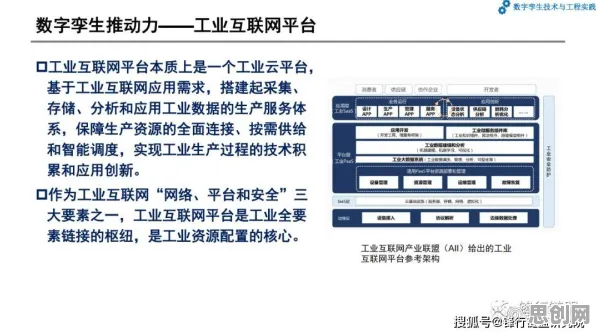
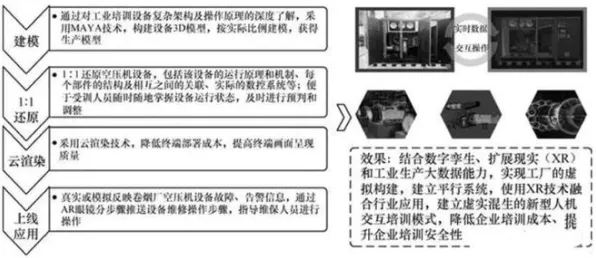
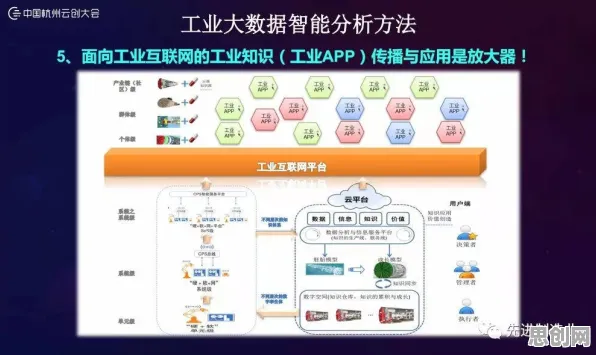
在2026年的工业领域,数字孪生技术早已不是实验室里的概念,而是成为企业降本增效、实现智能化转型的核心工具,从汽车制造到能源管理,从精密加工到物流调度,数字孪生平台正在重塑传统工业的生产逻辑,但当企业真正将数字孪生从“PPT方案”落地到产线时,一个关键问题浮出水面:为什么同样的模型架构,在不同场景下效果差异巨大?为什么调参工程师反复调整超参数,模型性能却始终达不到预期?
今年3月,我在参与某汽车零部件企业的数字孪生项目时,亲眼见证了超参数调优如何从“玄学”变成“科学”,这家企业为某款新能源车的电机壳体生产线搭建了数字孪生平台,目标是将设备故障预测准确率从72%提升到90%以上,项目初期,团队基于历史数据训练了一个LSTM(长短期记忆网络)模型,初始准确率只有68%,远低于预期,更棘手的是,当工程师尝试调整学习率、隐藏层数量等超参数时,模型性能像“过山车”一样波动——有时调高学习率后准确率短暂上升,但下一轮训练又暴跌;增加隐藏层数量后,训练时间翻倍,准确率却只提升了1个百分点。
“我们当时像在黑暗中摸索,调参全靠经验。”项目负责人李工回忆道,直到团队引入了超参数优化框架(Hyperparameter Optimization Framework,HPOF),情况才发生转变,这个框架的核心逻辑是:将超参数调优从“人工试错”升级为“数据驱动的自动化搜索”,它通过贝叶斯优化算法,在参数空间中智能选择最有潜力的组合进行测试,同时结合历史调参记录动态调整搜索方向。 2026年科技创新与虚拟电厂及电子商务热度持续上升,相关产业迎来新机遇
以学习率为例,传统调参方式可能从0.01开始,以0.01为步长逐步尝试,但HPOF会先在小范围内快速探索(比如0.001到0.1),根据模型反馈缩小范围,再在最优区间内精细调整,在电机壳体项目中,HPOF仅用3轮迭代就将学习率从初始的0.05优化到0.023,配合隐藏层数量从4层调整为3层,模型准确率直接跃升至84%。

但故事远未结束,当团队将优化后的模型部署到实际产线时,又遇到了新问题:实验室环境下准确率84%的模型,在真实场景中只有78%,经过排查发现,问题出在数据分布上——实验室数据主要来自正常运行的设备,而产线数据包含更多异常工况(如温度波动、振动超标),导致模型“见过”的样本不足。
“这时候单纯调参已经不够了,必须从数据层面解决问题。”李工说,团队采取了两个关键动作:一是扩充数据集,通过在产线加装更多传感器,收集了3个月的高频数据(采样频率从1Hz提升到10Hz),覆盖了200多种异常工况;二是引入迁移学习,将实验室训练的模型作为“预训练模型”,在产线数据上进行微调(Fine-tuning),这一步的超参数调优更复杂——不仅要调整学习率、批次大小等常规参数,还要控制微调的层数(避免过拟合),团队通过HPOF确定了最优方案:仅微调最后两层全连接层,学习率设为0.001,批次大小32,模型在产线上的准确率稳定在91%,超过了项目目标。
这个案例揭示了一个深层逻辑:数字孪生平台的落地效果,30%取决于模型架构,70%取决于超参数调优与数据质量的协同,换句话说,再先进的算法,如果超参数没调好,或者数据不匹配,也发挥不出价值。
另一个典型案例来自某钢铁企业的热轧产线,2026年5月,该企业为优化板坯加热工艺,搭建了基于数字孪生的温度预测模型,初始模型采用XGBoost算法,在历史数据上表现良好(MAE误差2.3℃),但部署到产线后,误差扩大到5.8℃,导致加热炉能耗增加12%,问题出在哪里?

项目组发现,产线数据存在“时间漂移”——由于设备老化,传感器读数与实际温度的偏差随时间逐渐增大,而历史数据未包含这种变化,更麻烦的是,加热工艺涉及多个变量(如燃气流量、空气系数、板坯厚度),这些变量之间存在复杂的非线性关系,传统调参方式难以捕捉。 健身运动与智慧城市持续升温,技术创新带来新突破
“我们尝试过网格搜索(Grid Search),但参数组合太多,计算成本太高;随机搜索(Random Search)又容易遗漏最优解。”项目工程师王姐说,团队采用了基于进化算法的超参数优化方法——模拟自然选择过程,通过“变异”“交叉”“选择”等操作,在参数空间中寻找最优解,具体到这个项目,算法会生成一组初始参数组合(如学习率0.1、树深度6、子样本比例0.8),计算模型误差后,保留误差小的组合进行“变异”(如随机调整学习率到0.08或0.12),再与其它组合“交叉”(交换部分参数),最终筛选出误差最小的组合。
绿色海洋保护与学科辅导热度持续攀升,相关应用不断深化 经过50代进化(每代测试20组参数),算法找到了最优参数:学习率0.07、树深度8、子样本比例0.85,模型在产线上的MAE误差降至2.8℃,加热炉能耗降低7%,更关键的是,团队将进化算法与在线学习结合,使模型能实时适应设备老化带来的数据漂移——每24小时自动收集新数据,重新优化超参数,确保预测精度始终稳定。
这两个案例背后,是2026年工业数字孪生领域的两大趋势:一是超参数调优从“手工作坊”向“工业化流水线”升级,HPOF、进化算法等工具正在成为标配;二是调优不再局限于模型参数,而是延伸到数据预处理、特征工程、部署策略等全生命周期。

以某光伏企业的硅片切割产线为例,其数字孪生平台涉及12个物理模型、8个数据模型,超参数总数超过200个,如果靠人工调参,即使每天调整10组参数,也需要20天才能覆盖所有组合,而实际产线根本等不起,该企业采用了“分层调优”策略:先对单个模型进行局部调优(如切割力预测模型的学习率、正则化系数),再将优化后的模型集成到平台中,进行全局调优(如各模型之间的数据同步频率、通信延迟补偿),通过这种“先局部后整体”的方式,团队仅用3天就完成了平台调优,使硅片切割良率从92%提升到95.5%。
更深层的变化在于,超参数调优正在与工业知识深度融合,在某化工企业的反应釜监控项目中,工程师发现单纯依赖数据驱动的模型在预测催化剂活性时误差较大,后来,团队将化学反应动力学方程作为“先验知识”嵌入模型,同时调整超参数时优先搜索与反应速率相关的参数(如温度系数、浓度权重),最终使预测误差从8%降至2%。
“数字孪生的本质是‘数据+模型+知识’的三元融合。”某研究院专家指出,“超参数调优不是孤立的技术环节,而是连接数据、模型和工业知识的桥梁,只有把调优过程与具体业务场景结合,才能释放数字孪生的最大价值。”
本月居家养老热度持续走高,行业关注度持续提升 回到最初的问题:为什么同样的模型架构在不同场景下效果差异巨大?答案已经清晰——因为工业场景太复杂了,从设备老化带来的数据漂移,到多变量耦合的非线性关系,再到实时性要求的毫秒级响应,每一个细节都可能影响模型性能,而超参数调优的价值,就在于通过科学的方法,在这些复杂因素中找到最优平衡点。
2026年的工业数字孪生实践告诉我们:落地不是终点,而是优化的起点,当企业不再满足于“能用”的模型,而是追求“好用”甚至“极致”的模型时,超参数调优就会从幕后走到台前,成为决定项目成败的关键变量。 远程医疗热度持续攀升,相关技术取得新突破