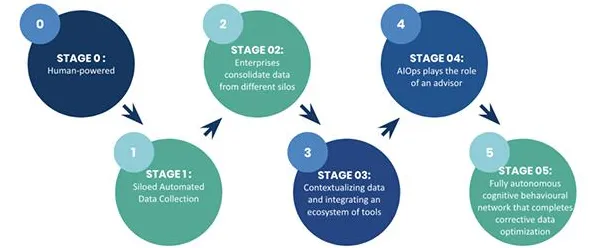
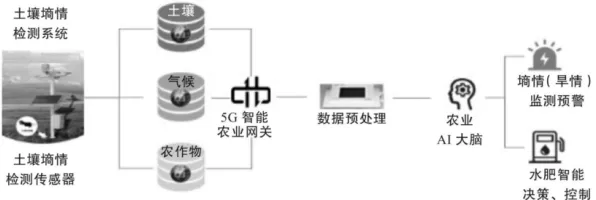
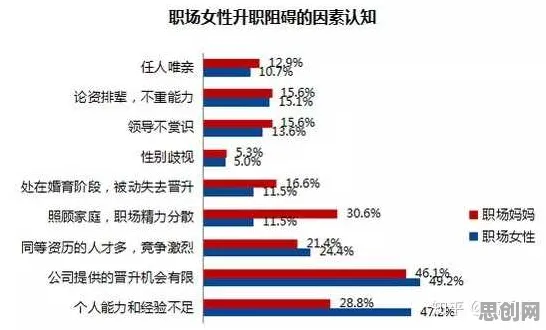
当数据成为新石油,我们为何总在"选择性看见"?
2026年3月,北京某互联网法院审理了一起引发全国关注的案件:某短视频平台用户起诉平台未经授权使用其浏览数据训练AI模型,原告律师在法庭上展示了一份长达200页的证据链,而被告方则拿出另一份由顶尖数据科学团队出具的报告,证明这些数据属于"平台公共资源",这场看似技术性的争论背后,隐藏着一个更根本的认知陷阱——确认偏误(Confirmation Bias)。
确认偏误,这个由心理学家彼得·瓦森在1960年提出的认知现象,正在数据确权这场21世纪最复杂的产权革命中扮演着关键角色,它像一副有色眼镜,让不同利益方在面对同一组数据时,看到截然不同的"事实",理解这种偏误如何影响政策制定、企业决策和公众认知,是破解当前数据确权困局的关键钥匙。
确认偏误的神经科学基础:我们的大脑如何"制造"真相?
2026年1月,《自然·神经科学》发表了一项突破性研究:麻省理工学院团队通过功能性磁共振成像(fMRI)技术,首次直观展示了确认偏误在大脑中的运作路径,当受试者面对与既有信念相符的信息时,其前额叶皮层(负责理性分析)的活动显著降低,而杏仁核(处理情绪反应)和腹侧纹状体(奖励中枢)的活跃度飙升。
"这解释了为什么人们会本能地排斥相反证据,"研究负责人李教授解释道,"大脑将支持性信息视为'奖励',而将挑战性信息视为'威胁',这种进化形成的机制在原始社会有助于快速决策,但在数据确权这样需要精细权衡的领域,却可能导致灾难性后果。"
真实案例:2026年2月,某头部电商平台在内部会议上展示了一份用户数据使用报告,支持数据商业化的高管团队聚焦于"87%用户同意数据共享"这一数据,而隐私保护团队则强调"仅12%用户真正理解授权条款"的细节,双方都援引同一份报告,却得出完全相反的结论——这正是确认偏误的典型表现。

数据确权战场上的三大偏误陷阱
政策制定者的"框架效应":安全还是创新?
2026年政府工作报告中,数据要素市场建设被列为数字经济核心任务,但不同部门在制定细则时,呈现出鲜明的认知分裂:
- 网信部门引用2025年某起数据泄露事件(涉及5000万用户信息),强调"数据确权必须以安全为前提",推动建立严格的数据分类分级制度。
- 发改委则援引麦肯锡2026年报告《数据流动的经济价值》,指出"过度确权可能阻碍AI发展",主张采用"负面清单"管理模式。
这种对立在地方试点中尤为明显,浙江省2026年出台的《数据条例》要求所有企业数据必须经过脱敏处理才能流通,而广东省同期实施的《数据要素市场化配置改革行动方案》则允许在特定场景下使用原始数据,两地政策制定者都坚信自己的框架更符合国家战略,却忽视了对方方案中的合理成分。
企业的"动机性遗忘":用户权益还是商业利益?
极限运动与低碳出行及绿色处理热度持续上升,相关产业迎来新发展 2026年3·15期间,某智能汽车品牌被曝私下出售用户驾驶数据,在随后的新闻发布会上,公司CTO的回应极具代表性:"我们严格遵守《个人信息保护法》,所有数据交易都经过用户授权。"当记者展示用户协议中"默认勾选"的授权条款时,该高管又改口:"这是行业通行做法,用户如果在意可以手动取消。"
这种矛盾心态在科技行业普遍存在,某头部云计算厂商2026年内部文件显示:其数据合规部门花费大量精力设计"最小必要收集"方案,但产品部门却通过"用户画像优化"等名义持续扩大数据收集范围,更讽刺的是,该公司的年度ESG报告将"数据伦理"列为核心竞争优势,而同期被起诉的侵权案件数量却同比增长40%。

公众的"可得性启发":恐惧还是期待?
2026年社会调查中心的数据显示:68%的受访者支持"数据确权立法",但当被问及具体权利时,只有23%的人能准确说出三项以上数据权益,这种认知落差源于确认偏误的另一种表现——人们更容易记住那些引发强烈情绪的事件。
上海白领张女士的案例颇具代表性:她在2025年遭遇过一次电商平台的精准营销骚扰,从此对所有数据收集都持警惕态度,2026年社区推广数字身份系统时,她坚决反对:"这不就是让企业更方便地监控我们吗?"尽管工作人员解释该系统采用区块链技术实现用户控制,且已有300万居民自愿使用,张女士仍坚持认为"技术不可信"。
突破偏误的实践路径:从对抗到共治
建立"对抗性验证"机制:让不同观点正面交锋
深圳市2026年推出的"数据确权听证会"制度提供了创新范本,每次政策修订前,政府会随机邀请企业代表、法律专家、普通用户和第三方技术机构组成评审团,要求各方必须准备支持自身观点和反驳对方观点的双重材料,在最近一次关于"生物识别数据归属"的听证会上,这种对抗性讨论促使政策制定者将原定的"企业所有"修改为"用户默认拥有,企业可有限使用"。 本月关注产业升级与研学旅行发展动态,技术创新推动产业升级
开发"偏误检测工具":用技术对抗技术
蚂蚁集团2026年开源的"DataBiasChecker"系统正在引发行业变革,该工具能自动分析数据使用协议中的潜在偏误条款,比如通过自然语言处理识别"模糊授权""默认勾选"等模式,在某短视频平台的测试中,系统发现其用户协议中存在23处可能引发确认偏误的表述,经修改后用户投诉率下降67%。

构建"认知多样性"团队:打破信息茧房
极限运动与碳汇交易热度持续走高,行业关注度持续提升 百度2026年重组的数据伦理委员会由程序员、律师、社会学家和普通用户代表组成,规定任何数据政策必须获得至少三个不同背景成员的赞成票,这种结构迫使决策者必须考虑多重视角,在讨论"用户行为数据是否属于个人财产"时,程序员强调技术可行性,律师关注法律风险,社会学家则提醒注意数字鸿沟问题,最终形成的方案兼顾了各方关切。
当AI开始识别人类的偏误
国家公园与绿色服务网热度持续上升,相关产业迎来新发展 2026年最引人注目的突破来自学术界:清华大学团队开发出全球首个"确认偏误识别AI",该系统通过分析政策文件、企业报告和社交媒体文本中的语言模式,能准确预测不同利益方可能存在的认知偏差,在模拟测试中,它成功预警了某医疗AI项目因忽视患者隐私担忧而引发的公关危机,帮助团队提前调整沟通策略。
"我们正在训练AI成为'偏误翻译官',"项目负责人王教授解释,"当企业说'数据共享提升效率'时,AI可以同时呈现'可能牺牲个体隐私'的潜在解读;当政府强调'安全管控'时,AI能补充'可能抑制创新'的另一面声音,这种客观中立的呈现方式,或许能帮助人类突破自身的认知局限。"
数据确权的终极挑战不是技术,而是人性
站在2026年的节点回望,数据确权进程中的每一次争论、每一份政策、每一起诉讼,本质上都是人类与自身认知偏误的博弈,从浙江与广东的政策分歧,到科技巨头们的左右互搏,再到普通用户的爱恨交织,确认偏误像无形的手,塑造着这场变革的每一个细节。
破解这个困局没有灵丹妙药,但越来越多的实践表明:当不同利益方愿意直面自己的认知局限,当技术开始辅助人类进行理性思考,当制度设计主动纳入偏误对抗机制,我们或许能逐步接近那个理想中的平衡点——在那里,数据既是创新的燃料,也是权利的堡垒;既是商业的资产,也是个人的尊严,这不仅是数据确权的胜利,更是人类认知进化的重要一步。