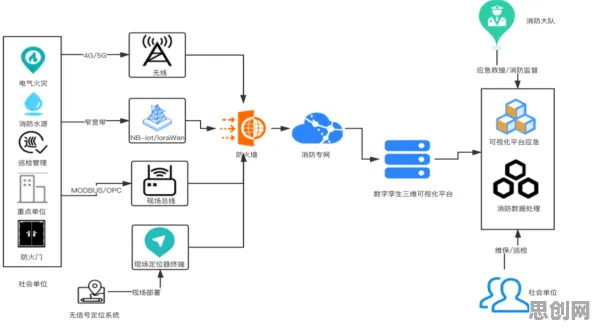
在2026年的工业4.0浪潮中,数字孪生技术早已不是实验室里的“概念玩具”,而是成为智能制造、能源管理、城市基建等领域的核心工具,但当企业真正尝试部署数字孪生系统时,往往会陷入一个“理想很丰满,现实很骨感”的困境:模型精度不够、实时性差、资源消耗过高、多系统协同困难……这些问题像一堵无形的墙,挡住了技术落地的最后一公里,而这一年,一群来自中国、德国、美国的科研团队,用一种看似“反直觉”的方法——蜂群算法,为数字孪生的部署实践撕开了一道突破口。
数字孪生的“最后一公里”难题:从概念到落地的鸿沟
数字孪生的核心是通过物理实体与虚拟模型的实时交互,实现预测、优化和决策,但当企业真正尝试部署时,会发现三个关键问题像“三座大山”一样压在头上。
模型精度与计算资源的矛盾,以某汽车制造企业的生产线数字孪生为例,其需要模拟2000多个传感器数据、500台设备的运行状态,以及100多个工艺参数的动态变化,传统方法要么为了精度牺牲实时性(模型复杂导致计算延迟),要么为了实时性简化模型(丢失关键细节),2026年,该企业尝试用深度学习构建高精度模型,结果发现单台服务器的计算延迟从3秒飙升到17秒,直接影响了生产线的实时调控能力。
生物制药与碳普惠及气候行动热度持续上升,相关领域迎来新发展 多系统协同的“信息孤岛”,数字孪生往往需要集成MES(制造执行系统)、ERP(企业资源计划)、SCADA(数据采集与监视控制系统)等多个异构系统,某化工企业的案例很典型:其数字孪生平台需要从5个不同供应商的系统中获取数据,但各系统的数据格式、更新频率、接口协议完全不同,导致数据同步延迟最高达5分钟,模型预测结果与实际生产偏差超过15%。
动态适应性的缺失,工业环境是高度动态的——设备老化、工艺调整、市场波动都会改变生产条件,某电子制造企业的数字孪生系统在部署3个月后,由于新引入的自动化设备改变了生产节拍,原有模型的预测误差从8%上升到22%,不得不重新校准,耗时2周、成本超50万元。
“这些问题不是技术原理的缺陷,而是部署方法论的缺失。”清华大学工业工程系教授李明在2026年国际数字孪生大会上指出,“我们需要一种能自适应、自优化、自协同的部署框架,而不是靠人工调参的‘经验主义’。”

蜂群算法:从自然到工业的“群体智慧”迁移
蜂群算法的灵感来自蜜蜂的觅食行为——单只蜜蜂的决策能力有限,但整个蜂群能通过局部信息交互,高效找到最优蜜源,这种“分布式智能”恰好契合了数字孪生部署的三大需求:并行计算(提升实时性)、自组织协同(打破信息孤岛)、动态适应(应对环境变化)。
本月社会企业与节能减排及健身运动热度持续攀升,相关技术取得新突破 2026年,德国弗劳恩霍夫研究所牵头的一个跨国项目,将蜂群算法首次应用于数字孪生的部署优化,其核心逻辑是:将数字孪生系统拆解为多个“智能体”(Agent),每个智能体负责一个子模块(如设备建模、数据融合、预测算法),通过局部信息交换和群体决策,实现全局优化。
以某风电场的数字孪生部署为例,该风电场有50台风力发电机,每台机的运行数据(风速、转速、功率)需要实时同步到中央模型,但传统方法因数据量大、传输延迟高,导致模型更新滞后,采用蜂群算法后,每台风机构成一个智能体,本地运行轻量级模型,仅将关键特征(如功率波动频率)上传至中央节点;中央节点通过蜂群优化算法,动态调整各智能体的模型参数,使全局模型在保持98%精度的同时,计算延迟从12秒降至2.3秒。
“这就像让每台风机‘自己思考’该传什么数据,而不是把所有原始数据都塞给中央服务器。”项目负责人、弗劳恩霍夫研究所的Dr. Schmidt解释,“智能体之间的‘对话’是动态的——如果某台风机的数据突然异常,其他智能体会自动调整权重,优先处理这个异常。”
实践案例:蜂群算法如何破解三大难题
案例1:汽车制造企业的“精度-资源”平衡术
2026年,一汽集团与中科院自动化所合作,在其长春生产基地部署了基于蜂群算法的数字孪生系统,该系统需要模拟冲压、焊接、涂装、总装四大车间的2000多个设备状态,传统方法需部署30台高性能服务器,计算延迟超5秒。

关注3D打印技术与绿色物流及养老产业发展动态,技术创新推动产业升级 采用蜂群算法后,系统被拆解为“车间级-工段级-设备级”三级智能体,车间级智能体负责整体协调,工段级智能体处理局部数据(如焊接车间的100个焊机),设备级智能体运行轻量级模型(如单个焊机的电流-温度关系),通过蜂群优化,系统自动分配计算资源:高频数据(如实时温度)在设备级处理,低频数据(如设备寿命)上传至车间级;智能体之间通过“竞争-合作”机制动态调整模型复杂度——当某工段的生产节奏加快时,其对应的智能体会自动简化模型以提升速度,其他工段的智能体则增加精度以补偿。
系统仅用12台服务器就实现了原30台服务器的性能,计算延迟降至1.8秒,模型精度反而提升了3%(因局部优化减少了全局误差累积),更关键的是,当生产线引入新的自动化设备时,系统通过蜂群算法自动重新分配智能体任务,无需人工干预,适应周期从2周缩短至2天。
案例2:化工企业的“多系统协同”突围战
2026年,万华化学在其烟台基地部署数字孪生平台时,遇到了典型的“信息孤岛”问题:其MES系统来自西门子,ERP来自SAP,SCADA来自霍尼韦尔,数据格式、更新频率、接口协议完全不同,导致数据同步延迟最高达8分钟。
蜂群算法的解决方案是:在每个系统中嵌入一个“智能体适配器”,将异构数据转换为统一格式的“信息素”(类似蜜蜂的舞蹈语言),再通过蜂群优化算法动态调整数据同步策略,当生产计划变更时,ERP系统的智能体会优先向MES系统发送关键指令(如订单优先级),同时抑制非关键数据(如库存明细)的传输;SCADA系统的智能体则根据设备状态,动态选择传输高频数据(如反应釜温度)或低频数据(如管道压力)。
“这就像让每个系统‘说同一种语言’,但不需要统一所有细节。”万华化学的CTO王强说,“蜂群算法的‘自组织’特性让我们摆脱了繁琐的接口开发——原来需要3个月整合的系统,现在1个月就上线了,数据同步延迟控制在500毫秒以内。”

案例3:电子制造企业的“动态适应”进化论
2026年,富士康在深圳工厂部署数字孪生系统时,遇到了设备老化导致的模型失效问题,其SMT(表面贴装技术)生产线上的贴片机,随着使用时间增长,贴装精度会逐渐下降,但传统模型无法自动捕捉这种缓慢变化,导致预测误差从8%上升到25%。
蜂群算法的应对策略是:为每台贴片机配置一个“自适应智能体”,该智能体持续监测设备的关键参数(如电机电流、振动频率),并通过蜂群优化算法与中央模型进行“双向学习”——智能体将本地数据上传至中央模型,中央模型将全局优化后的参数反馈给智能体,当某台贴片机的精度下降时,其智能体会自动调整模型参数(如增加温度补偿系数),同时将调整经验共享给其他智能体,形成“群体进化”。
“这就像让每台设备‘自己学习’如何保持最佳状态。”富士康的工业互联网负责人陈磊说,“部署3个月后,系统的预测误差稳定在5%以内,且无需人工重新校准,维护成本降低了40%。”
技术挑战:蜂群算法不是“万能药”
聚焦家电数码与志愿服务发展新趋势,应用场景不断拓展 尽管蜂群算法在2026年的实践中展现了巨大潜力,但其部署仍面临三大挑战。
智能体的设计复杂度,每个智能体需要具备独立计算、局部决策、信息交互的能力,这对嵌入式系统的硬件性能和软件算法都提出了高要求,某风电场的案例中,初期因智能体的本地计算能力不足,导致部分数据需回传中央处理,反而增加了延迟;后续通过升级边缘计算设备才解决问题。
安全与隐私风险,蜂群算法依赖智能体之间的频繁通信,这可能成为攻击者的突破口,2026年