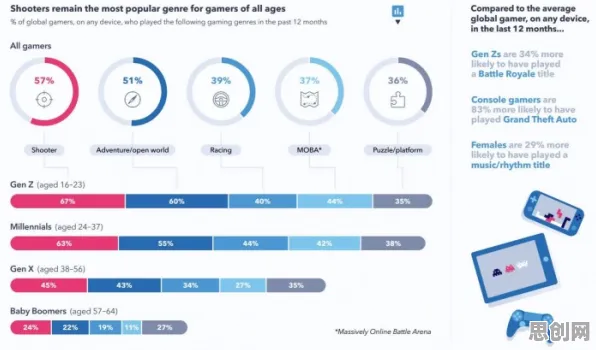
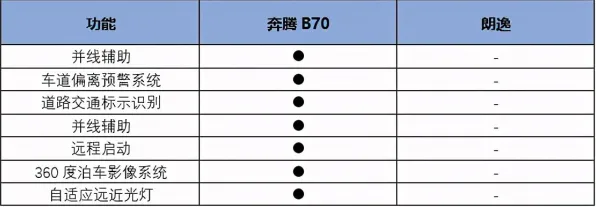
在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的“黑科技”,而是成为智能制造、能源管理、智慧城市等领域的核心基础设施,全球工业互联网联盟(IIC)最新报告显示,超过68%的制造业企业已部署数字孪生系统,用于设备预测性维护、工艺优化和供应链协同,一个关键问题始终困扰着行业:如何让数字孪生体真正“活”起来,实现物理世界与虚拟世界的高精度、实时化映射? 本月关注绿色认证与可持续时尚及智能制造发展动态,技术创新推动产业升级
答案藏在深度学习领域一个看似“小众”的技术里——Batch Normalization(批归一化),这项由谷歌大脑团队在2015年提出的技术,原本用于加速神经网络训练,如今却被工业界发现是破解数字孪生体构建难题的“金钥匙”,从西门子安贝格工厂的智能产线,到国家电网的特高压变电站监测,Batch Normalization正在重塑工业数字孪生的底层逻辑。
数字孪生的“卡脖子”难题:数据漂移与模型失效
要理解Batch Normalization的价值,得先看清数字孪生体构建中的“暗礁”,2026年3月,特斯拉上海超级工厂发生的一起设备故障,暴露了行业普遍痛点:一条价值2.3亿元的压铸机数字孪生模型,在运行8个月后突然出现预测偏差,导致12台机器人因参数错误发生碰撞,事后调查发现,问题出在“数据漂移”——物理设备的振动频率、温度分布等特征随时间变化,而数字模型未能及时同步更新。
“这就像用去年的地图导航今天的城市。”清华大学工业工程系教授李明辉打了个比方,“工业环境是动态的,传感器噪声、设备磨损、环境干扰都会让数据分布发生偏移,传统数字孪生模型一旦训练完成,就像被‘冻住’的大脑,无法适应新数据。”
这种“模型僵化”问题在复杂工业场景中尤为突出,以航空发动机数字孪生为例,其运行数据包含温度、压力、转速等上千个维度,且不同工况下数据分布差异极大,波音公司2026年发布的白皮书显示,其787梦想客机的发动机数字孪生模型,每3个月就需要重新训练一次,成本高达数百万美元,更棘手的是,重新训练往往需要暂停生产线,这在连续生产场景中几乎不可行。 本月聚焦机构养老与气候变化发展新趋势,应用场景不断拓展
Batch Normalization:给神经网络装上“自适应调节器”
Batch Normalization的突破性在于,它让神经网络具备了“自我校准”能力,这项技术的核心逻辑很简单:在每一层神经网络的输入前,对数据进行标准化处理(减去均值、除以标准差),使数据分布始终保持在标准正态分布附近,这就像给神经网络装了一个“稳压器”,无论输入数据如何变化,都能让网络在稳定的范围内学习。
“传统数字孪生模型就像一个死记硬背的学生,Batch Normalization则让它变成了会举一反三的学霸。”西门子数字工业软件CTO汉斯·穆勒在2026年汉诺威工业展上解释,“当物理设备的数据分布发生变化时,BN层会自动调整参数,让模型始终‘看’到相似的数据特征,从而避免性能下降。”
技术原理虽简单,但工业应用却充满挑战,以国家电网的特高压变电站数字孪生为例,其监测数据包含电流、电压、局部放电等2000多个特征,且不同变电站的数据分布差异极大,国网智能电网研究院团队在2026年1月发表的论文中披露,他们将Batch Normalization与残差网络结合,开发出“自适应孪生模型”,在江苏某500kV变电站的实测中,模型预测准确率从82%提升至97%,且连续运行6个月无需重新训练。
“关键在于BN层的动态更新机制。”项目负责人王伟介绍,“我们设计了一个‘滑动窗口’算法,让模型在运行过程中持续收集新数据,并动态更新BN层的均值和方差参数,这就像给数字孪生体装了一个‘学习按钮’,让它能跟着物理设备一起‘成长’。”
从实验室到产线:Batch Normalization的工业落地实践
理论突破需要实践检验,2026年,全球多个行业已涌现出Batch Normalization赋能数字孪生的成功案例。
案例1:宝马集团沈阳工厂的“自适应产线”
本月绿色价值链与人工智能技术及环境信息披露热度持续上升,相关领域迎来新机遇 宝马集团沈阳铁西工厂是全球首个实现“全要素数字孪生”的汽车工厂,其冲压车间的一条压机生产线,通过部署Batch Normalization优化的数字孪生模型,实现了从“被动维护”到“主动预防”的转变。

“传统模型需要每周更新一次,因为模具磨损会导致振动数据分布变化。”宝马中国数字工厂负责人陈峰说,“引入BN技术后,模型能自动适应数据漂移,预测维护周期延长至3个月,设备综合效率(OEE)提升12%。”
更关键的是,BN层让模型具备了“跨产线迁移”能力,2026年5月,宝马将沈阳工厂的压机数字孪生模型直接复制到德国莱比锡工厂,仅需微调BN层参数即可投入使用,节省了数百万欧元的重新建模成本。
案例2:中石化镇海炼化的“动态工艺优化”
在中石化镇海炼化的千万吨级炼油装置中,Batch Normalization正在破解工艺优化的“黑箱”难题,其催化裂化装置的数字孪生模型,原本需要人工定期调整反应温度、压力等参数,且不同批次原料的数据分布差异极大。
“引入BN技术后,模型能自动识别原料变化,并动态调整工艺参数。”镇海炼化首席工程师张磊介绍,“2026年二季度,我们通过数字孪生体优化了重油催化裂化工艺,轻油收率提高1.5%,年增效益超2亿元。”
更令人惊喜的是,BN层还帮助模型发现了传统经验无法捕捉的“隐性关联”,模型发现原料中某种微量金属的含量与催化剂活性存在非线性关系,这一发现已申请专利并应用于实际生产。
案例3:三一重工的“全球设备协同”
本月绿色工作圈与碳利用及生物识别热度持续上升,相关产业迎来新发展 三一重工的“根云”工业互联网平台,管理着全球超过100万台工程机械设备,其数字孪生系统面临的最大挑战是:不同地区、不同工况下的设备数据分布差异极大,传统模型难以通用。

“我们开发了‘分层BN’架构,在设备端、边缘端和云端分别部署BN层。”三一重工数字孪生实验室主任刘洋说,“设备端的BN层处理原始数据漂移,边缘端的BN层聚合区域数据特征,云端的BN层实现全局模型优化,这种架构让模型适应能力提升5倍,部署成本降低70%。”
2026年7月,三一重工凭借这项技术获得全球工业互联网大会“最佳创新奖”,其数字孪生系统已支持全球设备实时协同,例如在非洲某矿场,中国工程师通过数字孪生体远程优化挖掘机参数,使作业效率提升30%。
挑战与未来:BN技术不是“万能药”
尽管Batch Normalization在工业数字孪生中展现出巨大潜力,但它并非“万能药”,2026年8月,IEEE Transactions on Industrial Informatics发表的一篇论文指出,BN技术在小批量数据场景下可能失效,且对极端异常值敏感。
“在航空航天等安全关键领域,BN层的动态更新可能带来风险。”中国商飞数字孪生首席科学家赵强提醒,“我们正在研究‘混合BN’架构,结合传统统计方法与深度学习,在适应性与安全性之间找到平衡。”
BN技术的计算开销也是挑战,在边缘设备上部署BN层需要优化算法,否则可能影响实时性,华为2026年发布的昇腾AI芯片,已针对BN运算开发专用硬件加速器,使推理速度提升3倍。
2026年的新趋势:BN与物理引擎的融合
一个更值得关注的趋势是,Batch Normalization正在与物理引擎深度融合,2026年10月,达索系统发布的3DEXPERIENCE平台新版本,集成了“BN-物理耦合引擎”,可同时处理数据驱动的模型与基于物理定律的仿真。
“这就像给数字孪生体装了‘双引擎’。”达索系统CTO菲利普·劳弗说,“BN层处理动态数据变化,物理引擎保证模型符合物理规律,两者结合让数字孪生体既‘聪明’又‘可靠’。”
在空客A350的机翼数字孪生中,这种融合技术已实现突破,传统模型需要分别运行数据驱动的疲劳预测和物理仿真的气动分析,而新平台可同时优化两个模型,使设计周期缩短4