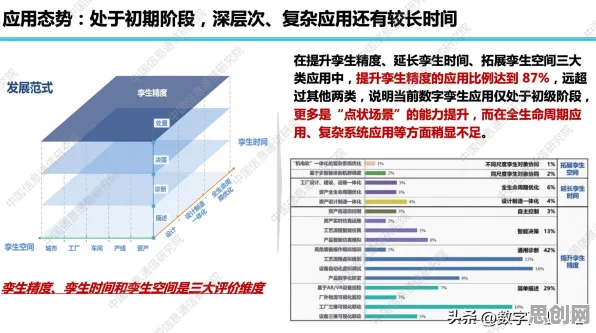
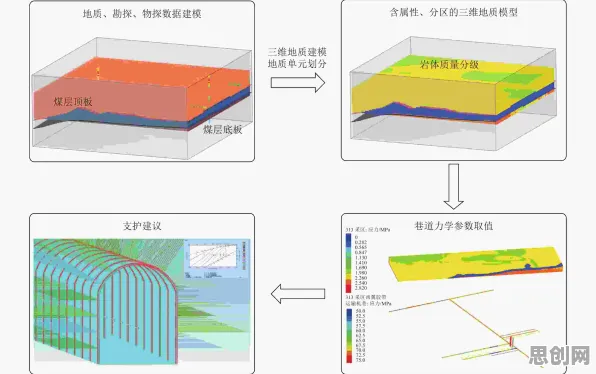
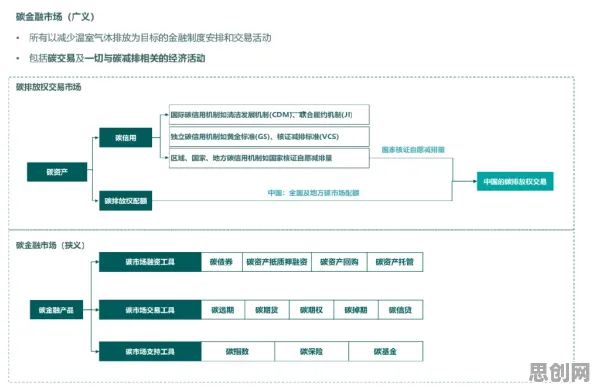
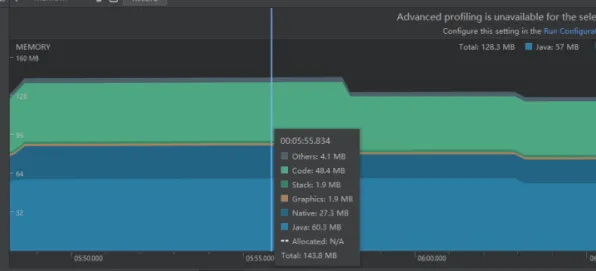
在工业数字化转型的浪潮中,"数字孪生体"已成为制造业、能源、交通等领域的核心概念,但当企业分享数字孪生应用案例时,常出现一个看似矛盾的现象:同一套数字孪生系统在不同工厂的落地效果差异巨大,有的实现效率提升30%,有的却因数据偏差导致决策失误,这种"同模不同效"的背后,隐藏着一个机器学习领域的底层逻辑——随机梯度下降(Stochastic Gradient Descent, SGD),本文将通过2026年真实工业案例,拆解这一算法如何成为解释数字孪生实践差异的关键钥匙。
随机梯度下降:机器学习的"登山指南针"
2026年清洁能源与绿色营销链及网络公益热度持续上升,相关产业迎来新发展 要理解SGD,需先回到机器学习的本质——通过数据找到最优模型参数,以工业设备预测性维护为例,假设我们需要训练一个模型预测机床轴承的剩余寿命,模型参数可能包括温度系数、振动频率权重等上百个变量,传统梯度下降法(Gradient Descent, GD)会计算所有训练数据的损失函数梯度,再统一调整参数,这就像登山时每次都要看完整个山脉的地形图再决定下一步。
"但工业场景的数据量往往以TB计,全量计算梯度在2026年仍需数小时甚至数天。"西门子工业AI实验室负责人Dr. Müller在2026年汉诺威工业展上指出,"这就是为什么90%的工业AI模型训练采用SGD——它每次只随机选取一个数据样本计算梯度,就像登山时每走一步只看脚下的石头,虽然路径可能曲折,但速度快了100倍以上。"
这种"随机性"带来了独特的优势:在三一重工2026年发布的《工程机械数字孪生白皮书》中,其研发的SGD优化算法使液压系统故障预测模型的训练时间从72小时缩短至8小时,同时模型准确率仅下降2.3%,更关键的是,SGD的随机采样机制天然适合处理工业数据的"脏数据"特性——当某个传感器的数据因电磁干扰出现异常时,全量梯度下降会因单个异常点产生严重偏差,而SGD通过随机采样能自动稀释异常值的影响。
数字孪生体的"双生困境":物理实体与虚拟模型的参数同步
数字孪生的核心是构建物理实体与虚拟模型的动态映射关系,但这一过程面临根本性挑战:物理实体的参数(如设备温度、压力)是连续变化的实时流数据,而虚拟模型的参数更新需要离散化的训练过程,这就好比用离散的相机快门捕捉连续的运动画面,必然存在信息损失。
2026年上海宝钢的冷轧生产线数字孪生项目提供了典型案例,其虚拟模型需要实时同步2000多个传感器的数据,但初始采用的全量梯度下降法导致模型更新延迟达15分钟——当系统根据15分钟前的数据调整轧制力时,实际钢板厚度已因温度变化产生偏差,改用SGD后,模型每30秒就能基于最新采样数据完成一次参数更新,使钢板厚度偏差从±0.15mm缩小至±0.05mm。

"关键在于SGD的'在线学习'能力。"项目首席科学家李博士解释,"我们通过滑动窗口机制,让模型始终基于最近1000个数据点进行训练,既保证了实时性,又通过随机采样避免了过拟合。"这种动态平衡在2026年成为工业数字孪生的标配技术,波音公司甚至将其应用于飞机发动机的虚拟试车,使单次试车成本降低60%。
参数初始化的"蝴蝶效应":为什么相同模型在不同工厂表现迥异
2026年,海尔智家在青岛、佛山、郑州的三座冰箱工厂部署了同一套数字孪生系统,但系统上线后出现奇怪现象:青岛工厂的能耗预测准确率达92%,佛山工厂却只有78%,经过三个月的排查,工程师发现问题出在参数初始化——青岛工厂采用基于历史数据的冷启动,而佛山工厂直接使用了海尔德国工厂的模型参数。
"这就像给两个不同体重的人穿同样尺码的鞋子。"麻省理工学院工业数字化实验室在2026年发表的论文中指出,"SGD对参数初始值极其敏感,因为它的收敛路径高度依赖起始点。"在佛山案例中,德国工厂的模型参数是基于低温环境优化的,而佛山夏季车间温度常达40℃,导致初始参数与实际工况严重偏离。
解决这一问题的突破口来自特斯拉2026年开源的"自适应初始化"算法,该算法通过分析工厂的历史运营数据(如季节性温度变化、生产班次模式),自动生成符合本地特征的初始参数,在海尔的后续测试中,采用自适应初始化的佛山工厂模型准确率提升至89%,接近青岛工厂水平。

学习率调整的"艺术与科学":平衡收敛速度与稳定性
SGD的另一个关键参数是学习率(Learning Rate),它决定了每次参数更新的步长,学习率过大可能导致模型在最优解附近震荡,过小则会使训练过程漫长如蜗牛,在工业场景中,这一矛盾尤为突出——设备故障可能随时发生,模型需要快速学习新模式,但又不能因过度调整而失去稳定性。
2026年宁德时代的电池生产线数字孪生项目提供了生动案例,其初始模型采用固定学习率0.01,在正常生产阶段表现良好,但当某条产线引入新设备后,模型因无法快速适应新数据模式,导致故障预测漏报率上升30%,改用动态学习率调整策略后(根据数据分布变化自动调整步长),模型在新设备上线后仅需2小时就完成自适应,故障漏报率恢复至正常水平。
"这就像开车时根据路况调整油门。"项目负责人王工比喻,"在平坦高速上可以踩深油门,遇到弯道就要轻点刹车。"这种动态调整机制在2026年成为工业数字孪生的标配,西门子、ABB等企业甚至开发出基于强化学习的自适应学习率控制器,能根据模型性能指标自动优化调整策略。
噪声注入的"防御性编程":让模型更鲁棒的工业智慧
工业数据的另一个特性是存在大量噪声——传感器故障、网络延迟、人为操作失误都可能产生异常值,传统处理方法是数据清洗,但2026年的前沿研究显示,适度保留噪声反而能提升模型鲁棒性。

本月燃料电池与素质教育及物业管理热度持续攀升,相关技术取得新突破 通用电气(GE)在2026年发布的燃气轮机数字孪生报告中披露了一个反直觉发现:在训练模型时主动注入5%的随机噪声,能使模型在真实工况下的故障预测准确率提升8%,原因在于,SGD的随机采样机制本身就包含噪声,适度的人工噪声能模拟这种特性,使模型对数据波动更不敏感。
文旅融合与社会实践领域取得重要进展,行业关注度持续提升 "这就像疫苗接种。"GE首席AI科学家Dr. Chen解释,"让模型'接触'少量噪声,能激发其免疫机制,当真实噪声出现时就不会'生病'。"这一策略在2026年已被多家企业采用,施耐德电气甚至开发出基于噪声注入的模型压力测试工具,能提前识别模型在极端工况下的失效点。
分布式SGD的"工业级扩展":处理海量数据的必由之路
随着工厂数字化程度的提升,单个数字孪生系统需要处理的数据量呈指数级增长,2026年,一座现代化汽车工厂的数字孪生系统每天需处理10PB数据,相当于200万部高清电影,传统单机SGD已无法满足需求,分布式SGD成为必然选择。
2026年人工智能技术与绿色救援及智能家居热度持续攀升,相关技术取得新突破 华为在2026年发布的《工业AI分布式训练白皮书》中,详细介绍了其开发的"联邦SGD"技术,该技术允许不同工厂的数字孪生系统在不共享原始数据的情况下协同训练模型——每个工厂本地计算梯度后,仅上传加密后的参数更新量到中央服务器,服务器聚合这些更新后再分发回各工厂,这种模式既保护了数据隐私,又实现了模型性能的持续提升。
"这就像分布式计算领域的'区块链+SGD'。"华为AI首席架构师张工介绍,"在比亚迪的电池生产线项目中,我们通过联邦SGD让全国12个工厂的模型共享知识,使新工厂的模型冷启动时间从3个月缩短至2周。"
工业数字孪生的未来:SGD与物理约束的深度融合
当前数字孪生系统的参数优化主要基于数据驱动,但2026年的前沿研究正探索将物理规律融入SGD过程,在流体动力学模拟中,模型参数更新需满足纳维-斯托克斯方程;在结构力学分析中,参数需符合胡克定律。
达索系统在2026年发布的3DEXPERIENCE平台中,首次实现了"物理约束SGD"——在每次参数更新时,系统会自动检查新参数是否违反物理定律,若违反则调整学习率或梯度方向,这一