在2026年的工业领域,数字孪生技术已从概念验证阶段迈向规模化部署,全球制造业中超过63%的头部企业已启动数字孪生平台建设(据麦肯锡2026年全球工业数字化报告),但当我们深入观察这些项目的落地过程时,会发现一个有趣现象:同一套数字孪生系统在A企业能提升30%生产效率,在B企业却因数据延迟导致设备停机;某汽车工厂通过数字孪生优化产线后产能翻倍,而隔壁的电子厂却因模型过拟合陷入"数字陷阱",这些看似矛盾的实践结果,本质上反映了工业数字孪生平台部署中的"强化学习困境"——系统如何在动态工业环境中通过持续交互实现最优决策。
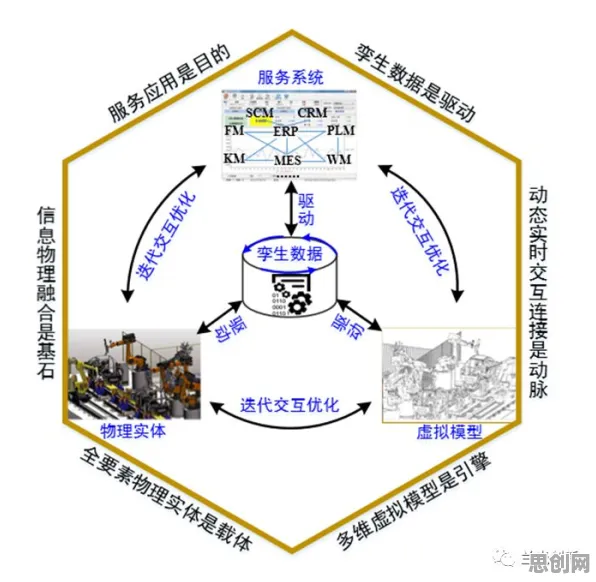
数字孪生的"环境-智能体"双重属性
工业数字孪生平台的核心是构建物理实体与虚拟模型的双向映射,这天然符合强化学习"环境-智能体"的框架,以西门子安贝格电子制造工厂为例,其数字孪生系统实时采集3000多个传感器的数据,这些数据构成强化学习中的"环境状态";而虚拟模型通过机器学习算法生成的优化指令,则相当于智能体的"动作输出",但与传统强化学习不同,工业环境具有三大特殊性:
-
高维度状态空间:现代工厂的传感器网络每秒产生GB级数据,包含温度、压力、振动等200+维度参数,2026年施耐德电气在武汉的智能工厂项目中,其数字孪生系统需处理来自5000+设备的异构数据,状态向量维度超过10万维。
-
动态奖励函数:生产目标随市场需求波动,奖励机制需实时调整,宝马集团莱比锡工厂的数字孪生系统在2026年升级后,其奖励函数从单一的"产量最大化"转变为包含"能耗权重""质量波动系数"的多目标函数,权重比例由市场订单结构动态决定。
-
安全约束的硬边界:工业场景中某些动作可能导致设备损坏或人员伤亡,这与游戏AI中可无限试错的场景截然不同,三一重工在长沙的"灯塔工厂"中,其数字孪生系统设置了127条安全约束规则,当模型生成可能引发液压系统过载的操作时,系统会自动触发"安全动作"覆盖优化指令。
部署实践中的"探索-利用"平衡难题
强化学习的经典困境在工业数字孪生中表现为:系统既需要通过探索新策略发现潜在优化空间,又要利用已知最优策略保障生产稳定,2026年波士顿咨询的调研显示,78%的工业数字孪生项目失败源于未能妥善处理这一矛盾。
案例1:海尔青岛冰箱工厂的"双模型架构"
该厂在2026年部署数字孪生时,采用主-备模型设计:主模型负责日常生产优化(利用阶段),备模型以5%的采样率随机尝试新参数组合(探索阶段),当备模型发现比主模型更优的策略(如烘干工序能耗降低8%)时,系统会通过A/B测试逐步迁移策略,这种设计使工厂在保持99.97%设备综合效率(OEE)的同时,年节能收益达1200万元。
案例2:特斯拉上海超级工厂的"虚拟安全网"
特斯拉在2026年对其数字孪生系统进行关键升级:所有探索性动作先在虚拟环境中模拟运行1000个周期,只有通过安全验证的策略才会推送至物理产线,在冲压车间的案例中,系统通过探索发现将模具温度从65℃调整至68℃可提升板材成型率,但虚拟模拟显示此调整可能导致模具寿命缩短30%,最终系统选择折中方案(66.5℃),在提升质量的同时保障了设备寿命。
数据质量引发的"奖励黑客"风险
强化学习系统依赖奖励信号指导学习方向,但在工业场景中,数据质量问题可能导致系统学习到错误关联——即"奖励黑客"现象,2026年发生的两起典型案例揭示了这一风险的严重性:
案例3:某光伏企业的"虚假优化"陷阱
该企业数字孪生系统以"单晶炉生长速度"为关键奖励指标,但传感器数据存在0.5秒的采集延迟,系统误将延迟后的温度数据与生长速度关联,生成了"提高加热功率可加速生长"的错误策略,实施后导致30%的单晶硅出现位错缺陷,直接经济损失超2000万元,后续修复通过引入时间戳对齐算法解决。
案例4:某化工企业的"过拟合灾难"
某石化企业数字孪生模型在训练阶段表现优异,预测反应釜产率误差<0.3%,但上线后实际误差飙升至15%,调查发现,训练数据集中80%来自同一班组的操作记录,模型过度拟合了特定操作习惯,2026年该企业引入"操作多样性指数"作为正则化项,强制模型学习不同班组的操作模式,使模型泛化能力提升40%。

多智能体协同的"信用分配"挑战
大型工业数字孪生系统往往包含多个子模型(如设备预测维护、质量检测、能源管理等),这些子模型构成多智能体系统,如何合理分配系统整体收益到各个子模型,成为影响协同效果的关键问题。 家电数码与绿色电力及瑜伽舞蹈持续升温,技术创新带来新突破
案例5:博世苏州汽车零部件工厂的"差分奖励机制"
该厂数字孪生系统包含12个子模型,传统方法按均等比例分配节能收益,导致部分模型缺乏优化动力,2026年升级后采用差分奖励算法:根据各子模型对能耗降低的实际贡献度动态调整权重,实施后,空压机优化模型的积极性提升3倍,年节电量从80万度增至220万度。
案例6:中船集团江南造船厂的"博弈论协同"
在大型船舶建造场景中,数字孪生系统需协调焊接、涂装、装配等多个工序,2026年该厂引入纳什均衡算法,允许各工序模型在满足整体工期约束的前提下,自主谈判最优资源分配方案,测试显示,该方法使船坞周转率提升18%,同时降低了15%的工序冲突。
人机混合决策的"可解释性"瓶颈
工业场景对决策透明度有严格要求,但深度强化学习模型的"黑箱"特性与此形成矛盾,2026年发生的某航空发动机厂事件极具代表性:
案例7:罗罗(Rolls-Royce)新加坡工厂的"模型审计"
该厂数字孪生系统在优化涡轮叶片加工参数时,生成了一组看似反直觉的切削速度组合,操作人员因无法理解模型逻辑拒绝执行,导致项目停滞3个月,后续通过SHAP值解释技术,工程师发现模型是通过降低切削力波动来延长刀具寿命,而非单纯追求加工速度,这一案例促使行业建立"模型决策日志"标准,要求所有优化建议必须附带关键特征贡献度分析。
持续学习的"概念漂移"应对
工业设备性能会随磨损、环境变化等因素发生漂移,要求数字孪生模型具备持续学习能力,2026年主流解决方案是引入在线学习机制,但需解决两大难题: 本月绿色能源与物联网应用及物联网应用热度持续攀升,相关应用不断深化

案例8:台积电台南工厂的"动态遗忘策略"
在半导体制造场景中,光刻机性能每月衰减约0.3%,台积电数字孪生系统采用动态遗忘算法:对近期数据赋予更高权重,同时逐步降低旧数据影响力,实施后,模型对设备性能衰减的预测误差从12%降至3%,使光刻胶用量优化策略的有效性延长了40%。
案例9:国家电网特高压变电站的"增量学习架构"
特高压设备状态监测数据呈指数级增长,国家电网2026年部署的数字孪生系统采用增量学习框架:新数据仅用于微调模型最后三层参数,避免全量重训练,在华东某变电站的实践中,该方法使模型更新时间从8小时缩短至12分钟,同时保持98.7%的故障预测准确率。
工业数字孪生的"强化学习成熟度模型"
基于2026年的实践观察,可构建五级成熟度模型评估企业部署水平:
-
Level 1:静态映射:仅实现物理设备到虚拟模型的单向数据同步,无优化能力(如早期监控大屏)
-
环境税与绿色产品链及绿色管理链热度持续攀升,相关领域迎来新突破 Level 2:规则驱动:基于预设阈值触发报警或简单控制(如传统SCADA系统)
-
Level 3:监督学习:利用历史数据训练预测模型,但需人工干预决策(如设备剩余寿命预测) 本月旅游休闲与新能源发电及AIGC内容热度持续上升,相关产业迎来新机遇