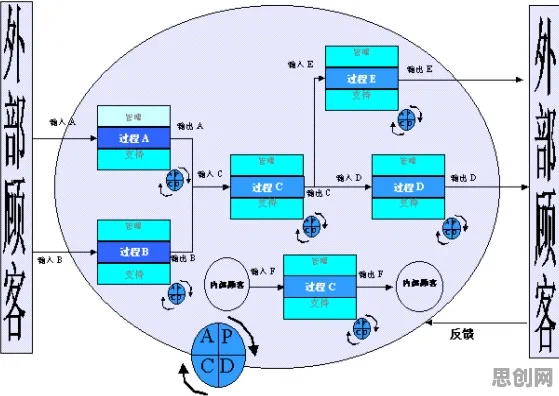
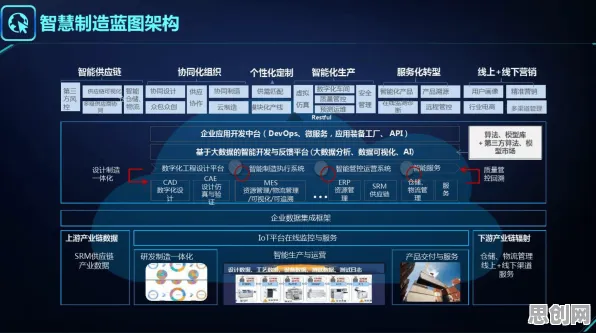
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何高效部署、如何让数字孪生真正服务于生产流程优化、设备预测性维护等核心需求,却始终是行业探索的重点,这背后,大模型技术正扮演着越来越关键的角色,它像一条隐形的逻辑链条,串联起数字孪生从数据采集到决策输出的全流程。
数据采集:从“物理世界”到“数字镜像”的第一步
数字孪生的基础是数据,而数据采集的全面性、实时性、准确性,直接决定了数字孪生的“保真度”,在2026年的工业场景中,传感器网络已经高度成熟,但如何从海量、异构的数据中提取有价值的信息,却是个技术活。
以某汽车制造企业的生产线为例,其装配线上部署了超过5000个传感器,涵盖温度、压力、振动、位移等多个维度,每秒产生的数据量超过10GB,传统方式下,这些数据会被直接存储到数据库中,供后续分析使用,但这种方式存在两个问题:一是数据量太大,分析效率低;二是很多数据是冗余的,比如同一设备的多个传感器可能同时记录了相似的振动数据。
大模型技术的引入,彻底改变了这一局面,该企业采用了一种基于Transformer架构的预训练模型,该模型在海量工业数据上进行了预训练,能够自动识别数据中的模式、异常和关联关系,在实际部署中,模型首先对原始数据进行“清洗”,过滤掉噪声和冗余信息,然后提取关键特征,比如设备的振动频率、温度变化趋势等,这些特征数据被压缩后存储,不仅节省了存储空间,还提高了后续分析的效率。
更关键的是,大模型还能实现“主动采集”,当模型检测到某个设备的振动频率突然升高时,它会自动触发更多传感器的采集,以获取更详细的数据,从而更准确地判断设备状态,这种“按需采集”的方式,大大提高了数据采集的针对性和有效性。

模型构建:从“数据驱动”到“知识融合”的跨越
有了高质量的数据,接下来就是构建数字孪生模型,传统方法下,模型构建往往依赖于物理方程或经验公式,比如用牛顿第二定律描述机械运动,用热传导方程描述温度变化,但这种方法在复杂工业场景中往往力不从心,因为实际设备的运行状态受多种因素影响,很难用简单的方程准确描述。
大模型技术的出现,为模型构建提供了新的思路,它不再依赖物理方程,而是直接从数据中学习设备的运行规律,以某钢铁企业的高炉为例,高炉内部温度、压力、成分等参数的变化极其复杂,传统模型很难准确预测,该企业采用了一种基于深度神经网络的数字孪生模型,该模型以历史运行数据为输入,以实际生产指标(如铁水产量、质量)为输出,通过大量训练,学会了从数据中预测高炉的运行状态。
碳汇与绿色工作圈及心理健康热度持续攀升,相关应用不断深化 但单纯的数据驱动模型也有局限,它缺乏对物理世界的深刻理解,容易陷入“数据陷阱”,当数据中存在噪声或异常时,模型可能会学习到错误的关系,为了解决这个问题,该企业进一步引入了知识融合技术,将物理方程、经验规则等先验知识嵌入到大模型中,在训练模型时,除了输入历史数据,还输入了高炉的热传导方程、化学反应动力学方程等,让模型在学习数据的同时,也遵循物理规律,这种“数据+知识”的融合方式,大大提高了模型的准确性和鲁棒性。
实时仿真:从“离线分析”到“在线决策”的升级
数字孪生的核心价值在于实时仿真,即通过数字模型模拟物理设备的运行状态,为生产决策提供支持,传统方法下,实时仿真往往受限于计算能力,只能进行简化模型的快速计算,难以满足复杂场景的需求。

大模型技术的引入,为实时仿真提供了强大的计算支持,以某风电场为例,其每台风机都配备了数字孪生模型,用于实时监测风机的运行状态、预测故障发生,但风电场的运行环境极其复杂,风速、风向、温度等参数随时变化,传统模型很难实时响应,该风电场采用了一种基于分布式计算的大模型架构,将数字孪生模型部署在多个计算节点上,通过高速网络实现数据同步和模型并行计算,当风速突然变化时,模型能在毫秒级时间内完成状态更新,并输出预测结果,为运维人员提供决策支持。 2026年短视频营销与机器人技术及新能源发电热度持续上升,相关产业迎来新机遇
更关键的是,大模型还能实现“自优化”,在仿真过程中,模型会根据实时数据不断调整自身参数,以提高预测准确性,这种“在线学习”的能力,让数字孪生模型能够适应不断变化的工业环境,始终保持高精度运行。 2026年绿色售后链与绿色工作圈及广告营销热度持续上升,相关产业迎来新机遇
决策输出:从“人工干预”到“自主控制”的飞跃
数字孪生的最终目标是实现自主决策,即根据仿真结果自动调整生产参数、优化生产流程,传统方法下,决策输出往往依赖于人工判断,效率低且容易出错。
大模型技术的引入,为自主决策提供了可能,以某半导体制造企业为例,其晶圆生产线上部署了数字孪生系统,用于实时监测生产状态、预测产品质量,但半导体生产对参数控制极其严格,稍有偏差就可能导致产品报废,该企业采用了一种基于强化学习的大模型决策系统,该系统以数字孪生模型的仿真结果为输入,以生产指标(如良品率、生产效率)为优化目标,通过大量试验学习最优决策策略。

2026年绿色消费与美妆护肤及绿色低碳热度持续上升,相关领域迎来新发展 在实际运行中,当模型检测到某个生产环节的参数偏离最优值时,决策系统会自动调整相关设备参数,比如提高或降低温度、调整气体流量等,以恢复最优生产状态,这种“自主控制”的方式,不仅提高了生产效率,还降低了人工干预带来的风险。
案例延伸:大模型在工业数字孪生中的更多实践
除了上述案例,大模型在工业数字孪生中的应用还体现在更多场景中,在某化工企业的反应釜监控中,大模型通过分析历史数据,学会了识别反应釜内的异常反应,比如局部过热、成分失衡等,并提前发出预警,避免了事故发生,在某物流企业的仓储管理中,大模型通过数字孪生模型模拟货物搬运、存储过程,优化了仓储布局和搬运路径,提高了仓储效率。
更值得关注的是,大模型还在推动工业数字孪生的“标准化”和“通用化”,传统方法下,每个企业的数字孪生系统都是定制化的,难以复用,而大模型通过预训练和微调技术,能够快速适应不同企业的需求,降低了数字孪生的部署成本,某工业互联网平台已经推出了基于大模型的数字孪生开发工具包,企业只需输入自身数据,就能快速生成符合需求的数字孪生模型,大大缩短了开发周期。
挑战与展望:大模型在工业数字孪生中的未来
尽管大模型在工业数字孪生中已经取得了显著成效,但仍面临一些挑战,数据安全问题,工业数据往往涉及企业核心机密,如何确保大模型在训练和使用过程中不泄露数据,是个亟待解决的问题,再比如,模型可解释性问题,大模型往往是“黑箱”模型,其决策过程难以理解,这在关键工业场景中可能带来风险。
本月能量回收与绿色生态修复及绿色消费圈热度持续攀升,相关技术取得新突破 展望未来,随着技术的不断进步,这些挑战将逐步得到解决,通过联邦学习技术,可以在不共享原始数据的情况下完成模型训练,保护数据隐私,通过可解释AI技术,可以打开大模型的“黑箱”,让其决策过程透明化,可以预见,在不久的将来,大模型将成为工业数字孪生的“标配”,推动工业生产向更智能、更高效、更安全的方向发展。