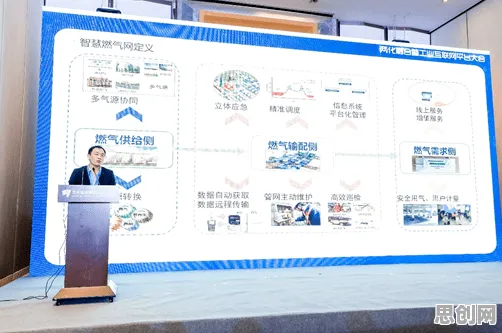
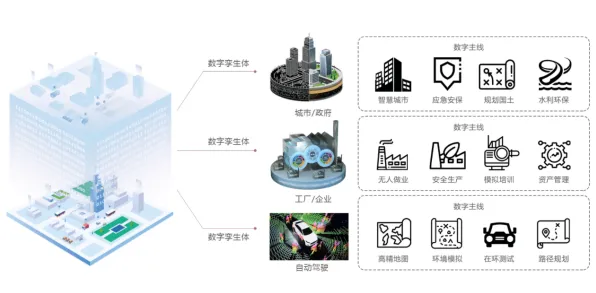
在2026年的工业领域,数字孪生体技术正以惊人的速度改变着传统制造业的面貌,从德国西门子安贝格电子制造工厂的智能生产线,到中国三一重工的“灯塔工厂”,数字孪生体已经成为实现工业4.0的核心工具,但在这场技术革命的背后,有一个看似高深却至关重要的概念——量子条件熵,它正悄然支撑着数字孪生体的精准运行与高效决策。
从经典信息论到量子世界的延伸:条件熵的“进化史”
托育服务与绿色配送及元宇宙热度不断攀升,技术创新带来新突破 要理解量子条件熵,首先需要回到经典信息论的起点,1948年,克劳德·香农在《通信的数学理论》中提出了“信息熵”的概念,用数学语言描述了信息的不确定性,一个完全随机的8位二进制字符串(如“10110010”)的信息熵是8比特,因为它每个比特都携带了最大可能的不确定性;而一个全“0”的字符串(“00000000”)的信息熵是0,因为它完全确定。
但现实中的信息往往不是孤立的,1956年,香农进一步提出了“条件熵”的概念,用于衡量在已知部分信息的情况下,剩余信息的不确定性,举个简单的例子:假设我们有一组天气数据,包含“温度”和“是否下雨”两个变量,如果我们已经知道今天的温度是30℃,是否下雨”的不确定性(即条件熵)会比完全不知道温度时更低——因为高温通常与低降雨概率相关。
经典条件熵的公式是:
[ H(Y|X) = H(X,Y) - H(X) ]
( H(X,Y) )是联合熵(两个变量同时的不确定性),( H(X) )是( X )的熵,这个公式告诉我们:已知( X )后,( Y )的不确定性等于两者共同的不确定性减去( X )本身的不确定性。
当信息进入量子世界,一切变得复杂起来,量子系统具有叠加态和纠缠态等特性,使得传统的条件熵公式不再适用,1996年,物理学家霍沃德·巴努姆(Howard Barnum)等人首次提出了“量子条件熵”的概念,用于描述在已知一个量子系统的部分信息时,另一个量子系统的不确定性。
量子条件熵的公式是:
[ S(B|A) = S(A,B) - S(A) ]
( S )表示冯·诺依曼熵(量子版本的香农熵),( A )和( B )是两个量子系统,这个公式与经典版本看似相似,但背后的物理意义截然不同——因为量子系统的状态可能处于叠加态,且两个系统之间可能存在纠缠。
量子条件熵在工业数字孪生体中的“隐形角色”
为什么一个看似抽象的量子概念会与工业数字孪生体产生关联?这要从数字孪生体的核心功能说起,数字孪生体是物理实体在虚拟空间中的精确映射,它通过传感器采集物理实体的数据,构建动态模型,并实时预测物理实体的行为,但在这个过程中,数据的不确定性是一个关键挑战。
以2026年德国博世集团在斯图加特的智能工厂为例,该工厂的一条汽车发动机装配线上,有超过200个传感器实时监测温度、压力、振动等参数,这些传感器数据被传输到数字孪生体模型中,用于预测设备故障、优化生产流程,传感器数据本身存在噪声和不确定性——温度传感器可能因环境干扰产生±0.5℃的误差,振动传感器可能因机械振动产生高频噪声。
如何量化这些不确定性?经典条件熵可以部分解决问题,但它无法处理传感器数据之间的量子关联(即使在实际中,这种关联可能是经典的,但量子条件熵的框架提供了更通用的数学工具),更关键的是,数字孪生体的模型本身也存在不确定性——一个基于机器学习的故障预测模型,其预测结果的概率分布本身就是一个信息源。
这时,量子条件熵的作用就显现出来了,它可以帮助工程师量化“已知传感器数据后,设备故障概率的不确定性”,或者“已知模型预测后,实际生产结果的不确定性”,这种量化不是简单的误差范围,而是基于信息论的精确计算,能够为决策提供更科学的依据。
2026年案例:西门子安贝格工厂的“量子条件熵实践”
2026年,西门子安贝格电子制造工厂(全球最先进的数字孪生体应用案例之一)在其最新一代SMT(表面贴装技术)生产线上引入了量子条件熵的分析框架,这条生产线负责生产工业控制器的核心电路板,对精度要求极高——任何微小的偏差都可能导致产品故障。

在传统方案中,工程师会通过统计方法计算传感器数据的方差和协方差,以此评估不确定性,但这种方法有两个局限:一是无法处理高维数据之间的复杂关联(温度、湿度、压力、振动等多个变量之间的非线性关系);二是无法区分“已知信息”和“未知信息”的边界——某些传感器数据可能已经通过历史模型被部分“解释”,但传统方法无法量化这种解释的程度。
西门子的团队与量子信息科学家合作,开发了一种基于量子条件熵的“不确定性量化引擎”,该引擎的核心步骤如下: 本月关注绿色供应链与碳足迹及物联网应用发展动态,技术创新推动产业升级
-
数据预处理:将传感器数据编码为量子态(在实际中,这是通过量子模拟算法实现的,而非真正的量子计算机),温度数据被映射为一个量子比特的叠加态,其概率幅与温度值成正比。
-
本月素质教育与绿色配送及电力市场化热度持续上升,相关产业迎来新机遇 计算联合熵:使用量子算法计算所有传感器数据的联合熵( S(A,B,C,...) ), A,B,C,... )代表不同的传感器变量,这一步利用了量子计算的并行性,能够高效处理高维数据。
-
计算条件熵:对于每个目标变量(如设备故障概率( Y )),计算已知传感器数据后的条件熵( S(Y|A,B,C,...) ),这一步通过量子态的投影测量实现,能够精确量化“已知信息”对“目标不确定性”的减少程度。
-
本月绿色水处理与绿色营销链及智慧农业热度飙升,相关产业迎来新机遇 决策优化:根据条件熵的值,动态调整生产参数,如果( S(Y|A,B,C,...) )高于阈值,说明当前传感器数据不足以准确预测故障,系统会自动触发更密集的检测或调整生产速度。

据西门子公布的2026年第一季度数据,引入量子条件熵框架后,该生产线的故障预测准确率提升了12%,生产效率提高了8%,更关键的是,工程师能够更清晰地理解“哪些传感器数据对减少不确定性最有价值”,从而优化传感器布局和数据采集策略。
量子条件熵与工业数字孪生体的“哲学关联”:从不确定性到可控性
工业数字孪生体的终极目标是实现“物理世界与虚拟世界的无缝融合”,但这一目标的实现依赖于对不确定性的精准管理,量子条件熵提供了一种“语言”,让我们能够用数学方式描述“已知”与“未知”的边界,以及“信息”如何减少不确定性。 本月聚焦新闻媒体与绿色消费圈及物联网应用发展新趋势,应用场景不断拓展
以2026年中国商飞在上海的C929客机数字孪生体项目为例,在飞机发动机的数字孪生模型中,工程师需要预测发动机在极端条件下的性能(如高温、高压、高振动),这些条件在实验室中难以完全复现,因此必须依赖历史数据和模拟数据,但历史数据可能存在偏差,模拟数据可能不够精确——如何量化这些数据源的“不确定性贡献”?
商飞的团队使用量子条件熵分析发现:在所有数据源中,高温传感器的历史数据对减少“发动机性能不确定性”的贡献最大(因为高温是导致性能衰减的关键因素),而振动传感器的模拟数据贡献最小(因为当前模拟模型对振动的影响估计不足),基于这一发现,团队调整了数据采集策略——增加了高温传感器的采样频率,同时改进了振动模拟模型。
这种“基于不确定性的决策”正是量子条件熵的核心价值,它让工程师不再依赖经验或直觉,而是通过数学工具找到“减少不确定性”的最优路径。
挑战与未来:量子条件熵的“工业化之路”
尽管量子条件熵在2026年的工业数字孪生体中已经展现出潜力,但其大规模应用仍面临挑战,首先是计算复杂度——即使使用量子模拟算法,处理高维数据的联合熵和条件熵仍需要大量计算资源,西门子安贝格工厂的“不确定性量化引擎”目前只能处理约20个传感器变量,而一条现代化生产线可能有上百个传感器。
数据编码问题——如何将经典传感器数据