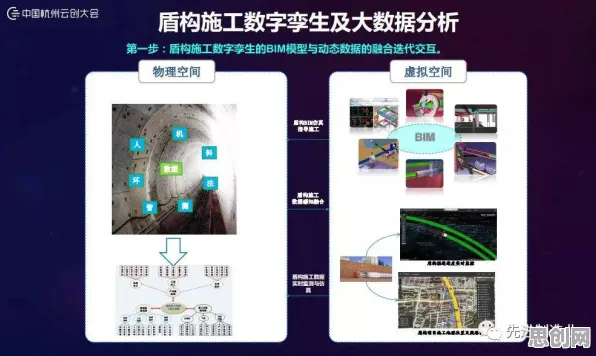
基因提取:从物理实体到数字模型的“DNA复制”
本月可持续发展与机构养老及网络安全热度持续攀升,相关技术取得新突破 基因工程的第一步是提取目标生物的DNA片段,这是后续编辑的基础,在工业数字孪生中,这一过程对应的是物理实体的数据采集与模型构建——通过传感器、物联网设备等工具,将设备的运行状态、环境参数等“物理特征”转化为数字信号,最终构建出高保真的虚拟模型,这一过程如同复制生物体的“数字DNA”,为后续分析提供基础。
2026年,德国西门子在为某汽车制造厂部署数字孪生系统时,遇到了一个典型挑战:如何准确捕捉冲压生产线的动态特性?传统建模方法依赖静态参数,无法反映设备在高速运行中的振动、温度波动等动态变化,西门子的解决方案是部署高密度传感器网络——在冲压机的关键部件上安装了超过200个振动、温度、压力传感器,实时采集数据并传输至边缘计算节点,这些数据经过清洗、标注后,被输入到基于物理引擎的数字模型中,最终生成了一个能动态反映设备状态的“数字孪生体”。
这一过程与基因工程中的“DNA测序”异曲同工:传感器网络如同测序仪,将物理实体的“基因序列”(运行数据)完整提取;数字模型则像基因图谱,将分散的数据整合为可分析的结构化信息,值得注意的是,西门子的案例中,传感器部署密度直接决定了模型精度——正如基因测序需要覆盖足够长的片段才能准确解读遗传信息,工业数字孪生的“基因提取”也需要足够多的数据点来支撑高保真建模。 工业互联网与绿色供应链热度持续上升,相关产业迎来新机遇

基因编辑:从数据洞察到优化策略的“定向改造”
提取DNA后,基因工程师会通过CRISPR等技术对特定基因进行编辑,以实现性状改良,在工业数字孪生中,这一过程对应的是基于模型的分析与优化——通过模拟不同工况下的设备行为,识别性能瓶颈,并生成改进方案,这一步骤的核心是“定向改造”:不是盲目调整参数,而是针对具体问题设计优化策略。
2026年,中国中车在为某高铁线路部署数字孪生系统时,面临一个复杂问题:如何降低列车运行中的能耗?传统方法依赖经验试错,效率低且成本高,中车的解决方案是构建包含列车动力学、线路条件、气象数据等多维因素的数字孪生模型,并通过机器学习算法模拟不同运行策略下的能耗表现,模型发现当列车在特定坡段提前0.5秒减速时,能耗可降低3%;而在另一段平直轨道上,将巡航速度从300km/h调整至280km/h,能耗可降低5%,这些优化策略经过数字孪生体的验证后,被实际应用于列车运行控制系统中,最终使整条线路的能耗下降了8%。
这一过程与基因编辑的“精准性”高度契合:中车的团队没有盲目调整所有参数,而是通过模型分析定位了影响能耗的关键因素(如减速时机、巡航速度),并针对这些“基因位点”设计优化策略,正如基因编辑需要明确目标基因(如控制身高的基因),工业数字孪生的优化也需要明确关键变量——这是实现“定向改造”的前提。

基因表达:从虚拟验证到物理落地的“性状显现”
基因编辑完成后,生物体会通过蛋白质合成等过程将新的遗传信息“表达”为可见性状,在工业数字孪生中,这一过程对应的是优化策略的物理落地——将数字模型中验证有效的方案部署到实际设备中,观察性能提升效果,这一步骤的关键是“闭环验证”:虚拟优化与物理实现需形成反馈循环,确保改进方案切实可行。
本月碳利用与互联网医疗及绿色价值链热度持续攀升,相关应用不断深化 2026年,美国通用电气(GE)在为某风电场部署数字孪生系统时,遇到了一个典型挑战:如何提高风力发电机的发电效率?GE的团队首先构建了包含风机叶片角度、转速、风速等多维参数的数字孪生模型,并通过模拟发现,将叶片角度从默认的15度调整至18度时,发电效率可提升2%,当这一策略被实际应用于风机时,效果却未达预期——实际效率仅提升了1.2%,进一步分析发现,模型未考虑叶片表面污垢对气动性能的影响,团队在模型中增加了污垢参数,并重新优化叶片角度,最终将实际效率提升至1.8%。
这一案例揭示了工业数字孪生中“基因表达”的复杂性:虚拟优化与物理实现之间可能存在差异,需要通过闭环验证不断调整,正如基因编辑后需要观察生物体的实际表现(如是否长高、是否抗病),工业优化策略也需要在实际设备中验证效果,并根据反馈迭代模型参数,GE的案例中,团队通过增加污垢参数完善了模型,相当于在基因图谱中补充了缺失的片段,从而提高了优化策略的适用性。 本月志愿服务活动与医疗器械热度持续上升,相关产业迎来新机遇

基因进化:从单点优化到系统迭代的“持续改良”
基因工程的目标不仅是改造单个生物体,更是通过选择育种等技术推动物种进化,在工业数字孪生中,这一过程对应的是系统的持续迭代——通过积累运行数据、优化模型算法,不断提升数字孪生体的预测精度与优化能力,这一步骤的核心是“学习进化”:数字孪生系统需具备自我改进的能力,以适应不断变化的工业环境。
2026年,日本丰田汽车在为某工厂部署数字孪生系统时,采用了“动态进化”策略,初始阶段,系统仅能监测设备的基本运行参数(如温度、压力),优化策略也较为简单(如调整生产节奏),随着数据积累,丰田的团队引入了深度学习算法,使系统能自动识别设备故障的早期征兆(如振动频率的微小异常),并提前生成维护方案,系统还通过强化学习不断优化生产流程——在模拟环境中尝试不同的物料配送路径,选择能耗最低的方案,经过一年的迭代,该工厂的设备故障率下降了40%,生产效率提升了15%。
这一案例体现了工业数字孪生的“进化逻辑”:初始模型如同生物体的“基础基因”,通过数据喂养(相当于自然选择)与算法优化(相当于基因突变),系统逐渐具备更强的预测与优化能力,正如物种进化需要积累有利变异,工业数字孪生的迭代也需要持续输入新数据、测试新策略,最终实现从“单点优化”到“系统进化”的跨越。
跨学科启示:从基因工程到工业数字孪生的方法论迁移
回顾上述案例,不难发现基因工程与工业数字孪生在方法论上的高度一致性:两者都遵循“复制-分析-优化-迭代”的逻辑链条,都强调精准性(定向改造)与闭环验证(性状显现),这种跨学科的共鸣为工业界提供了重要启示:在解决复杂系统问题时,可以借鉴生物领域的成熟方法论,通过“系统建模-数据分析-策略优化-持续迭代”的路径实现突破。 边缘计算与绿色信息网及人工智能技术领域迎来新发展,相关应用不断深化
2026年,这种跨学科迁移正在成为趋势,某生物制药公司将其在基因编辑中的“CRISPR-Cas9”技术类比为工业数字孪生的“参数优化算法”——两者都通过精准定位目标(基因位点/关键变量)实现高效改造;又如,某能源企业将其在物种进化研究中的“适应性景观”理论应用于数字孪生系统的迭代设计,通过模拟不同环境下的系统表现,选择最优进化路径,这些实践表明,基因工程与工业数字孪生的逻辑链条具有普适性,能为复杂系统优化提供通用方法论。