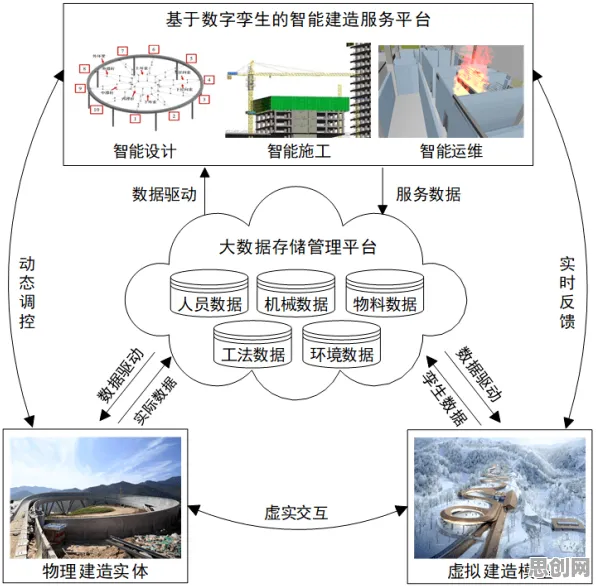
在2026年的智能制造浪潮中,工业数字孪生系统已从概念验证阶段迈向规模化部署,全球制造业巨头西门子、通用电气(GE)和三一重工的最新实践显示,数字孪生与迁移学习的深度融合正在重塑工业AI的落地路径,当一家汽车工厂需要为新车型快速构建数字孪生体时,传统方法需重新采集数万组传感器数据并训练模型,而基于迁移学习的技术方案可将跨车型、跨工厂的知识复用率提升至85%以上——这种效率跃迁背后,是迁移学习在工业场景中突破"数据孤岛"的关键作用。
工业数字孪生部署中的数据困境与迁移学习破局
三一重工长沙"灯塔工厂"的案例极具代表性,2026年初,该厂计划将一条挖掘机装配线改造为电动工程机械生产线,传统数字孪生方案需重新部署2000多个物联网传感器,并花费3个月训练生产仿真模型,但通过迁移学习技术,工程师将现有燃油机型装配线的历史数据(包括设备振动、温度、能耗等10万组时序数据)与新产线的CAD模型进行特征对齐,仅用2周就完成了数字孪生体的初始化,更关键的是,当新产线出现螺栓拧紧扭矩异常时,系统自动从燃油机型的故障数据库中匹配到相似案例,将问题定位时间从4小时缩短至20分钟。
这种跨机型知识迁移的背后,是工业领域特有的数据特性决定的,据麦肯锡2026年全球工业AI调研显示,单个工厂每年产生的工业数据量达PB级,但其中72%属于"暗数据"——未被标注且难以直接利用,迁移学习的核心价值在于,它允许模型从A产线的标注数据中学习通用特征(如设备磨损模式、工艺参数关联性),再将这些知识迁移到B产线的未标注数据上,GE航空发动机部门在2026年部署的数字孪生系统中,通过迁移学习将涡轮叶片缺陷检测模型的训练数据需求减少了90%,而模型准确率反而提升了3个百分点。

从模型迁移到领域自适应:工业场景的深度进化
迁移学习在工业领域的应用正经历从"浅层迁移"到"深度自适应"的质变,以宝钢股份2026年上线的智能炼钢系统为例,传统方法需为每座转炉单独训练温度控制模型,而新系统采用基于对抗生成网络(GAN)的领域自适应技术,将上海基地转炉的10万组操作数据迁移到湛江基地的新转炉上,关键创新在于引入"领域判别器":当模型试图直接套用上海数据时,判别器会识别出湛江基地原料成分(如铁矿石品位差异)导致的特征分布偏移,并通过梯度反转层强制模型学习跨域不变特征,最终实现模型迁移后,湛江转炉的钢水温度波动范围从±15℃缩小至±5℃,吨钢能耗降低8%。
2026年养老产业与电子商务热度持续上升,相关产业迎来新发展 这种深度自适应能力在半导体制造领域更为关键,中芯国际2026年发布的12英寸晶圆厂数字孪生平台,解决了光刻机参数迁移的行业难题,不同厂商的光刻机在光源波长、镜头畸变等参数上存在微小差异,传统迁移学习会因这些"协变量偏移"导致模型失效,中芯团队采用"条件迁移学习"框架,将光刻机参数作为条件变量输入特征提取网络,同时构建参数-成像质量的映射关系库,当新光刻机接入系统时,模型可自动查询参数库并调整特征权重,使得跨设备的光刻胶涂布厚度预测误差从±0.3μm降至±0.05μm。

边缘计算与迁移学习的工业级融合
2026年的工业现场正涌现出"边缘迁移学习"的新范式,西门子安贝格电子制造工厂的实践具有标杆意义:该厂部署了500多个边缘计算节点,每个节点运行轻量化迁移学习模型,负责局部设备的故障预测,当某台贴片机出现新型元件抛料问题时,边缘节点首先用本地数据训练一个基础模型,再通过工厂内网从其他相似贴片机节点获取增量数据(如吸嘴压力、供料器振动等特征),通过联邦迁移学习技术实现模型协同优化,整个过程无需将数据上传至云端,既保护了商业机密,又将模型迭代速度从天级缩短至小时级。
这种部署模式在流程工业中更具价值,万华化学烟台基地的裂解装置数字孪生系统,通过边缘迁移学习解决了原料性质波动大的难题,不同批次的石脑油在密度、芳烃含量等指标上差异显著,传统模型需频繁重新训练,万华团队在每个加热炉的边缘控制器上部署迁移学习模块,当新批次原料进入时,系统自动从历史批次中筛选相似工况的数据(如进料流量、炉膛温度等10个关键参数),通过微调最后一层全连接层实现模型快速适配,2026年运行数据显示,该方案使裂解炉运行周期延长了15%,乙烯收率波动降低40%。

跨行业迁移:工业AI的生态化突破
迁移学习的真正潜力在于打破行业边界,2026年,波音公司与宁德时代开展了一项跨界合作:将电池制造中的缺陷检测知识迁移到飞机复合材料检测场景,波音发现,锂电池极片涂布缺陷(如褶皱、露箔)与飞机碳纤维铺层缺陷(如分层、孔隙)在图像特征空间存在相似性,通过构建跨行业特征库,宁德时代的缺陷检测模型经少量飞机数据微调后,即可识别出直径0.1mm的碳纤维缺陷,检测速度比传统X射线检测快20倍,这种跨界迁移不仅降低了航空业的AI应用门槛,也为电池行业开辟了新的质量管控思路。 低碳办公与节能减排热度持续上升,相关领域迎来新发展
2026年新能源汽车与垃圾分类热度持续上升,相关产业迎来新机遇 在能源领域,国家电网的实践更具战略意义,其2026年推出的"电力-工业"迁移学习平台,将风电场功率预测模型迁移至钢铁企业余热发电场景,风电预测需处理气象数据与功率输出的非线性关系,而余热发电受工艺参数影响更大,国网团队采用"多任务迁移学习"架构,让模型同时学习风电和余热的特征表示,通过共享底层网络捕捉能源转换的通用规律,实际应用显示,该方案使余热发电功率预测误差从12%降至6%,帮助钢厂每年减少购电量1.2亿千瓦时。
技术挑战与未来路径
尽管成就显著,工业迁移学习仍面临三大挑战,首先是数据异构性:不同工厂的传感器采样频率、数据格式差异巨大,三一重工在迁移挖掘机数据至装载机时,需解决200多种数据协议的转换问题,其次是动态环境适应性:中芯国际的光刻机参数迁移模型需每月更新,以应对设备老化带来的特征漂移,最后是安全可信问题:波音与宁德时代的跨界合作中,双方通过区块链技术构建了可信的数据交换通道,确保核心工艺参数不被泄露。
展望未来,三个方向值得关注,一是"小样本迁移"技术的突破,2026年达摩院发布的Meta-Industrial算法,仅需5个标注样本即可完成新产线模型迁移,这将极大降低中小企业应用门槛,二是与数字孪生其他技术的融合,如与强化学习结合实现生产参数的自优化,与知识图谱结合构建可解释的迁移决策链,三是标准化生态的建立,IEEE工业迁移学习工作组正在制定的P3118标准,将统一数据接口、模型评估等关键环节,为跨企业协作奠定基础。
在2026年的工业现场,迁移学习已不再是实验室里的技术概念,而是成为数字孪生系统不可或缺的"知识引擎",当三一重工的工程师通过迁移学习快速复用全球工厂的经验,当国家电网的模型在风电与余热间自由穿梭,我们正见证着工业AI从"数据驱动"向"知识驱动"的关键跃迁——这种跃迁,或将重新定义未来制造业的竞争规则。 2026年健康中国与算法推荐及人工智能技术热度持续攀升,相关应用不断深化