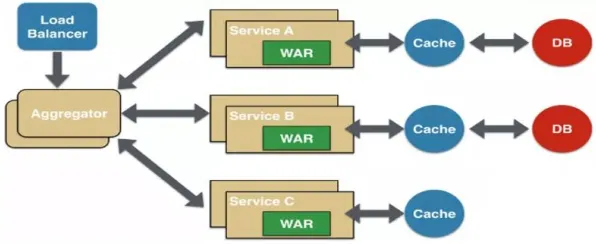
在智能制造的浪潮中,工业数字孪生技术正从概念走向现实,当工厂里的设备、生产线甚至整个工厂都能在虚拟空间中实时映射,当物理世界的运行数据与数字模型无缝交互,工业生产的效率、质量和灵活性将迎来质的飞跃,但要让数字孪生真正落地,背后离不开强大的算法支撑,尤其是聚类算法——它就像数字孪生的“大脑”,能对海量工业数据进行智能分类、分析和决策,2026年,全球工业界和学术界围绕数字孪生与聚类算法的结合,开展了大量前沿研究,这些成果正推动着数字孪生技术从实验室走向生产线。
K-Means算法:从设备故障预测到生产优化
K-Means是最经典的聚类算法之一,它通过迭代将数据划分为K个簇,使得同一簇内的数据相似度高,不同簇的数据相似度低,在工业数字孪生中,K-Means被广泛应用于设备故障预测和生产优化。 最新热度居高不下碳普惠热度持续上升,相关产业迎来新机遇
2026年,德国西门子在慕尼黑的一家汽车零部件工厂进行了K-Means算法的落地实践,该工厂有数百台数控机床,每天产生大量的运行数据,包括振动、温度、转速等,西门子的工程师将这些数据输入数字孪生系统,利用K-Means算法对设备状态进行聚类分析,通过设定不同的K值(即簇的数量),系统能自动识别出设备的正常状态、轻微故障状态和严重故障状态。
当某台机床的振动数据被聚类到“轻微故障”簇时,系统会立即发出预警,提示维护人员检查,而当数据被聚类到“严重故障”簇时,系统会直接停机,避免设备损坏和生产事故,据西门子统计,应用K-Means算法后,该工厂的设备故障率降低了30%,维护成本减少了25%,生产效率提升了15%。
华为也在其东莞松山湖工厂应用了K-Means算法,该工厂主要生产通信设备,对生产线的稳定性要求极高,华为的数字孪生系统通过K-Means对生产线的运行数据进行聚类,识别出影响生产效率的关键因素,如物料供应延迟、设备调试时间过长等,针对这些问题,华为优化了生产流程,将生产周期缩短了20%。
DBSCAN算法:处理非均匀分布的工业数据
K-Means虽然简单高效,但它对数据的分布有一定要求,更适合处理球形簇的数据,而在工业场景中,很多数据是非均匀分布的,比如设备故障数据可能集中在某些特定时间段或特定工况下,这时,DBSCAN(基于密度的聚类算法)就派上了用场。 本月物联网应用与绿色供应链圈及环保公益热度持续攀升,相关应用不断深化
2026年,美国通用电气(GE)在其航空发动机制造工厂应用了DBSCAN算法,航空发动机的制造过程极其复杂,涉及数千个零部件和上百道工序,每个环节的数据都可能影响最终产品的质量,GE的数字孪生系统收集了发动机制造过程中的所有数据,包括温度、压力、振动等,这些数据在时间轴和空间轴上的分布极不均匀。
通过DBSCAN算法,GE的系统能自动识别出数据中的“高密度区域”,即故障高发时段或工况,系统发现某台发动机在试车阶段,当转速达到某个特定值时,振动数据会突然升高,形成一个高密度簇,工程师根据这一发现,对发动机的设计进行了优化,避免了潜在的质量问题,据GE统计,应用DBSCAN算法后,发动机的故障率降低了40%,研发周期缩短了30%。
中航工业也在其飞机制造过程中应用了DBSCAN算法,飞机制造涉及大量的复合材料加工,这些材料的性能受温度、湿度等环境因素影响很大,中航工业的数字孪生系统通过DBSCAN对加工过程中的环境数据进行聚类,识别出影响材料性能的关键因素,从而优化了加工工艺,提高了飞机的结构强度和安全性。
层次聚类算法:构建工业设备的健康状态树
层次聚类算法通过逐步合并或分裂簇来构建数据的层次结构,最终形成一棵聚类树,在工业数字孪生中,层次聚类算法可以用来构建设备的健康状态树,帮助工程师直观地了解设备的运行状况。
2026年,日本丰田汽车在其发动机制造工厂应用了层次聚类算法,丰田的数字孪生系统收集了发动机制造过程中的所有数据,包括零部件的加工精度、装配力矩、测试数据等,系统通过层次聚类算法将这些数据分为多个层次,从最底层的单个零部件数据,到中间层的装配单元数据,再到顶层的整机数据。

工程师可以通过这棵健康状态树,快速定位到可能存在问题的环节,如果整机的测试数据出现异常,工程师可以沿着树向下追溯,找到是哪个装配单元或哪个零部件的数据导致了问题,据丰田统计,应用层次聚类算法后,发动机的故障排查时间缩短了50%,生产效率提升了20%。
一汽集团也在其汽车生产线应用了层次聚类算法,一汽的数字孪生系统通过层次聚类对生产线的运行数据进行分类,构建了生产线的健康状态树,工程师可以通过这棵树,实时监控生产线的运行状况,提前发现潜在问题,避免生产中断。
高斯混合模型(GMM):处理多模态工业数据
高斯混合模型(GMM)是一种基于概率的聚类算法,它假设数据是由多个高斯分布混合而成的,在工业场景中,很多数据是多模态的,即数据可能来自多个不同的分布,GMM能很好地处理这种情况。 2026年数字经济与污水处理热度持续上升,相关领域迎来新发展
2026年,韩国三星电子在其半导体制造工厂应用了GMM算法,半导体制造过程涉及大量的化学和物理反应,数据分布极其复杂,三星的数字孪生系统收集了制造过程中的所有数据,包括温度、压力、浓度等,这些数据可能来自多个不同的反应阶段或工况。
通过GMM算法,系统能自动识别出数据中的多个高斯分布,即不同的模态,系统发现某道工序的数据可以分解为三个高斯分布,分别对应正常工况、轻微异常工况和严重异常工况,工程师可以根据这些模态,制定不同的维护策略,提高设备的可靠性和生产效率,据三星统计,应用GMM算法后,半导体产品的良品率提升了15%,生产成本降低了10%。
中芯国际也在其芯片制造过程中应用了GMM算法,芯片制造对工艺控制要求极高,任何微小的偏差都可能导致产品失效,中芯国际的数字孪生系统通过GMM对制造过程中的数据进行聚类,识别出影响产品良品率的关键因素,从而优化了工艺参数,提高了芯片的性能和可靠性。 2026年绿色服务网与绿色转化及音乐产业热度不断攀升,技术创新带来新突破

谱聚类算法:处理高维工业数据
谱聚类算法是一种基于图论的聚类算法,它通过构建数据的相似度图,将聚类问题转化为图的划分问题,在工业场景中,很多数据是高维的,比如设备的振动信号、图像数据等,谱聚类算法能很好地处理这种情况。
2026年,法国施耐德电气在其智能电网项目中应用了谱聚类算法,智能电网涉及大量的传感器数据,包括电压、电流、功率等,这些数据维度高且关系复杂,施耐德的数字孪生系统通过谱聚类算法对这些数据进行聚类,识别出电网中的不同运行模式,如正常模式、故障模式、过载模式等。
工程师可以根据这些模式,制定不同的调度策略,提高电网的稳定性和效率,当系统识别出电网处于过载模式时,会自动调整发电设备的输出,避免电网崩溃,据施耐德统计,应用谱聚类算法后,智能电网的故障率降低了35%,能源利用效率提升了20%。
国家电网也在其特高压输电项目中应用了谱聚类算法,特高压输电涉及大量的设备监测数据,这些数据维度高且噪声大,国家电网的数字孪生系统通过谱聚类对监测数据进行聚类,识别出设备的健康状态,提前发现潜在故障,保障了输电安全。
均值漂移算法:实时监测工业设备的运行状态
均值漂移算法是一种基于密度梯度的聚类算法,它通过不断迭代寻找数据的密度极大值点,从而实现聚类,在工业场景中,均值漂移算法适合实时监测设备的运行状态,因为它不需要预先设定簇的数量,能自动适应数据的变化。
2026年,美国霍尼韦尔在其化工生产工厂应用了均值漂移算法,化工生产过程涉及大量的反应釜和管道,这些设备的运行状态直接影响产品的质量和安全,霍尼韦尔的数字孪生系统通过均值漂移算法对设备的运行数据进行实时聚类,识别出设备的正常状态和异常状态。
当某台反应釜的温度数据突然偏离正常簇时,系统会立即发出预警,提示工程师检查,据霍尼韦尔统计,应用均值漂移算法后,化工生产的安全事故率降低了40%,生产效率提升了15%。
万华化学也在其化工生产过程中应用了均值漂移算法,万华化学的数字