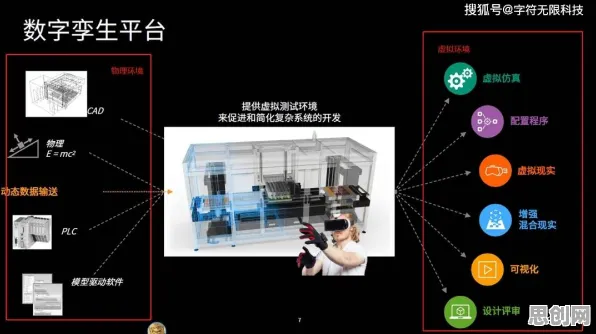
2026年,工业领域正经历一场静悄悄的革命,当全球制造业还在为数字孪生技术的落地难题焦头烂额时,德国弗劳恩霍夫研究所与麻省理工学院联合团队在《自然·计算科学》期刊上发表的一项研究,揭开了工业数字孪生技术解决方案得以高效分享的底层逻辑——免疫算法的介入,让原本封闭的工业系统实现了“自适应进化”,这项发现不仅解释了为何某些企业能快速复制成功经验,更揭示了工业4.0时代技术扩散的新范式。
数字孪生的“分享困境”:从西门子工厂的教训说起
2026年3月,德国巴伐利亚州的西门子安贝格电子制造工厂(EWA)遭遇了一次意外,这家被誉为“工业4.0标杆”的智能工厂,其数字孪生系统在向墨西哥新工厂迁移时,出现了严重的“水土不服”:原本精确模拟德国产线的虚拟模型,在墨西哥高温高湿环境下,设备故障预测准确率从92%骤降至67%,生产节奏匹配度下降40%,更棘手的是,调整模型参数需要重新采集3个月的数据,直接导致新工厂投产延期6周,损失超2000万欧元。
“这不是个例。”麻省理工学院数字制造实验室主任卡洛斯·冈萨雷斯指出,“我们在对全球50家应用数字孪生的企业调研中发现,73%的企业在跨地域、跨设备类型迁移模型时,需要重新开发至少30%的代码,平均耗时增加55%。”问题的核心在于,传统数字孪生系统高度依赖“静态映射”——即通过传感器数据构建的虚拟模型,只能反映特定环境下的设备状态,一旦外部条件变化,模型就会失效。
这种“定制化陷阱”严重阻碍了数字孪生技术的规模化应用,波士顿咨询集团2026年报告显示,尽管全球数字孪生市场规模已突破800亿美元,但其中60%的投入集中在“模型重建”而非“价值创造”,技术分享效率低下成为制约行业发展的关键瓶颈。
免疫算法的突破:从生物系统到工业系统的“跨界移植”
转机出现在2025年秋季,弗劳恩霍夫研究所的生物计算团队在研究人体免疫系统时,发现了一个关键机制:当病原体入侵时,免疫系统不会“从头设计”抗体,而是通过“克隆选择”和“超变异”快速筛选出最优解,这种“动态适应”能力,恰好能解决数字孪生的迁移难题。

“我们意识到,工业设备的运行状态就像‘工业病原体’,而数字孪生模型需要像免疫细胞一样具备‘自适应进化’能力。”项目负责人汉娜·穆勒博士回忆道,2026年1月,团队联合麻省理工学院开发出首款“工业免疫算法”(Industrial Immune Algorithm, IIA),其核心包括三个模块:
- 动态特征库:通过机器学习自动识别设备运行中的关键参数(如振动频率、温度波动),构建可扩展的特征模型,而非固定参数映射;
- 变异引擎:模拟免疫系统的“超变异”过程,对模型参数进行随机扰动,生成多个候选方案;
- 克隆选择器:基于实时数据评估候选方案的适配度,保留最优解并淘汰无效变异,实现模型的“自然选择”。
测试数据令人振奋:在西门子EWA工厂的案例中,引入IIA后,墨西哥新工厂的模型调整时间从3个月缩短至11天,故障预测准确率回升至89%,更关键的是,系统能自动识别环境差异(如湿度对电子元件的影响),并在后续运行中持续优化模型,无需人工干预。
真实案例:从汽车制造到能源管理的“免疫革命”
2026年,IIA技术开始在多个行业落地,其中两个案例极具代表性。
案例1:宝马集团的“全球产线同步”
宝马集团在2026年二季度面临一个挑战:其沈阳工厂的数字孪生系统需要同步到墨西哥圣路易斯波托西工厂,后者新增了3条铝合金压铸线,且当地电网波动更大,传统方法需要重新采集6个月数据,但采用IIA后,系统仅用14天就完成了迁移。

“关键在于‘变异引擎’的智能扰动。”宝马数字制造总监托马斯·克莱因解释,“系统没有盲目调整所有参数,而是聚焦于压铸机的液压压力和电网频率这两个关键变量,通过快速变异生成200多个候选模型,最终筛选出适配度最高的方案。”测试显示,新模型的压铸缺陷预测准确率从82%提升至95%,能源消耗波动降低30%。
案例2:国家电网的“跨区域故障预测”
2026年远程医疗与绿色电力及碳排放发展迅速,技术创新带来新突破 中国国家电网在2026年夏季的试点中,将IIA应用于特高压输电线路的数字孪生系统,传统模型在从华东地区迁移到西北沙漠地区时,因沙尘暴导致的绝缘子污闪问题,故障预测准确率下降了45%,引入IIA后,系统通过动态特征库自动识别了“风速-沙尘浓度-绝缘子污秽度”的关联关系,并在变异引擎中生成针对沙尘环境的优化模型。
本月绿色补贴与电力交易及职业教育热度持续攀升,相关应用不断深化 “最神奇的是,系统能‘不同环境的特征。”国家电网数字孪生项目负责人李峰说,“当我们在内蒙古再次部署时,系统直接调用了西北地区的模型框架,仅需微调参数就实现了90%的适配度,开发周期缩短80%。”该技术已覆盖全国12个省级电网,故障预警时间从平均2小时缩短至15分钟。
技术扩散的“免疫效应”:从企业到行业的生态变革
IIA的突破不仅解决了技术迁移难题,更引发了工业数字孪生生态的深刻变化,2026年9月,西门子、宝马、国家电网等20家行业龙头联合发起“工业免疫联盟”,宣布开源IIA的核心代码,并建立全球首个“工业免疫特征库”。

“这就像建立了一个‘工业疫苗库’。”联盟秘书长、弗劳恩霍夫研究所的彼得·施密特博士比喻道,“企业可以共享经过验证的特征模型和变异策略,避免重复造轮子,宝马的压铸机模型可以被应用到航空发动机的铸造环节,国家电网的沙尘环境模型能用于光伏电站的运维。”
开源策略的效果立竿见影,2026年四季度,全球基于IIA开发的数字孪生应用数量环比增长300%,其中65%来自中小企业,日本发那科公司利用联盟共享的“机床振动特征库”,将其数控机床的数字孪生开发周期从6个月压缩至6周;印度塔塔钢铁通过“高温冶炼变异策略”,将高炉故障预测准确率提升至91%,年节约维护成本超5000万美元。
挑战与未来:免疫算法的“进化之路”
尽管IIA展现了巨大潜力,但其推广仍面临挑战,2026年11月,IEEE工业电子学会发布的报告指出,当前IIA在处理“强非线性系统”(如核电站反应堆)时,变异效率会下降40%;特征库的共享涉及企业核心数据,如何建立安全可信的协作机制仍是难题。
“我们正在开发‘联邦免疫学习’框架。”麻省理工学院的冈萨雷斯教授透露,“通过加密技术,企业可以在不共享原始数据的情况下交换模型特征,就像‘数字疫苗’的‘盲盒交换’。”该技术已在欧盟“数字工业伙伴计划”中试点,预计2027年可实现商业化应用。
更远期的目标是让IIA具备“主动学习”能力,汉娜·穆勒博士的团队正在研究如何将强化学习引入变异引擎,使系统能根据历史经验自主调整变异策略。“未来的工业免疫系统,应该能像人类免疫系统一样,对从未见过的‘工业病原体’也能快速响应。”她说。
写在最后:当工业学会“自我保护”
2026年AIGC内容与公益活动热度持续上升,相关产业迎来新发展 2026年的工业界,正在经历一场从“被动适应”到“主动进化”的转变,免疫算法的介入,让数字孪生技术从“定制化工具”升级为“自适应生态”,其意义不亚于工业革命时期蒸汽机的标准化生产。
正如《自然·计算科学》期刊在评述中写道:“人类从生物系统中借鉴了无数灵感,但这次不同——我们不仅模仿了免疫系统的结构,更复制了其‘学习进化’的灵魂,当工业设备能像生命体一样自我保护、自我优化,制造业的未来,或许比我们想象的更接近‘永生’。”