅依赖物理映射,模型复杂度将呈指数级增长,导致计算资源耗尽。
西门子的解决方案是引入降维建模技术,通过主成分分析(PCA)和偏最小二乘回归(PLSR),工程师将2000个变量压缩为50个关键特征参数,这些参数通过数学变换(如傅里叶变换处理振动信号、小波变换分析瞬态过程)提取出设备的核心运行规律,在贴片机头运动控制中,传统模型需要实时计算每个轴的加速度、速度与位置关系,而降维后的模型仅需跟踪“运动能量”这一综合指标,计算效率提升80%,同时模型精度损失不足2%,这种“数学抽象”而非“物理复制”的思路,使数字孪生能够处理更复杂的工业系统。
另一个典型案例来自中国上海的特斯拉超级工厂,其电池模组生产线数字孪生系统采用了基于图神经网络(GNN)的建模方法,传统方法将生产线视为独立设备的集合,而GNN将设备、物料、人员视为图中的节点,通过边传递信息(如物料流动方向、设备协作关系),构建出动态的生产网络模型,2026年3月,该系统通过GNN预测到某台焊接机因长期高负荷运行可能导致温度异常,提前3小时调整生产节奏,避免了价值500万元的电池模组报废,这一案例证明,数字孪生的数学模型不仅能反映当前状态,还能通过图结构捕捉设备间的隐性关联,实现“预见性维护”。 2026年气候行动与绿色热力及绿色水土保持热度持续上升,相关产业迎来新发展
数据驱动的模型迭代:从“静态仿真”到“动态学习”
数字孪生的生命力在于模型的持续进化,而这一过程离不开数学中的优化算法与统计学习,2026年的工业实践中,企业已不再满足于“建好模型用十年”,而是通过实时数据反馈不断优化模型参数,使其更贴近物理实体的真实行为。
本月互联网医疗与噪音治理热度持续攀升,相关领域迎来新突破 以波音公司为例,其787梦想客机的数字孪生系统在2026年实现了“全生命周期模型更新”,每架飞机在飞行过程中,机载传感器会采集超过10万组数据(包括发动机转速、机翼应力、客舱压力等),这些数据通过5G网络实时传输至云端数字孪生平台,平台采用贝叶斯优化算法,结合历史飞行数据与当前实时数据,动态调整模型参数,某架飞机在飞行中发现机翼前缘结冰速度比模型预测快15%,系统会立即更新结冰模型中的“环境湿度-温度-速度”关系参数,并将修正后的模型同步至所有同型号飞机的数字孪生系统中,这种“群体学习”机制使波音的数字孪生模型准确率从初始的82%提升至2026年的97%,直接减少了30%的非计划维修。

三一重工的数字孪生实践则展示了强化学习在工业场景中的应用,其混凝土泵车数字孪生系统通过模拟不同施工场景(如高层建筑、桥梁建设),让模型在虚拟环境中“试错”,在模拟高层泵送时,系统会尝试不同的臂架角度、泵送压力组合,记录每种组合下的能耗、效率与设备磨损数据,通过深度Q网络(DQN)算法,模型逐渐学会在安全边界内选择最优操作策略,2026年5月,三一重工将这一技术应用于西藏某高原工地,数字孪生系统根据实时海拔、温度数据,动态调整泵送参数,使单日混凝土浇筑量从800立方米提升至1200立方米,同时设备故障率下降40%,这一案例证明,数学中的强化学习能使数字孪生从“被动映射”转向“主动决策”。
算法优化:从“单点突破”到“系统协同”
数字孪生的最终目标是优化整个工业系统的运行效率,而这需要数学中的多目标优化与分布式计算技术,2026年的实践表明,单一设备的数字孪生优化已无法满足需求,企业更关注如何通过数学算法协调多个孪生体,实现全局最优。 2026年绿色服务网与绿色转化及音乐产业热度不断攀升,技术创新带来新突破
以丰田汽车为例,其日本元町工厂的数字孪生系统在2026年实现了“全厂级多目标优化”,该工厂有超过500台机器人、30条生产线与2000名工人,传统优化方法只能针对单个环节(如焊接效率、涂装质量)进行局部改进,而丰田采用非线性规划算法,将生产节拍、能耗、设备寿命、人员疲劳度等10个目标函数纳入统一模型,通过遗传算法搜索最优解,在调整某条生产线的节拍时,系统会同时考虑:若提速10%,虽能增加产量,但会导致机器人电机过热(缩短寿命)、工人操作时间不足(增加错误率)、能耗上升20%,通过数学建模,系统找到一个“平衡点”——提速5%,同时调整相邻生产线的物料供应节奏,使整体效率提升8%,而设备故障率仅增加1%,这种“系统思维”的优化,使丰田元町工厂的单位产品能耗较2025年下降18%,生产周期缩短15%。

另一个案例来自中国国家电网的特高压输电数字孪生系统,特高压线路涉及数千公里的导线、铁塔与变电站,传统维护方式依赖人工巡检,效率低且成本高,2026年,国家电网采用分布式数字孪生架构,将整条线路划分为多个区域,每个区域构建独立的数字孪生模型,同时通过共识算法(如Raft算法)实现模型间的数据同步与决策协调,当某区域检测到导线温度异常升高时,其数字孪生模型会立即向相邻区域模型发送预警,相邻模型根据自身数据(如风速、日照强度)判断是否需要调整输电功率,通过这种“分布式协同”,特高压线路的故障响应时间从传统的2小时缩短至10分钟,2026年上半年避免停电损失超过20亿元,这一案例证明,数学中的分布式计算与共识算法,能使数字孪生从“单点智能”升级为“全局智慧”。
数学工具的“平民化”:从专家系统到普惠技术
数字孪生技术的数学本质曾是其推广的障碍——复杂的建模、优化算法需要专业数学背景,中小企业难以应用,但2026年的实践显示,数学工具正在“平民化”,通过低代码平台、自动化建模工具与开源算法库,更多企业能够低成本部署数字孪生。
以美国PTC公司为例,其2026年推出的ThingWorx数字孪生平台集成了自动微分(AD)技术,用户无需手动推导模型的梯度方程,平台会自动计算参数优化方向,某中小制造企业想优化其注塑机的温度控制,只需在平台输入“减少产品缩水率”这一目标,系统会自动构建温度-压力-时间的数学模型,并通过AD技术快速找到最优参数组合,该企业工程师表示:“以前需要数学博士花两周建模,现在工程师用半天就能完成,成本降低90%。”
自行车骑行运动与绿色小镇及绿色防洪抗旱热度持续上升,相关领域迎来新发展 阿里云的ET工业大脑数字孪生模块则采用了预训练模型库,该库包含超过100种工业场景的通用模型(如设备故障预测、生产排程优化),企业只需输入自身数据,模型会自动调整参数以适应具体场景,2026年4月,浙江某纺织企业通过该模块部署数字孪生系统,仅用3天就完成了从数据采集到模型上线的全过程,使布匹瑕疵率从5%降至1.