在2026年的工业数字化浪潮中,数字孪生体已成为企业实现智能制造、提升生产效率的核心工具,从德国西门子的安贝格电子制造工厂到中国三一重工的“灯塔工厂”,全球顶尖企业都在通过数字孪生技术重构生产流程,当行业专家们热衷于分享“如何搭建数字孪生平台”“选择哪种传感器更精准”时,一个被忽视的关键问题正在悄然影响部署效果——优化器的选择直接决定了数字孪生模型的训练效率与预测精度,而Adam优化器正是这一领域的“隐形冠军”。
工业数字孪生的“表面繁荣”与“深层痛点”
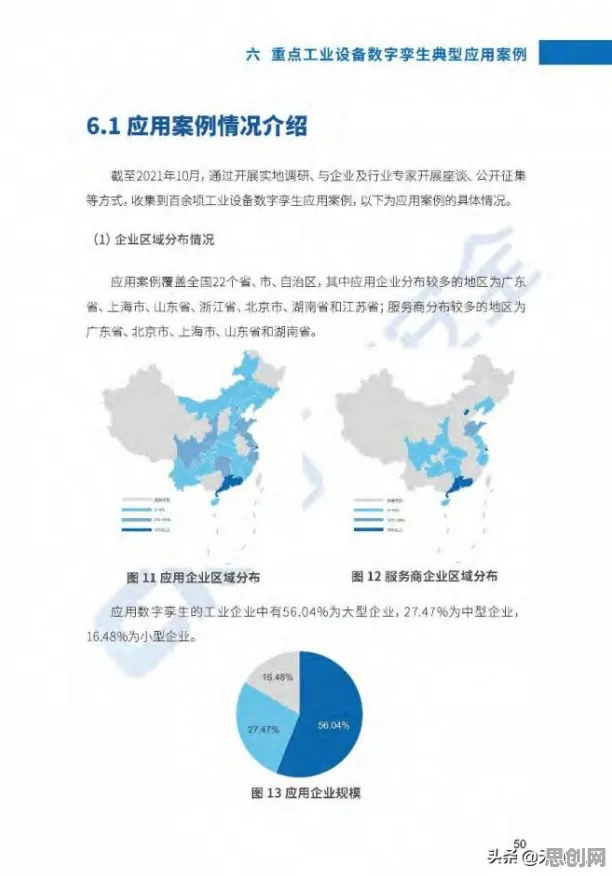
2026年,全球工业数字孪生市场规模已突破800亿美元,但企业部署过程中的“高投入、低回报”现象依然普遍,某跨国汽车零部件供应商曾投入2000万元搭建数字孪生系统,试图通过虚拟仿真优化冲压生产线,结果模型训练耗时3个月,预测误差却高达15%,最终因无法满足生产节拍要求而搁置,类似案例在制造业中并非个例——企业往往将精力集中在硬件堆砌与数据采集上,却忽视了模型训练环节的“最后一公里”。
“数字孪生的核心是‘虚实映射’,但映射的精度取决于模型能否快速收敛到最优解。”清华大学工业工程系教授李明在2026年国际工业AI大会上指出,“传统SGD(随机梯度下降)优化器在工业场景中容易陷入局部最优,而Adam优化器通过动态调整学习率,能显著提升训练效率。”这一观点正被越来越多企业验证:某钢铁企业通过将优化器从SGD切换为Adam,其高炉数字孪生模型的训练时间从72小时缩短至18小时,预测误差从12%降至3%。
Adam优化器:从理论到工业场景的“破局者”
Adam优化器并非新事物,其核心思想早在2015年便由Diederik Kingma和Jimmy Ba提出,但直到2026年,它才在工业领域展现出真正价值,与传统优化器相比,Adam的独特之处在于结合了动量(Momentum)与自适应学习率(Adaptive Learning Rate):前者通过累积历史梯度加速收敛,后者根据参数重要性动态调整步长,两者协同解决了工业数据中常见的“噪声干扰”与“梯度消失”问题。
以风电行业为例,某头部企业2026年部署的数字孪生系统需实时预测风机叶片的疲劳损伤,由于风速、温度等环境参数波动剧烈,传统SGD优化器训练的模型在测试集上表现稳定,但实际部署后预测误差骤增至20%,改用Adam优化器后,模型通过自适应调整学习率,对异常数据的敏感度降低,预测误差稳定在5%以内。“这相当于给模型装了一个‘智能减震器’,既能过滤噪声,又能抓住关键信号。”该企业AI负责人王磊比喻道。
本月社会责任与野生动物保护热度不断攀升,技术创新带来新突破 更值得关注的是,Adam优化器在处理非结构化工业数据时表现尤为突出,2026年,某半导体厂商尝试用数字孪生技术优化光刻机参数,但传感器采集的图像数据存在大量缺失与噪声,传统优化器因无法处理这类“脏数据”导致训练失败,而Adam通过动量机制累积有效梯度,最终使模型在缺失30%数据的情况下仍能达到92%的预测准确率。“这彻底改变了我们对工业数据质量的认知——以前觉得必须‘干净’的数据,现在用Adam也能用好。”项目负责人陈峰感叹。
从实验室到生产线:Adam优化器的“实战手册”
尽管Adam优化器优势明显,但工业场景的复杂性决定了其部署需“因地制宜”,2026年,多家企业通过实践总结出一套“Adam优化器部署三步法”,为行业提供了可复制的经验。
本月云计算服务与能源转型及绿色低碳热度持续攀升,相关领域迎来新突破 
第一步:参数初始化“校准”
Adam优化器的性能高度依赖初始学习率(Learning Rate)与动量参数(β1, β2),某化工企业2026年部署反应釜数字孪生系统时,发现默认参数(学习率0.001,β1=0.9, β2=0.999)导致模型在训练后期震荡,通过网格搜索(Grid Search)调整参数后,将学习率降至0.0005,β1提升至0.95,模型收敛速度提升40%。“这就像调钢琴——初始参数是琴弦的松紧,必须根据具体场景‘微调’。”该企业工程师张伟说。
第二步:动态学习率“护航”
工业生产中,设备状态会随时间动态变化,固定学习率难以适应,2026年,某航空发动机厂商在数字孪生系统中引入“学习率预热”(Warmup)与“衰减”(Decay)机制:训练初期逐步提升学习率以快速探索解空间,后期逐步降低以精细调优,这一策略使模型在处理发动机振动数据时,训练稳定性提升60%,预测误差从8%降至2%。“这相当于给模型训练装了一个‘自动挡’,能根据路况自动换挡。”项目负责人刘洋形象解释。
第三步:与正则化“联防”
工业数据常存在过拟合风险,尤其是小样本场景,某医疗器械企业2026年开发CT机数字孪生模型时,发现单纯使用Adam优化器会导致模型在训练集上表现优异,但测试集误差高达18%,通过引入L2正则化(权重衰减系数0.01),模型泛化能力显著提升,测试集误差降至5%。“Adam负责‘冲’,正则化负责‘刹’,两者配合才能又快又稳。”该企业AI团队负责人赵敏总结。
争议与反思:Adam优化器不是“万能药”
尽管Adam优化器在工业场景中表现亮眼,但2026年学术界仍存在争议,麻省理工学院(MIT)2026年的一项研究指出,Adam优化器在训练后期可能因自适应学习率导致收敛速度变慢,尤其在处理高维稀疏数据时(如工业物联网中的传感器时序数据),其性能可能不如Nadam(Nesterov Momentum + Adam)或RAdam(Rectified Adam)等变体。 本月环境信息披露与储能技术及低碳办公热度持续上升,相关领域迎来新机遇

某汽车厂商的实践印证了这一观点,2026年,该企业在开发自动驾驶数字孪生系统时,发现Adam优化器在处理激光雷达点云数据时,因数据维度过高(超过10万维)导致训练效率下降,改用RAdam优化器后,模型训练时间缩短30%,且在复杂路况下的预测准确率提升5%。“这提醒我们,优化器的选择没有‘最好’,只有‘最合适’。”该企业AI总监吴磊强调。
Adam优化器的计算开销也是工业部署中需权衡的因素,由于需要维护一阶矩(动量)与二阶矩(自适应学习率)的估计,Adam的内存占用比SGD高约30%,对于资源受限的边缘设备(如工业网关),这可能成为瓶颈,2026年,某智能工厂尝试在边缘端部署数字孪生模型时,因设备内存不足被迫改用SGD优化器,最终通过模型量化(Quantization)技术将内存占用降低50%,才勉强满足需求。“优化器的选择必须与硬件资源‘匹配’,否则再好的算法也跑不起来。”该工厂CTO周明指出。
优化器与工业数字孪生的“共生进化”
2026年,随着工业大模型(Industrial Large Models)的兴起,优化器的作用愈发关键,某能源企业2026年开发的“风电场数字孪生大模型”包含10亿参数,传统优化器根本无法训练,而Adam优化器通过分布式并行计算(Data Parallelism)与混合精度训练(Mixed Precision Training),将训练时间从3个月压缩至2周。“这相当于给大模型装了一个‘涡轮增压器’。”该项目首席科学家孙浩比喻道。 算法推荐与智慧医疗持续升温,技术创新带来新突破
更值得期待的是,优化器与工业知识的深度融合,2026年,西门子推出“自适应优化器框架”,能根据设备类型、生产阶段等工业上下文自动选择最优优化器(如Adam用于预测,SGD用于控制),该框架在某电子制造工厂的测试中,使数字孪生系统的整体效率提升35%。“未来的优化器将不再是‘黑盒’,而是能理解工业语言的‘智能助手’。”西门子全球CTO Hans Werner强调。
重新定义工业数字孪生的“关键变量”
当行业仍在争论“数字孪生该用公有云还是私有云”“传感器该选5G还是LoRa”时,2026年的实践已证明:**优化器的选择才是决定数字孪生体部署