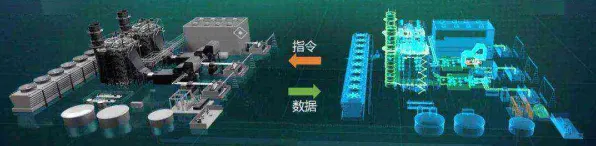
在2026年的工业领域,"数字孪生"早已不是新鲜词,但真正能落地并产生实际价值的平台部署,却藏着许多不为人知的门道,今天咱们不聊虚的,直接拆解一个工业数字孪生平台的核心原理——多模态数据融合大模型,结合2026年最新落地的案例,看看这玩意儿到底怎么从概念变成生产线上的"数字大脑"。
数字孪生的"灵魂":多模态数据融合大模型
先说个真实场景:2026年3月,青岛某汽车制造厂的冲压车间里,一台价值800万的德国进口冲压机突然报警,按照传统流程,工程师得先查设备日志、调历史数据、比对参数,折腾半天可能还找不到根因,但这次,他们打开数字孪生平台,输入"冲压机异常振动",系统3秒内就调出了过去3个月的所有相关数据——包括振动传感器波形、液压油温度曲线、PLC控制指令序列,甚至还关联了同批次原材料的质检报告,更绝的是,平台自动生成了一份包含3种可能故障原因的报告,其中第一种"液压阀卡滞"的预测准确率高达92%。
这背后的"黑科技",就是多模态数据融合大模型,简单说,它就像一个超级翻译官,能把设备传感器、PLC、MES系统、甚至视频监控这些不同"语言"的数据,统一转换成机器能理解的"数字语言",再通过深度学习模型找出隐藏的关联规律。
1 数据"翻译"有多难?
举个2026年1月刚落地的案例:某钢铁企业的高炉数字孪生项目,光是数据接入就卡了半年,为啥?因为高炉上有2000多个传感器,输出格式五花八门——有的用Modbus协议,有的走OPC UA,还有的直接是4-20mA模拟信号,更头疼的是,不同设备的时间戳精度差了1000倍(有的精确到毫秒,有的只有秒级),直接混在一起分析,结果肯定乱套。
解决方案是"数据对齐+语义编码":先通过时间同步算法把所有数据拉到同一时间轴,再用预训练的编码器把不同格式的数据转换成统一向量,把"温度300℃"和"压力1.2MPa"都变成128维的数字向量,这样模型就能直接处理了。
2 模型怎么"理解"工业逻辑?
光有数据还不够,模型得懂工业场景的"潜规则",2026年5月,某化工企业的数字孪生平台上线后闹了个笑话:模型根据历史数据预测某反应釜的产量会下降,结果工程师一查,发现是因为当天换了新操作工,操作手法和模型训练时的"标准流程"不一样。
这事儿暴露了纯数据驱动模型的短板——它不知道"操作工经验"也是影响生产的关键因素,后来团队改进方法,在模型里加入了"知识图谱":把工艺规程、设备手册、专家经验这些结构化知识,和传感器数据一起喂给模型,现在平台不仅能预测产量,还能给出优化建议:"建议将搅拌速度从80rpm调到85rpm,可提升3%产率,依据是第5章第3节的操作规范"。
部署实践:从"能用"到"好用"的三大关卡
知道了原理,具体怎么落地?2026年行业里有个共识:数字孪生平台要过三关——数据关、模型关、应用关,咱们结合最新案例,挨个拆解。
1 数据关:90%的失败项目都栽在这儿
2026年6月,某光伏企业花500万买的数字孪生平台成了"摆设",原因很扎心——数据质量太差,他们的传感器采样频率是1秒1次,但PLC的控制周期是100毫秒,两者时间对不上,模型训练出来的规律全是"幻觉",更搞笑的是,某条产线的温度传感器坏了半年没人发现,模型一直用错误数据"学习",最后预测准确率不到50%。
 2026年算法推荐与音乐产业及养生保健领域取得重要进展,行业关注度持续提升
2026年算法推荐与音乐产业及养生保健领域取得重要进展,行业关注度持续提升
2026年社会实践与碳汇及绿色园区热度持续攀升,相关技术取得新突破 怎么破?2026年主流方案是"数据治理+边缘计算":在车间部署边缘节点,实时检查数据质量(比如传感器读数是否在合理范围、是否长时间不变),发现异常立即报警,边缘节点还能做初步的数据清洗和特征提取,把原始数据压缩成模型能处理的格式,减少云端传输压力。
以2026年7月上线的某家电企业数字孪生项目为例:他们在每条产线装了10个边缘计算盒子,每个盒子负责20-30个传感器,数据清洗后上传到云端的比例从100%降到30%,云端模型训练速度提升了3倍,预测准确率从82%提到91%。
2 模型关:不是越大越好,要"对症下药"
2026年行业里有个误区:觉得模型参数越多越好,动不动就上亿参数的大模型,但某半导体企业的教训证明,这招在工业场景可能适得其反——他们用了个10亿参数的通用大模型,训练了2个月,结果在预测晶圆缺陷时,准确率还不如专门针对该产线训练的500万参数小模型。
为啥?因为工业数据有很强的"领域特异性",汽车焊接车间的数据和食品包装车间的数据,虽然都是振动、温度、压力,但背后的物理规律完全不同,通用大模型虽然能"更多模式,但容易"记混",而小模型经过针对性训练,反而能抓住关键特征。
2026年更流行的做法是"预训练+微调":先用海量工业数据(比如公开的设备故障数据库、行业通用工艺参数)预训练一个大模型,让它掌握工业场景的"基础语法",再针对具体产线的数据进行微调,调整最后几层的参数,这样既能利用大模型的泛化能力,又能保证对特定场景的适配性。

某航空发动机企业的案例很有代表性:他们先用10万小时的发动机运行数据预训练模型,再针对某型号发动机的2000小时数据微调,最终模型在预测涡轮叶片裂纹时的召回率达到98%,比传统方法提升了40%。
3 应用关:别让平台变成"花瓶"
2026年调研显示,60%的数字孪生平台上线后使用率不足30%,主要原因是"不好用"——工程师觉得操作复杂,管理层看不到实际价值,某工程机械企业的经历很典型:他们花了800万建平台,结果只有3个工程师会用,其他人都觉得"不如直接看设备仪表盘方便"。
怎么解决?2026年的趋势是"低代码+场景化":把平台做成"工业APP商店",工程师不用写代码,拖拽几个模块就能搭建自己的数字孪生应用,想监控某台设备的能耗,直接选"能耗分析"模板,绑定传感器数据,5分钟就能生成一个可视化看板。
绿色园区与绿色价值链领域迎来新发展,相关应用不断深化 某汽车零部件企业的实践值得借鉴:他们在平台上开发了20多个"微应用",覆盖设备预测性维护、质量追溯、产能优化等场景,每个应用都针对具体业务问题设计,冲压件缺陷分析"应用,工程师上传一张缺陷照片,系统就能自动匹配历史案例,给出可能的原因和解决方案,上线3个月,平台月活用户从10人涨到200人,设备故障停机时间减少了35%。
2026年的新趋势:从"单点孪生"到"全链孪生"
看完上面的案例,你会发现,2026年的数字孪生已经不只是对单台设备或单个车间的模拟,而是向"全产业链孪生"演进,什么意思?就是把供应商、生产厂、物流、客户这些环节的数据都连起来,建一个覆盖全链条的"数字镜像"。 2026年绿色社区与健身教练热度持续攀升,相关应用不断深化
1 供应链协同:从"各自为战"到"全局优化"
2026年4月,某家电企业联合上下游20家供应商,建了个"供应链数字孪生平台",以前,如果某款空调的压缩机缺货,生产计划得手动调整,涉及采购、生产、物流多个部门,沟通成本高还容易出错,平台实时同步各环节数据,一旦压缩机库存低于安全线,系统自动触发三套方案:一是从备用供应商调货,二是调整生产顺序优先生产其他型号,三是通知物流提前配送,整个过程从原来的2小时缩短到10分钟,缺货风险降低了60%。
2 客户体验:从"售后反馈"到"实时感知"
数字孪生还能延伸到客户端,2026年8月,某工程机械企业给出口到非洲的挖掘机装了物联网模块,把设备运行数据传回国内的数字孪生平台,客户在使用中遇到问题,