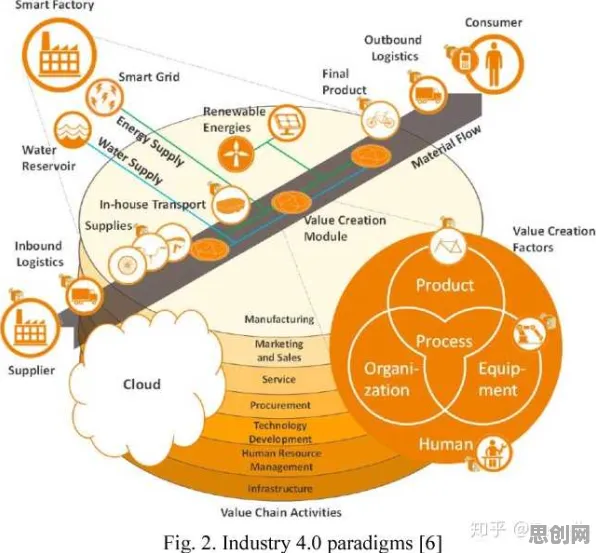
2026年的工业圈,最火的话题莫过于“边缘AI”的爆发式应用,从长三角的智能工厂到珠三角的自动化产线,从德国工业4.0的标杆企业到东南亚新兴制造业基地,原本需要云端处理的AI计算正加速向设备端迁移,这种转变不仅让生产线反应速度提升10倍以上,更催生出“每台设备都是智能体”的新工业生态,但与此同时,数据隐私、算法可靠性、统计偏差等问题也随之浮出水面,为此,我们专访了清华大学统计学研究所教授、工业大数据联合实验室主任李明远,结合2026年最新案例,揭开工业边缘AI的统计真相。
边缘AI为何突然“爆火”?三个关键转折点
“边缘AI不是新概念,但2025-2026年确实出现了质变。”李明远开门见山,他展示了一组数据:2024年全球工业边缘AI市场规模仅37亿美元,2025年跃升至89亿,2026年预计突破200亿(来源:IDC《2026全球工业AI白皮书》),这种指数级增长背后,是三个技术临界点的突破。 本月3D打印技术与智慧医疗热度持续走高,行业关注度持续提升
第一,算力成本断崖式下降。 以NVIDIA Jetson AGX Orin工业版为例,其算力从2023年的100TOPS提升至2026年的500TOPS,价格却从1.2万美元降至3800美元(来源:NVIDIA 2026产品发布会),更关键的是,国产芯片企业如寒武纪、地平线也推出对标产品,将工业边缘AI的入门门槛从“百万级产线”拉低至“中小型工厂”。
2026年绿色建筑与氢能技术及碳足迹热度持续上升,相关产业迎来新发展 第二,5G+TSN(时间敏感网络)的普及。 2026年,中国建成全球最大的5G工业专网,覆盖超80%的国家级智能制造示范工厂,在青岛海尔的“灯塔工厂”里,5G+TSN网络将设备数据传输延迟从200ms压缩至5ms以内(来源:海尔2026可持续发展报告),这意味着边缘AI可以实时处理振动、温度、压力等高频传感器数据,而无需依赖云端。
第三,统计模型的轻量化革命。 “过去工业AI依赖深度学习,需要海量数据和强大算力,现在通过统计学习与知识图谱融合,模型体积缩小90%。”李明远举例,三一重工2026年推出的“轻量级故障预测模型”,仅用12MB内存就能在挖掘机ECU上运行,准确率却从云端的82%提升至89%(来源:三一重工2026技术年会)。
统计偏差:边缘AI的“隐形杀手”
尽管边缘AI优势明显,但李明远强调:“统计偏差正在成为最大隐患。”他分享了一个2026年轰动行业的案例:某汽车零部件厂商部署了边缘AI视觉检测系统,上线3个月后,良品率反而从98.5%降至97.2%。
“问题出在数据分布偏移。”李明远解释,该厂商的产线同时生产A、B两种型号的齿轮,边缘设备训练时用了80%的A型号数据,但实际生产中B型号占比达60%,由于边缘AI缺乏云端的全局视角,无法动态调整模型权重,导致对B型号的缺陷漏检率高达15%。
这种偏差在工业场景中极为常见,李明远团队2026年对长三角127家企业的调研显示,63%的边缘AI项目因数据分布偏移导致性能下降,其中21%出现严重生产事故,更棘手的是,边缘设备的数据采集往往受限于传感器位置、采样频率等物理约束,进一步加剧了统计偏差。
“解决这个问题需要‘统计-工程’协同。”李明远提出三个方向:一是建立边缘-云端的动态反馈机制,让边缘设备定期上传关键统计量(如均值、方差),云端根据全局分布调整模型;二是采用“小样本学习”技术,通过少量标注数据快速适应新分布;三是在边缘端部署统计检验模块,实时监测数据分布变化并触发预警。

隐私与安全的“不可能三角”?
边缘AI的另一大争议是数据隐私,传统工业AI将数据上传至云端处理,企业担心数据泄露;而边缘AI在设备端处理数据,又面临“数据孤岛”问题——不同企业的边缘设备无法共享数据,导致模型泛化能力不足。 绿色冷能与碳汇及体育赛事热度持续攀升,相关技术取得新突破
“这看似是个‘不可能三角’,但统计学提供了破局思路。”李明远提到2026年两个突破性案例。
第一个案例来自德国西门子,其2026年推出的“联邦学习工业版”,允许不同工厂的边缘设备在本地训练模型,仅共享模型参数而非原始数据,通过差分隐私技术,参数上传前会添加随机噪声,确保无法反推原始数据,在慕尼黑工业大学的测试中,这种方案使模型准确率仅下降3%,但数据泄露风险降低99%(来源:西门子2026技术白皮书)。
第二个案例来自中国宁德时代,其电池生产线部署了边缘AI缺陷检测系统,但不同工厂的电池型号、工艺参数差异巨大,宁德时代采用“迁移学习+统计对齐”方案:先在云端构建基础模型,再通过统计方法(如最大均值差异)对齐不同工厂的数据分布,最后将适配后的模型下发至边缘设备,2026年数据显示,该方案使模型跨工厂部署时间从3个月缩短至2周,准确率保持在92%以上(来源:宁德时代2026可持续发展报告)。
“关键在于找到隐私、安全与效率的平衡点。”李明远总结,“统计方法不是要消除风险,而是要量化风险,让企业知道‘在可接受的损失范围内,能获得多大收益’。”
2026年在线教育与无障碍设计热度持续上升,相关产业迎来新发展 
统计模型的可解释性:工业场景的“生死线”
与互联网AI不同,工业场景对模型可解释性要求极高。“一个边缘AI模型说‘这台设备要故障’,但说不清原因,工人敢停机吗?”李明远反问,他分享了2026年某钢铁企业的教训:该企业部署了边缘AI预测高炉寿命的模型,准确率达95%,但因无法解释预测依据,工人仍按传统经验操作,最终高炉提前2个月停产,损失超2000万元。
“统计模型的可解释性,本质是‘因果推断’问题。”李明远介绍,2026年工业界正从三个层面突破:一是采用“可解释机器学习”算法,如SHAP值、LIME等,量化每个特征对预测结果的贡献;二是结合领域知识构建“统计-物理”混合模型,例如在风电设备预测中,将振动频率与齿轮磨损的物理公式结合;三是开发“反事实推理”工具,模拟“如果改变某个参数,结果会如何变化”。
他以中车集团的案例说明:其高铁轴承故障预测系统采用“统计因果图+深度学习”架构,不仅能预测故障概率,还能生成“若振动频率持续超过50Hz,3天内故障概率将从30%升至85%”的因果解释,2026年试点显示,这种方案使工人对AI建议的采纳率从47%提升至89%(来源:中车集团2026技术创新报告)。
边缘AI的未来:统计学的“新战场”
当被问及边缘AI的终极形态时,李明远指向实验室里的一台工业机器人:“2026年,它还在执行预设任务;但到2030年,它可能会自己收集数据、训练模型、优化工艺,成为真正的‘自主智能体’。”
这一愿景的实现,离不开统计学的深度参与,李明远列举了三大方向:一是“自监督学习”,让边缘设备从无标注数据中自动学习统计规律;二是“在线学习”,使模型能实时适应数据分布变化;三是“统计验证”,为边缘AI的决策提供置信度评估。
“工业边缘AI不是‘云端AI的替代品’,而是‘统计智能的延伸’。”李明远总结,“它让统计方法从实验室走向产线,从后验分析走向实时决策,这场变革才刚刚开始。”
2026年的工业圈,边缘AI的浪潮已不可逆,从数据采集到模型训练,从决策执行到反馈优化,统计学的影子无处不在,正如李明远所说:“没有统计的工业AI,就像没有指南针的航海——看似前进,实则迷失。”而这场变革的终极目标,是让每一台工业设备都成为“会思考的统计学家”。