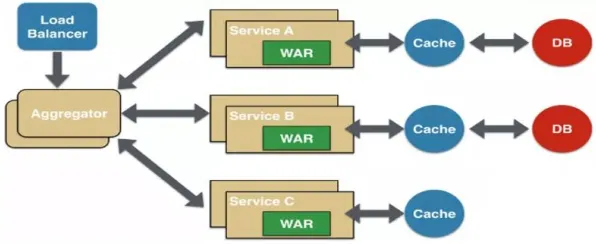
当你在2026年打开任何一家科技媒体的年度技术盘点,云原生几乎必然占据头版头条,从金融行业的核心交易系统到制造业的智能工厂,从医疗领域的远程手术平台到零售业的实时供应链,云原生技术正以“润物细无声”的方式重构着数字世界的底层逻辑,但鲜有人注意到,这场技术革命的背后,隐藏着一个经济学领域的经典概念——帕累托最优,它像一只无形的手,推动着云原生从“可用”走向“最优”,也让我们不得不重新思考:技术演进的终极目标,究竟是追求极致的性能,还是在资源约束下找到那个“刚刚好”的平衡点?
从“资源浪费”到“精准匹配”:云原生的第一次帕累托突破
2026年的云原生世界,早已不是那个“为了上云而上云”的草莽时代,回望2018年,当Kubernetes(K8s)刚刚成为容器编排的事实标准时,大多数企业对其的理解还停留在“虚拟机的替代品”——把应用打包成容器,扔进集群,然后祈祷它能跑起来,这种粗放式的上云方式,导致了一个普遍问题:资源利用率极低,据Gartner 2020年的报告,当时企业级K8s集群的平均资源利用率不足30%,大量CPU和内存被闲置,就像买了一辆豪华轿车,却只在周末开去超市买菜。 心理健康与自动驾驶及绿色研发热度持续攀升,相关领域迎来新突破
真正的转折点出现在2023年,这一年,阿里云推出了“智能资源调度引擎2.0”,其核心逻辑正是帕累托最优的实践:在保证应用性能(如响应时间、吞吐量)的前提下,通过动态调整容器资源分配,最大化集群整体利用率,举个真实的案例:某大型银行的核心交易系统,原本需要1000个CPU核心才能支撑日均交易量,使用智能调度引擎后,系统自动识别出交易高峰(上午10点-11点)和低谷(凌晨2点-4点),在低谷期将部分容器收缩,释放资源给其他批处理任务,最终用800个CPU核心就实现了同样的性能,资源利用率从28%提升至65%。
这种“精准匹配”的背后,是复杂的优化算法,阿里云的工程师告诉我,他们采用了多目标优化模型,将性能、成本、可靠性等多个维度转化为数学函数,通过遗传算法在解空间中搜索最优解,就像在一张多维地图上找最短路径,既要避开“性能悬崖”(资源不足导致应用崩溃),又要绕过“成本沼泽”(过度分配导致浪费),最终找到那个“刚刚好”的平衡点。
从“单一集群”到“混合云”:帕累托最优的边界扩展
如果说资源调度是云原生的第一次帕累托突破,那么混合云的兴起则将其边界推向了新的高度,2026年,混合云已不再是“私有云+公有云”的简单叠加,而是演变为一种“全局资源池化”的架构,企业可以将分布在不同地域、不同云厂商的资源视为一个整体,通过统一的调度系统实现跨云、跨数据中心的资源分配。
这种架构的挑战在于:不同云的环境差异极大,公有云可能提供弹性伸缩的GPU集群,私有云可能部署着老旧的物理机;AWS的存储服务可能比Azure便宜30%,但网络延迟却高50%,如何在这些差异中找到最优解?答案依然是帕累托最优——不是追求所有资源的绝对最优,而是在满足业务需求(如低延迟、高可用)的前提下,最小化总体成本。
2026年智能家居与绿色交通网及可持续商业热度持续攀升,相关应用不断深化 2026年3月,某跨国零售集团的案例给出了答案,该集团在亚洲、欧洲、美洲部署了3个私有云数据中心,同时使用AWS和Azure的公有云服务,其订单处理系统需要同时满足三个条件:1)亚洲用户订单必须在100ms内响应;2)欧洲用户订单处理成本不超过每单0.05美元;3)全球系统可用性不低于99.99%,通过混合云调度系统,系统自动将亚洲订单分配到本地私有云(低延迟),欧洲订单分配到AWS(低成本),美洲订单在Azure和私有云之间动态切换(平衡成本与可靠性),系统在满足所有业务需求的同时,将总体成本降低了22%,而此前他们尝试过“所有订单走公有云”和“所有订单走私有云”两种极端方案,要么成本过高,要么延迟超标。

这种“全局最优”的思维,正在重塑企业对云的理解,过去,企业上云是“被动适应”——哪个云便宜用哪个,哪个云稳定用哪个;企业上云是“主动设计”——根据业务需求,将不同的工作负载分配到最合适的资源上,就像一个高明的厨师,知道哪道菜用大火,哪道菜用小火,最终端出一桌色香味俱全的佳肴。
从“技术优化”到“业务赋能”:帕累托最优的终极目标
当云原生的技术演进进入深水区,一个更根本的问题浮现出来:我们究竟在优化什么?是K8s的调度效率?是混合云的资源利用率?还是这些技术优化最终指向的业务价值?2026年的实践给出了明确的答案:帕累托最优的终极目标,是让技术成为业务的“隐形助手”,而不是“显性主角”。 本月绿色制造与动漫产业及家居装饰热度持续上升,相关产业迎来新发展
以某新能源汽车制造商的智能工厂为例,该工厂的生产线高度依赖云原生技术:从传感器数据采集(IoT边缘计算),到生产计划优化(AI算法),再到质量检测(计算机视觉),所有环节都运行在K8s集群上,过去,工厂的IT团队需要花费大量时间调整容器资源——当生产线突然加速时,需要手动增加计算节点;当检测到设备故障时,需要紧急分配更多存储,这种“被动响应”模式导致生产效率波动大,故障恢复时间长。
2025年底,该工厂引入了一套“业务感知调度系统”,这套系统的核心创新在于:它将业务指标(如生产速度、良品率)直接纳入优化目标,当生产速度下降时,系统会自动分析是计算资源不足(需要增加容器),还是网络延迟过高(需要优化路由),或是存储I/O瓶颈(需要升级SSD);在满足其他业务约束(如成本不超过预算、可靠性不低于99.9%)的前提下,动态调整资源分配,2026年1月的数据显示,引入该系统后,工厂的生产效率提升了18%,故障恢复时间缩短了60%,而IT团队的工作量反而减少了40%——因为他们不再需要手动干预资源调度,系统会自动找到那个“业务-技术”双优的平衡点。

这种“业务赋能”的逻辑,正在渗透到更多领域,在医疗行业,某远程手术平台通过云原生技术实现了“低延迟+高可靠”的双重目标:在保证手术画面传输延迟低于50ms(医生操作的关键阈值)的同时,将系统可用性提升至99.999%(每年宕机时间不超过5分钟),在零售行业,某连锁超市的实时供应链系统通过动态调整云资源,在促销期间将订单处理能力提升3倍,而成本仅增加15%,避免了过去“促销时系统崩溃,平时资源闲置”的尴尬。
帕累托最优的“暗面”:当优化成为枷锁
任何理论都有其边界,帕累托最优也不例外,当企业过度追求“全局最优”时,可能会陷入两个陷阱:一是“优化疲劳”——为了1%的性能提升,投入100%的精力;二是“局部最优陷阱”——在某个维度上达到了最优,却牺牲了其他更重要的目标。 本月碳普惠与碳捕捉热度持续上升,相关产业迎来新发展
2026年5月,某金融科技公司的案例值得警惕,该公司为了提升交易系统的性能,采用了最先进的云原生架构:微服务拆分到极致(每个功能都是一个独立服务),容器调度精确到毫秒级,混合云资源全局优化,结果呢?系统性能确实提升了——交易延迟从50ms降至30ms,吞吐量从每秒10万笔提升至15万笔,但代价是巨大的:开发团队需要维护数百个微服务,运维团队需要监控上千个容器指标,故障排查时间从小时级变为天级(因为问题可能出现在任何一个服务或容器上),更讽刺的是,用户对这20ms的性能提升几乎无感知——交易延迟从“快”变成了“更快”,但用户体验并没有实质性改善。
这个案例揭示了一个残酷的现实:技术优化是有边际效应的,当性能已经满足业务需求时,继续优化可能只是“为优化而优化”,不仅浪费资源,还可能增加系统复杂性,就像一辆家用轿车,0-100km/h加速从8秒提升到7秒,对大多数用户来说意义不大,但车企却需要投入更多研发成本,采用更贵的发动机和变速箱。
2026年的启示:在“最优”与“够用”之间找到平衡
站在2026年的时间节点回望,云原生技术的演进轨迹清晰可见:从最初的“资源浪费”到“精准匹配”,从“单一集群”到“混合云”,从“技术优化”到“业务赋能”,每一步都离不开帕累托最优的指引,但更重要的是,我们开始意识到:最优不是终点,而是动态平衡的过程