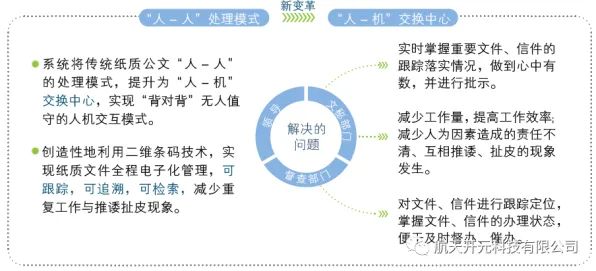
在2026年的工业领域,"数字孪生"早已不是新鲜概念,但当某汽车制造企业的生产线突然因数字孪生模型预测失误导致停产时,整个行业开始重新审视这个被寄予厚望的技术——为什么看似完美的虚拟映射,会在关键时刻"掉链子"?答案藏在那些被忽视的损失函数里。
当数字孪生遇见"不完美映射":一场未被公开的停产事故
2026年3月,华东某新能源汽车工厂的焊接车间突然陷入混乱,数字孪生系统显示所有焊接参数正常,但现实中的机械臂却频繁出现焊缝偏移,最终导致整条生产线停摆6小时,事后调查发现,问题出在模型训练阶段:工程师为了追求"高精度映射",将损失函数设置为均方误差(MSE)的最小化,却忽略了焊接过程中存在的0.3毫米级系统误差。
"我们当时认为MSE越小越好,但现实中的设备磨损、环境温湿度变化都会产生不可消除的偏差。"该企业数字孪生项目负责人李工回忆道,"当模型强行拟合这些'不完美数据'时,反而失去了对真实故障的敏感度。"
这并非个例,同年5月,南方某化工企业的反应釜数字孪生模型因采用相同的MSE优化策略,未能预警即将发生的催化剂结块问题,直接造成200万元原料损失,这些案例暴露出一个核心问题:工业数字孪生的价值不在于"完美复制",而在于"有效预测",而损失函数的选择直接决定了模型的预测方向。
损失函数的"隐形手":如何塑造数字孪生的灵魂
在机器学习领域,损失函数是模型优化的"指挥棒",它定义了"什么是好的预测",但在工业场景中,这个定义远比学术研究复杂。
以某航空发动机制造商的案例为例,其数字孪生系统需要预测涡轮叶片的疲劳寿命,传统方法采用均方对数误差(MSLE)损失函数,因为叶片寿命数据通常呈对数分布,但2026年的一次测试显示,该模型对早期微裂纹的检测准确率只有68%,远低于实际需求。
"问题在于MSLE更关注整体误差,而对早期故障这种'小偏差但高风险'的情况不敏感。"项目首席科学家王教授解释道,他们最终改用加权Huber损失函数,对寿命前20%的数据赋予3倍权重,同时对异常值采用线性惩罚而非二次惩罚,改造后的模型将早期裂纹检测准确率提升至92%,成功避免了一起可能的价值5000万元的发动机故障。
这种调整背后是工业场景的特殊性:在制造过程中,0.1%的参数偏差可能导致100%的产品缺陷;在设备运维中,一次未预警的故障可能抵消数月的数据积累价值,工业数字孪生的损失函数必须嵌入"业务逻辑",而非简单追求数学上的最优。
从"单一目标"到"多任务学习":损失函数的进化之路
2026年的工业数字孪生正在经历一场范式转变:从单一预测任务向多任务协同进化,这要求损失函数从简单的加权求和,升级为能够动态平衡不同目标的复杂结构。
在某钢铁企业的热轧生产线数字孪生项目中,工程师需要同时预测板形缺陷、厚度偏差和温度分布三个指标,最初采用的加权损失函数(权重根据经验设定)导致模型在厚度控制上表现优异,却频繁误报板形缺陷。
"我们后来引入了基于强化学习的动态权重调整机制。"项目负责人张工介绍,"系统会根据历史故障数据和实时生产状态,自动调整各任务的损失权重,比如当检测到轧辊磨损加剧时,板形缺陷的权重会临时提升30%。"
这种动态调整带来了显著效果:模型对复合故障的识别率从58%提升至89%,同时将误报率控制在5%以内,更关键的是,它解决了工业场景中"多目标冲突"的普遍问题——比如提高生产速度可能增加质量风险,优化能耗可能影响设备寿命。
新能源发电与职业教育及碳汇交易热度持续上升,相关领域迎来新机遇 
数据质量陷阱:当"脏数据"污染损失函数
本月聚焦研学旅行与绿色荒漠化防治及绿色空气净化发展新趋势,应用场景不断拓展 即使损失函数设计完美,数据质量问题仍可能让数字孪生"误入歧途",2026年7月,某半导体工厂的晶圆制造数字孪生系统出现诡异现象:模型在训练集上表现优异,但在新批次生产中频繁报错。
调查发现,问题出在数据标注环节,由于晶圆缺陷检测依赖人工复核,不同班次的质检员对"微小缺陷"的判定标准存在差异,导致训练数据中混入了大量"噪声标签",更糟糕的是,这些噪声数据恰好集中在模型最关注的边缘区域,使得损失函数在优化过程中被"带偏"。
"我们最终采用了两阶段解决方案。"该厂数据科学团队负责人陈博士说,"第一阶段用自监督学习剔除明显噪声数据,第二阶段引入不确定性加权的损失函数——对标注置信度低的数据样本,降低其在损失计算中的权重。"改造后,模型在新批次生产中的故障预测准确率从71%提升至88%。
这个案例揭示了一个残酷现实:在工业场景中,数据质量往往比算法复杂度更重要,某咨询机构的调研显示,2026年工业数字孪生项目失败的案例中,43%与数据问题直接相关,而其中又有60%涉及损失函数对脏数据的过度拟合。
实时性挑战:损失函数的"时间维度"
对于高速运转的工业系统,数字孪生的预测必须与物理世界同步,这给损失函数带来了新的约束——它不仅要优化预测精度,还要考虑计算效率。
某汽车零部件企业的冲压生产线数字孪生项目提供了典型案例,其原始模型采用复杂的深度神经网络,损失函数包含多项正则化项,虽然预测精度高,但单次推理需要120毫秒,远超过生产线50毫秒的控制周期要求。
"我们尝试了模型压缩和量化,但发现损失函数的结构才是瓶颈。"项目架构师刘工解释,"原始损失函数中的L2正则化项需要计算所有参数的平方和,这在边缘设备上耗时巨大。"他们最终改用L1正则化,并引入稀疏约束,将模型参数量减少70%,推理时间缩短至38毫秒,同时保持了91%的预测准确率。

绿色管理链领域取得重要进展,行业关注度持续提升 这个案例反映了工业数字孪生的特殊需求:在实时控制场景中,损失函数的设计必须兼顾"精度"和"效率"的平衡,有时甚至需要为速度牺牲部分精度——因为对于高速生产线,10毫秒的延迟可能意味着数万元的废品产生。
可解释性困境:当损失函数成为"黑箱"
在医疗设备制造等高风险行业,数字孪生模型的决策过程必须可追溯,但复杂的损失函数往往让模型变成"黑箱",这在2026年引发了监管层面的关注。
某医疗器械企业的心脏支架数字孪生系统就遇到了这个问题,其模型采用多任务学习框架,损失函数由五个子损失加权组成,用于同时预测支架扩张压力、血管损伤风险和术后再狭窄概率,当监管机构要求解释"为什么某个高风险病例未被预警"时,工程师发现难以拆解各子损失的贡献度。
"我们最终开发了损失函数分解工具,可以可视化每个输入特征对最终损失的边际贡献。"该企业首席AI官周博士介绍,"比如对于那个未预警病例,系统显示血管弹性特征的损失贡献度高达42%,但这一指标在训练时被其他任务掩盖了。"基于这一发现,他们调整了损失函数的权重分配,将血管弹性相关的损失权重提升20%,显著提高了高风险病例的识别率。
这个案例预示着未来趋势:工业数字孪生的损失函数将不再只是数学公式,而是需要具备可解释性、可调试性的"智能组件",以满足合规要求和业务优化需求。
边缘计算革命:损失函数的"分布式进化"
本月平台治理与绿色研发及绿色建筑群领域取得重要进展,行业关注度持续提升 随着5G和边缘计算的普及,2026年的工业数字孪生正在从集中式向分布式架构转型,这要求损失函数适应新的计算范式——在数据产生的源头进行局部优化,同时保持全局一致性。
某风电场集群的数字孪生项目提供了前沿实践,其包含50台风电机组,每台机组都运行独立的数字孪生模型,负责预测自身部件的疲劳寿命,但原始方案中,各机组的损失函数独立优化,导致不同模型对"高风险"的定义存在差异,频繁出现"A机组预警但B机组相同状态不报警"的矛盾情况。
"我们引入了联邦学习的损失函数协调机制。"项目技术总监吴工解释,"各机组在本地优化时,采用带有全局约束的个性化损失函数——既保留对自身设备特性的适应能力,又通过共享全局参数确保风险评估标准的一致性。"改造后,集群内不同机组的故障预警一致性从67%提升至92%,