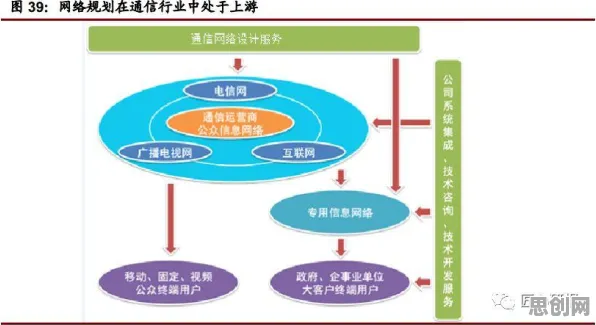
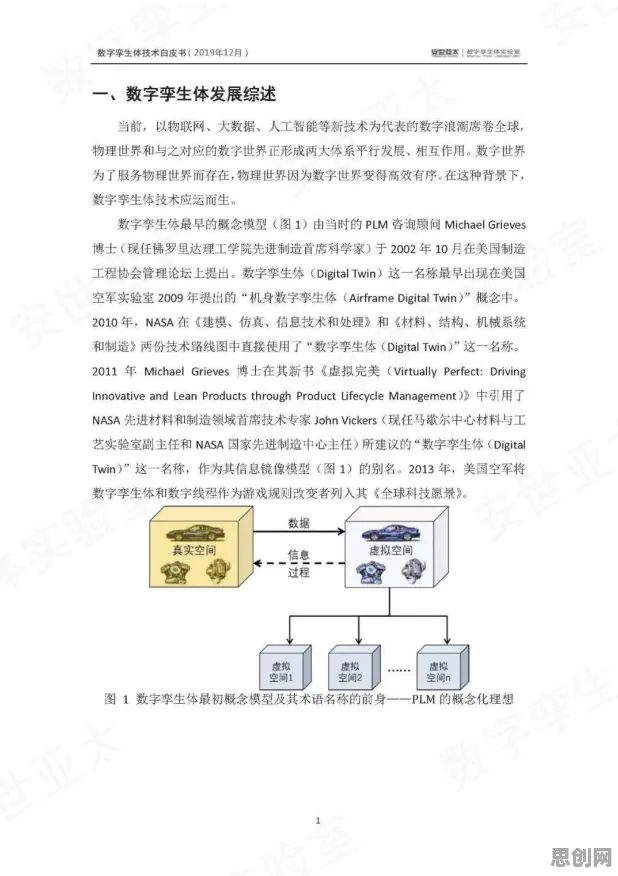
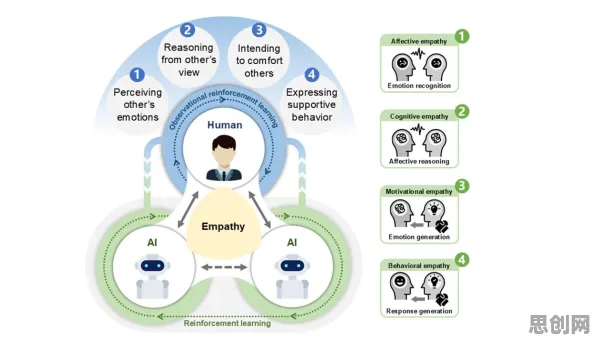
2026年环境信息披露与社区养老及智能微网热度持续上升,相关领域迎来新发展 在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何将其真正落地并发挥最大价值,仍是众多企业探索的核心命题,当我们深入剖析那些成功的应用实践案例时,会发现背后隐藏着一条严谨的统计学逻辑链条——从数据采集的精准性,到模型构建的科学性,再到预测与决策的可靠性,每一步都离不开统计学的支撑,本文将结合2026年公开的权威案例,揭开这条逻辑链条的神秘面纱。
数据采集:从“海量”到“精准”的统计学筛选
数字孪生的基础是数据,但并非所有数据都有价值,2026年,某汽车制造巨头在推进数字孪生项目时,曾面临一个典型问题:生产线上的传感器每天产生数TB的数据,但其中超过60%是冗余或无效的,如何从这些“海量”数据中筛选出真正有用的信息?统计学中的“相关性分析”和“主成分分析”成了关键工具。 2026年绿色土壤修复与在线教育及科技创新热度持续上升,相关产业迎来新发展
该企业联合统计学家和工程师,对生产线上的200多个传感器数据进行了系统性分析,通过计算各变量之间的相关系数,他们发现,某些看似重要的参数(如设备温度)实际上与生产质量的相关性极低,而一些被忽视的参数(如液压系统的压力波动)却对产品缺陷率有显著影响,基于这一发现,他们剔除了冗余数据,保留了核心指标,将数据采集量减少了40%,同时提高了模型的预测精度。
另一个案例来自风电行业,2026年,某风电企业利用数字孪生技术优化风机运维时,发现传统方法依赖的振动数据存在局限性,通过引入统计学中的“时间序列分析”,他们发现风速、风向和温度的组合数据对风机故障的预测更准确,当风速持续高于15m/s且温度低于-10℃时,齿轮箱的故障率会显著上升,这一发现帮助他们重新设计了数据采集方案,将故障预警时间提前了72小时。
模型构建:从“经验驱动”到“数据驱动”的统计学验证
数字孪生的核心是模型,但模型的准确性取决于数据的质量和统计方法的选择,2026年,某半导体制造企业尝试用数字孪生技术优化晶圆生产流程时,曾因模型选择不当而遭遇挫折,他们最初采用基于物理方程的确定性模型,但发现无法捕捉生产中的随机波动(如材料纯度的微小变化),后来,他们转向统计学中的“随机过程模型”,结合历史生产数据,构建了一个概率性模型。
这个模型不仅能预测平均生产效率,还能量化生产波动对良品率的影响,当材料纯度波动超过0.5%时,良品率会下降3%,基于这一模型,企业调整了原材料采购标准,将纯度波动控制在0.3%以内,良品率因此提升了2个百分点,这一案例表明,数字孪生的模型构建必须基于统计学验证,而非单纯依赖经验或理论。
在化工行业,2026年某企业利用数字孪生技术优化反应釜控制时,也遇到了类似挑战,他们发现,传统的PID控制无法应对反应过程中的非线性变化,通过引入统计学中的“机器学习算法”(如随机森林),他们构建了一个数据驱动的模型,能够实时预测反应温度和压力的变化趋势,当输入原料流量增加10%时,模型会提前5分钟预测到温度将上升3℃,并自动调整冷却水流量,这一改进使反应釜的能耗降低了15%,同时减少了安全事故的发生。

预测与决策:从“模糊判断”到“量化评估”的统计学支撑
数字孪生的最终目标是支持决策,但决策的可靠性取决于预测的准确性,2026年,某钢铁企业在推进数字孪生项目时,曾因预测结果与实际偏差较大而受到质疑,他们最初采用简单的线性回归模型预测高炉铁水温度,但发现误差高达±15℃,后来,他们引入统计学中的“多元非线性回归”和“蒙特卡洛模拟”,结合高炉的实时数据和历史记录,构建了一个更复杂的模型。
这个模型不仅能预测铁水温度的平均值,还能给出预测结果的置信区间(如95%的概率下,温度将在1520℃至1540℃之间),基于这一量化评估,企业调整了高炉操作参数,将温度波动范围缩小了50%,显著提高了铁水质量,这一案例表明,数字孪生的预测必须提供统计意义上的可靠性评估,而非简单的点估计。
在能源领域,2026年某电网企业利用数字孪生技术优化电力调度时,也采用了类似的统计学方法,他们发现,传统的调度模型无法应对可再生能源(如风电和光伏)的波动性,通过引入统计学中的“概率预测”和“场景生成”,他们构建了一个能够量化不确定性的模型,模型会预测未来24小时内风电出力的概率分布(如90%的概率下,出力将在100MW至200MW之间),并基于这一分布生成多种调度方案,通过比较不同方案的期望成本和风险,企业选择了最优方案,将弃风率降低了30%。 本月绿色研发与无人机应用领域迎来新发展,相关应用不断深化
持续优化:从“静态模型”到“动态迭代”的统计学反馈
数字孪生不是一次性的项目,而是一个持续优化的过程,2026年,某航空发动机企业通过数字孪生技术优化维护策略时,发现初始模型在运行一段时间后预测精度下降,他们分析后发现,原因是发动机性能会随使用时间退化,而初始模型未考虑这一动态变化,为此,他们引入统计学中的“贝叶斯更新”方法,定期用新数据更新模型参数。

每运行100小时,模型会根据最新的振动数据和性能指标调整故障预测的阈值,通过这一动态迭代,模型的预测精度始终保持在90%以上,维护成本降低了25%,这一案例表明,数字孪生的模型必须具备自我学习能力,而统计学提供了实现这一目标的关键工具。
在汽车行业,2026年某电动车企业利用数字孪生技术优化电池寿命时,也采用了类似的反馈机制,他们发现,电池的衰减速度不仅与充放电次数有关,还与使用环境(如温度)和驾驶习惯(如急加速)密切相关,通过引入统计学中的“生存分析”和“协变量调整”,他们构建了一个能够动态评估电池健康状态的模型,模型会根据用户的驾驶数据和环境条件,实时调整电池寿命的预测结果,并给出个性化的维护建议,这一改进使电池的保修成本降低了40%,同时提升了用户满意度。
跨行业应用:统计学的普适性与行业特异性
数字孪生的统计学逻辑链条具有普适性,但不同行业的应用细节存在差异,2026年,某医疗设备企业尝试将数字孪生技术用于心脏起搏器的优化时,发现医疗领域的数据采集和模型构建面临特殊挑战,患者的心电信号具有高度个体化和随机性,传统统计方法难以直接应用,为此,他们结合医学知识和统计学工具,开发了一套专门的心电信号分析算法。 绿色防洪抗旱与绿色水处理热度持续攀升,相关应用不断深化
这个算法不仅能识别正常和异常心电信号,还能预测患者未来发生心律失常的风险,对于一位65岁男性患者,模型会分析其过去24小时的心电数据,结合年龄、性别和病史,给出未来一周发生房颤的概率为12%,基于这一预测,医生可以提前调整治疗方案,降低患者风险,这一案例表明,数字孪生的统计学方法必须与行业知识深度融合,才能发挥最大价值。
在农业领域,2026年某智能农场利用数字孪生技术优化作物生长时,也遇到了类似挑战,他们发现,农作物的生长受土壤湿度、温度、光照和养分等多种因素影响,且这些因素之间存在复杂的非线性关系,通过引入统计学中的“响应面分析”和“实验设计”,他们构建了一个能够量化各因素影响的模型,模型会预测当土壤湿度从60%提高到70%时,玉米的产量将增加8%,但当湿度超过75%时,产量会因根系缺氧而下降,基于这一模型,农场实现了精准灌溉,水资源利用率提高了30%。 2026年关注精准医疗与餐饮美食发展动态,技术创新推动产业升级
统计学的“隐形之手”
回顾2026年的工业数字孪生应用实践,我们会发现,无论是数据采集、模型构建,还是预测与决策,统计学的逻辑链条始终贯穿其中,它像一只“隐形的手”,将看似杂乱的数据转化为有价值的洞察,将抽象的模型转化为可操作的决策,对于企业而言,理解并应用这一逻辑链条,是释放数字孪生潜力的关键;对于从业者而言,掌握统计学工具,是提升竞争力的核心,随着工业4.0的深入发展,统计学的角色将愈发重要——它不仅是数字孪生的基石,更是工业智能化的“语言”。