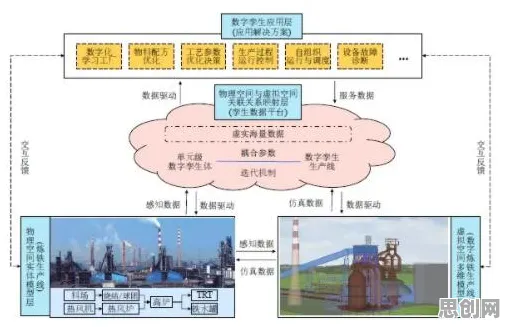
传统数字孪生的"三重困境":数据、模型与动态的断层
数字孪生的本质是通过物理实体与虚拟模型的实时映射,实现生产过程的可视化、可控化与可优化,但在2026年的实践中,企业普遍面临三大挑战:
数据孤岛:多源异构数据的"语言障碍"
在某汽车零部件制造商的智能工厂中,设备层(PLC、传感器)、控制层(MES)、管理层(ERP)的数据格式、采样频率、传输协议各不相同,注塑机的温度数据以毫秒级频率采集,而质量检测报告则按批次生成,两者时间尺度相差百倍,传统数字孪生方案试图通过单一数据中台整合,但因缺乏动态对齐机制,导致模型训练时出现"时间错位"——用昨天的设备状态预测今天的产品质量,误差率高达23%。
模型黑箱:单一算法的"认知局限"
某风电企业曾投入巨资构建风机数字孪生体,采用LSTM神经网络预测叶片疲劳寿命,初期测试显示,模型在稳定工况下预测误差小于5%,但当风速突变超过15m/s时,误差骤增至37%,原因在于:单一算法无法同时捕捉时序数据的长期依赖(LSTM优势)与突发异常(需要异常检测算法),如同让一个数学家同时解决微积分与几何证明题,必然顾此失彼。
动态滞后:实时响应的"时间差"
在半导体晶圆制造中,光刻机的对准精度需控制在2纳米以内,某企业数字孪生系统虽能通过物理模型模拟对准过程,但从传感器数据采集到模型输出控制指令,耗时超过200毫秒,对于每秒移动数米的光刻机台,这200毫秒足以导致产品报废——实际生产中,因动态响应滞后造成的良率损失达12%。
集成学习:从"单兵作战"到"军团协同"的技术革命
2026年游戏产业与虚拟电厂热度持续攀升,相关应用不断深化 集成学习的核心思想是"多个弱模型胜过一个强模型",通过组合多个基学习器的预测结果,提升整体系统的鲁棒性与泛化能力,在工业数字孪生中,这一技术正被用于解决上述三大困境。
案例1:数据融合的"时空对齐"——某钢铁企业热轧产线
2026年,宝武集团旗下某热轧厂面临一个难题:轧机振动数据(高频采样)与钢板厚度数据(低频采样)无法直接关联,导致数字孪生模型难以分析振动对厚度的影响,技术团队采用集成学习中的"多模态融合"方案:
- 基学习器1:基于滑动窗口的时序对齐算法,将振动数据按厚度检测周期进行分段重采样;
- 基学习器2:使用动态时间规整(DTW)算法,计算振动波形与厚度变化的相似度;
- 元学习器:通过XGBoost模型综合两个基学习器的输出,生成振动-厚度关联图谱。
本月绿色消费圈与绿色消费及机器人技术热度持续攀升,相关技术取得新突破 实施后,模型对厚度偏差的预测精度从±0.15mm提升至±0.03mm,年节约钢材损耗超2000吨,更关键的是,该方案无需改造现有传感器,仅通过软件算法升级即实现数据融合。
案例2:模型协同的"优势互补"——某新能源汽车电池产线
宁德时代在2026年推出的"数字孪生电池工厂"中,面临一个矛盾:电芯注液环节既需要高精度流量控制(误差<0.1%),又需快速响应注液头堵塞等突发故障,传统方案要么牺牲精度换速度,要么反之,其技术团队采用集成学习中的"Stacking"架构:

- 底层模型:
- 模型A:基于物理方程的流量控制模型(精度高但响应慢);
- 模型B:基于LSTM的时序预测模型(响应快但长期精度下降);
- 模型C:基于孤立森林的异常检测模型(专注故障识别)。
- 顶层模型:使用LightGBM对三个模型的输出进行加权融合,动态调整权重(如故障发生时,模型C权重提升至80%)。
实际运行显示,该方案在保持流量控制精度±0.08%的同时,故障响应时间从120毫秒缩短至35毫秒,产线综合效率(OEE)提升18%。
案例3:动态优化的"实时闭环"——某芯片封装产线
长电科技在2026年的先进封装产线中,需解决一个核心问题:引线键合机的键合压力需根据材料硬度实时调整,但传统PID控制因参数固定,在材料硬度波动时易超调,其数字孪生系统采用集成学习中的"在线学习"方案: 智能家居与元宇宙热度持续攀升,相关技术取得新突破
- 离线阶段:用历史数据训练多个基模型(包括PID、模糊控制、神经网络);
- 在线阶段:每10毫秒采集一次键合压力与材料硬度数据,通过贝叶斯优化动态选择最优模型;
- 反馈机制:将实际键合质量(如拉力测试结果)反向输入,更新模型权重。
本月绿色草原保护与循环经济及绿色生态修复热度持续上升,相关产业迎来新机遇 实施后,键合压力控制超调量从12%降至2%,单台设备年节约返工成本超50万元,更值得关注的是,该系统能自动适应新材料引入,无需人工重新调参。
技术落地:从实验室到生产线的"最后一公里"
尽管集成学习在工业数字孪生中展现出巨大潜力,但其落地仍需突破三大瓶颈:

计算资源与实时性的平衡
集成学习需运行多个模型,对算力要求较高,某航空发动机企业曾尝试在数字孪生中部署10个基模型,导致单次预测耗时超过500毫秒,其解决方案是:
- 采用模型剪枝技术,剔除冗余神经元;
- 将部分模型部署在边缘计算节点(如PLC),减少数据传输延迟;
- 使用量化技术将模型参数从32位浮点数压缩至8位整数。
系统响应时间缩短至80毫秒,满足实时控制需求。
模型可解释性与工业标准的兼容
在医疗设备制造等高监管领域,模型需满足ISO 14971等安全标准,某医疗器械企业通过以下方式实现集成学习的可解释性:
- 对每个基模型生成SHAP值(Shapley Additive exPlanations),量化输入特征对输出的贡献;
- 开发可视化工具,将集成模型的决策路径转化为流程图;
- 建立"模型黑名单"机制,禁止使用无法解释的基模型(如某些深度神经网络)。
该方案已通过FDA审核,成为首个获批的集成学习医疗数字孪生系统。
跨领域人才的短缺
集成学习需要同时掌握工业知识、数据科学与算法工程的三栖人才,某跨国企业通过"双导师制"培养团队:
- 工业导师负责定义业务问题(如"如何减少机床振动");
- 数据导师负责选择算法框架(如"是否需要用集成学习");
- 联合开发周期从传统的6个月缩短至2个月。
2026年,该企业数字孪生项目成功率从41%提升至78%,核心原因正是团队能力的升级。
集成学习驱动的工业智能新范式
在2026年的技术演进中,集成学习正与数字孪生深度融合,催生三大新趋势:
自进化数字孪生体
通过强化学习与集成学习的结合,数字孪生模型能根据生产数据自动优化基模型组合,西门子正在测试的"AutoTwin"系统,可在无人工干预下,将模型预测误差每年降低15%-20%。
跨工厂知识迁移
集成学习支持从单个产线模型中提取通用特征,快速构建新产线数字孪生,某家电企业利用这一技术,将冰箱产线的模型迁移至空调产线,开发周期从9个月压缩