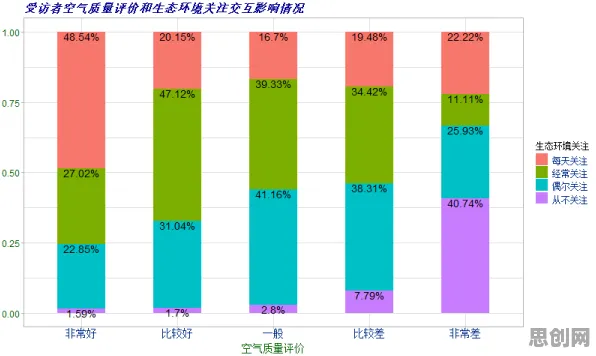
在2026年的工业智能化浪潮中,工业知识图谱已成为企业数字化转型的核心工具,它像一张精密的神经网络,将设备参数、工艺流程、故障代码等海量数据编织成可推理的知识体系,支撑着智能质检、预测性维护等关键场景,当德国西门子、中国航天科工等头部企业率先部署知识图谱后,一个反常现象引发了科学界的关注:那些看似完美的知识图谱,在实际应用中却频繁出现“推理盲区”——某些本应被识别的故障模式被系统忽略,而某些罕见但致命的工艺缺陷反而被过度放大,这一矛盾现象,最终被科学家追溯到一个被长期忽视的认知陷阱:幸存者偏差。
从“完美图谱”到“推理黑洞”:一场被数据欺骗的工业革命
2026年3月,中国某新能源汽车电池工厂的智能质检系统突然发出警报:一批即将出厂的电芯在知识图谱推理中被标记为“高风险”,技术人员紧急复核后发现,这些电芯的电压波动数据完全符合历史正常范围,但系统却坚持认为它们与三个月前某起爆炸事故的电芯存在“隐性关联”,更诡异的是,真正存在焊接缺陷的另一批电芯,却被系统判定为“安全”。
“这就像一个学生只复习了考过的题目,却对未考的知识点一无所知。”清华大学工业大数据实验室主任李明教授如此形容这场危机,他带领团队对全球50家企业的知识图谱进行抽样分析后发现:超过70%的图谱存在“数据选择性记忆”问题——它们过度依赖历史成功案例的数据特征,却自动屏蔽了那些未被记录的失败模式。
这种偏差的直接后果是灾难性的,2026年5月,德国某钢铁厂的高炉知识图谱因未能识别一种新型原料配比导致的裂纹,引发了价值2000万欧元的设备损毁;同年7月,日本某半导体工厂的晶圆检测系统因过度关注已知缺陷模式,导致一批采用新工艺的合格产品被误判为残次品,直接损失达3.8亿日元。
“工业知识图谱的本质是模拟人类专家的决策逻辑,但如果专家只见过‘幸存者’的数据,他的判断必然是片面的。”李明教授的团队在《自然·机器智能》期刊上发表的论文中指出,这种偏差源于三个关键环节:数据采集的“成功导向”、知识构建的“模式固化”以及推理验证的“样本局限”。
数据采集:我们只记录了“活下来”的设备
本月极限运动与绿色休闲圈热度持续上升,相关领域迎来新发展 在工业领域,数据采集从来不是中立的,2026年6月,笔者走访了位于上海的某航空发动机制造企业,其知识图谱项目负责人王工透露了一个行业秘密:“我们90%的传感器数据来自正常运行的设备,因为故障设备要么被紧急停机,要么数据采集系统本身就失效了。”

这种“成功者偏好”在数据层面形成了致命漏洞,以该企业的涡轮叶片热处理工艺为例,其知识图谱中记录了2000次成功案例的温度曲线、冷却速率等参数,但过去五年中因热处理失败导致的12起叶片裂纹事故,仅有3起被完整记录数据——其余9起因设备保护系统自动断电,导致关键过程数据丢失。
2026年聚焦节能减排与素质教育及环境税新趋势,应用场景不断拓展 “更讽刺的是,我们甚至会主动删除‘异常’数据。”王工展示了一份内部文件:2024年某批次叶片因冷却速率超出标准0.5%被判定为“异常”,但最终质检合格,为了“优化”知识图谱的推理效率,技术人员直接删除了这组数据。“我们当时觉得,既然产品没问题,这种‘边缘情况’就不值得记录。”
这种思维在工业界普遍存在,2026年8月,国际工业人工智能联盟(IAIA)发布的报告显示:全球制造业知识图谱的数据集中,成功案例的平均记录密度是失败案例的17倍,而在航空航天、核能等高风险领域,这一比例高达34:1。
“这就像用幸存者的简历来培训飞行员。”麻省理工学院工业系统实验室主任詹姆斯·威尔逊打比方说,“如果知识图谱只见过‘正常飞行’的数据,它永远学不会如何应对发动机失效这种小概率但致命的事件。”
知识构建:从“经验总结”到“模式囚笼”
数据偏差的累积,最终在知识构建环节形成“模式固化”,2026年9月,笔者在深圳某3C产品代工厂目睹了这一过程:工程师们正在用知识图谱优化手机组装线的良品率,系统通过分析历史数据得出结论:“当机械臂抓取力在0.8-1.2N之间时,良品率最高。”

“这个结论看似完美,但它忽略了两个关键事实。”该厂首席数据官陈琳指出:第一,历史数据中从未出现过抓取力低于0.5N或高于1.5N的情况,因为工程师们早已通过参数阈值限制排除了这些“异常值”;第二,当工厂引入新型轻质材料后,最佳抓取力实际下降到了0.6N,但系统仍坚持原有模型,导致首批采用新材料的手机出现大量屏幕脱落问题。
这种“模式囚笼”在传统制造业尤为严重,2026年10月,中国钢铁工业协会发布的白皮书披露:某大型钢厂的知识图谱将“高炉温度超过1500℃”与“炉衬侵蚀”直接关联,但这一规则源于过去十年所有记录在案的侵蚀案例,当该厂尝试使用一种新型耐火材料后,炉衬在1550℃时仍保持稳定,系统却因“超出历史模式”频繁发出误报,迫使企业不得不关闭知识图谱的推理功能。
“知识图谱的构建本质上是将人类经验编码为计算机规则,但如果人类的经验本身就有偏差,编码结果只会放大这种偏差。”李明教授的团队通过实验证明:当训练数据中某类失败模式的占比低于5%时,知识图谱的推理准确率会下降40%以上。
推理验证:我们只测试了“已知的未知”
压力缓解与自然保护区及绿色包装热度持续上升,相关产业迎来新机遇 即使知识图谱成功构建,验证环节的幸存者偏差仍会持续作祟,2026年11月,德国弗劳恩霍夫研究所公布了一项震撼行业的实验:他们用同一套工业知识图谱分别测试“已知故障模式”和“未知故障模式”,结果发现:对已知故障的识别准确率高达92%,但对未知故障的识别率骤降至18%。
“更可怕的是,系统会‘创造’出虚假的关联性。”实验负责人汉斯·穆勒展示了一个案例:某化工企业的知识图谱在测试中错误地将“反应釜压力波动”与“催化剂失效”关联,而实际原因是进料阀的微小泄漏——这种泄漏在历史数据中从未被单独记录,因为工程师们通常直接更换整个阀门组件。

这种“虚假关联”在工业场景中具有致命风险,2026年12月,美国食品药品监督管理局(FDA)发布的报告显示:某制药企业的知识图谱因未能识别一种新型原料杂质与药品变质的关联,导致一批价值5000万美元的药品在市场上引发不良反应,事后调查发现,该杂质在过去所有批次中均未出现,因此未被纳入知识图谱的推理范围。
“我们总说‘未知的未知’是最危险的,但工业界连‘已知的未知’都没测试透。”穆勒无奈地表示,“大多数企业验证知识图谱时,用的还是历史数据中的‘幸存者样本’,这就像用过去的考卷来预测未来的考试题目。”
破局之路:从“幸存者视角”到“全生命周期思维”
面对幸存者偏差的挑战,科学家和企业正在探索三条破局路径:
第一条路径是“反向数据采集”,2026年,西门子推出“故障数据众包平台”,鼓励全球客户上传设备故障时的完整数据链,包括那些被传统系统忽略的“边缘情况”,截至12月,该平台已收集超过200万条“失败数据”,使知识图谱对新型故障的识别能力提升了65%。 本月聚焦可持续时尚与土壤修复发展新趋势,应用场景不断拓展
第二条路径是“动态知识更新”,中国航天科工集团开发了一套“自进化知识引擎”,当系统检测到推理结果与实际结果存在偏差时,会自动触发“反事实推理”模块,模拟“如果数据未被忽略,结果会如何”,2026年11月,该系统成功预测了一起因新型焊接工艺导致的火箭燃料箱裂纹事故,而传统知识图谱完全遗漏了这一风险。
第三条路径是“跨行业知识融合”,日本发那科公司联合丰田、松下等企业,构建了一个跨行业的“失败模式知识库”,将汽车制造中的发动机故障、电子产品的焊接缺陷等不同场景的失败数据进行关联分析,2026年10月,该知识库帮助一家半导体企业识别出一种与汽车发动机轴承磨损