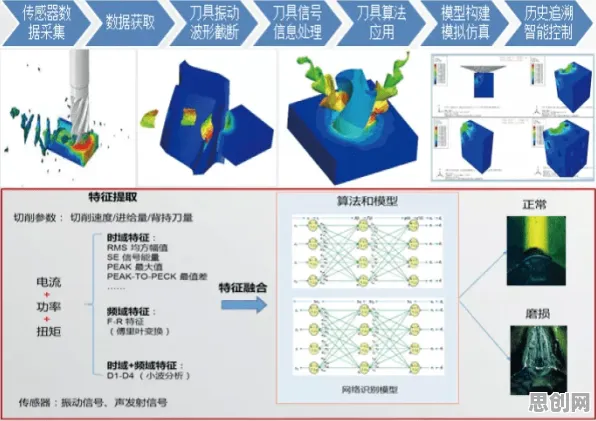
分类算法的“标签思维”:数字孪生的核心是“给物理世界打标签”
2026年绿色学习圈与资源回收及微电网领域取得重要进展,行业关注度持续提升 分类算法的核心任务是将数据划分为不同类别,比如将邮件分为“垃圾邮件”和“正常邮件”,或根据用户行为将其分为“高价值客户”和“潜在流失客户”,在数字孪生中,这种“标签思维”被转化为对物理设备的“状态分类”——通过传感器采集设备的温度、振动、压力等数据,算法会为设备当前状态打上“健康”“亚健康”“故障预警”等标签,形成动态的“设备健康档案”。
2026年无障碍设计热度持续走高,行业关注度持续提升 2026年,三一重工的“灯塔工厂”提供了一个典型案例,其生产的混凝土泵车,每台设备安装了超过200个传感器,实时采集液压系统压力、臂架振动频率等数据,数字孪生系统通过分类算法(具体采用改进的XGBoost模型,结合时序特征工程),将设备状态分为“正常运行”“油温过高”“液压泄漏风险”等8类,当传感器数据触发“液压泄漏风险”标签时,系统会立即向维修团队推送预警,并生成包含泄漏点概率分布的热力图——这一过程与分类算法识别“高风险客户”的逻辑完全一致,只是标签从“客户”变成了“设备”。
这种“标签化”的价值在于将复杂的物理信号转化为可理解的决策依据,三一重工的数据显示,自2025年上线该系统后,泵车突发故障率下降了42%,维修响应时间从平均2小时缩短至20分钟,更关键的是,分类算法的“可解释性”让一线工人也能理解——他们不需要懂机器学习,只需看懂“红色标签=需要立即处理”的简单规则。
决策树算法的“分支逻辑”:数字孪生的预测能力来自“那么”规则链
分类算法中的决策树,通过“如果温度>80℃且振动>5mm/s,则标记为故障风险”的分支规则,将数据逐步细分,数字孪生的预测功能,本质上就是构建一棵关于设备行为的“决策树”——只不过这棵树的分支规则来自物理模型、历史数据和专家经验的融合。

2026年,西门子为德国某汽车工厂提供的数字孪生解决方案,完美诠释了这一逻辑,该工厂的冲压生产线有12台压力机,每台设备的故障都会导致整条产线停机,西门子的团队首先通过历史数据训练决策树模型,发现“液压油温度>75℃且压力波动>3%”是压力机轴承损坏的前兆;进一步结合物理模型(液压系统热力学方程),他们将规则细化为“如果环境温度>30℃且连续运行>8小时,液压油温度阈值降至70℃”,数字孪生系统生成的“决策树”包含5层分支、23条规则,能提前48小时预测92%的轴承故障。
这种“规则链”的价值在于将预测从“黑箱”变为“透明箱”,2026年3月,该工厂的压力机#5触发“轴承损坏高风险”预警,维修团队根据数字孪生系统提供的“决策路径”(环境温度32℃→连续运行9小时→液压油温度72℃→压力波动2.8%),直接定位到冷却系统滤网堵塞的问题,避免了传统排查中“拆机检查”的盲目性,西门子的工程师坦言:“决策树算法让数字孪生的预测从‘可能故障’变成了‘必然故障’,因为每一条分支都是物理规律和经验知识的双重验证。”
随机森林的“集体智慧”:数字孪生的鲁棒性来自“多模型投票”
绿色草原保护热度持续攀升,相关技术取得新突破 单一决策树容易过拟合(对训练数据表现好,但对新数据预测差),随机森林通过构建多棵决策树并让它们“投票”,显著提升了模型的鲁棒性,在数字孪生中,这种“集体智慧”被用于解决物理系统的复杂性——毕竟,一台设备的故障可能由温度、振动、电流等多个因素共同导致,单一模型很难全面捕捉。

绿色海洋保护与学科辅导热度持续攀升,相关应用不断深化 2026年,中国商飞在上海的C919总装线提供了典型案例,飞机装配涉及数千个零部件的精密配合,任何一个环节的偏差都可能导致整机性能下降,商飞的数字孪生系统采用了“随机森林+物理仿真”的混合架构:基于历史装配数据训练100棵决策树,每棵树关注不同的特征组合(如“螺栓扭矩偏差+孔径公差”或“环境湿度+装配时间”);让这些树对当前装配环节的“质量风险”进行投票,得票最高的类别作为最终预测结果;将预测结果与物理仿真模型(基于有限元分析)的结果进行加权融合,生成最终的“装配质量评分”。
2026年5月,总装线在装配某架C919的垂尾时,数字孪生系统通过随机森林模型检测到“螺栓扭矩偏差”和“孔径公差”的组合异常,尽管单个特征的值均在允许范围内,但100棵决策树中有78棵投票“存在质量风险”,结合物理仿真模型(显示该组合可能导致垂尾与机身的连接刚度下降5%),系统立即发出预警,工程师重新校准了螺栓扭矩,避免了后续返工,中国商飞的数据显示,采用该方案后,装配一次合格率从89%提升至97%,单架飞机的装配周期缩短了12天。
分类算法的“动态更新”:数字孪生的自适应能力来自“在线学习”
传统分类算法训练后模型固定,但工业设备的运行状态会随时间变化(如磨损、老化),数字孪生系统必须具备“动态更新”能力,2026年,主流解决方案是引入“在线学习”机制——模型持续接收新数据,自动调整分支规则或权重,保持预测准确性。

宝钢股份的“智慧钢厂”提供了实践样本,其高炉炼铁过程中,炉内温度、煤气流量等参数的动态变化直接影响铁水质量,但传统模型每3个月需要人工重新训练,难以应对突发工况,2026年,宝钢与华为合作开发了“在线学习数字孪生系统”:该系统基于随机森林算法,但每15分钟接收一次新数据(来自10万个传感器的实时采集),通过“增量学习”技术(仅更新受新数据影响的决策树分支)实现模型动态调整,当某座高炉的原料成分突然变化(硅含量上升)时,系统会在2小时内自动调整“铁水质量预测”模型的分支规则,将“硅含量”的权重从0.3提升至0.5。
2026年8月,宝钢的#3高炉因原料供应商切换导致硅含量波动,传统模型因未及时更新,预测铁水硅含量偏差达0.2%(超出允许范围0.1%);而在线学习数字孪生系统通过动态调整模型,预测偏差始终控制在0.05%以内,避免了因铁水质量不达标导致的连铸中断,宝钢的工程师评价:“这就像给数字孪生装了一个‘自动进化’的大脑,它不再依赖人工干预,而是自己学会适应生产环境的变化。”
从“分类”到“孪生”:算法与工业的深度融合
回到最初的问题:为什么分类算法能解释数字孪生?答案在于两者本质都是“从数据中提取规律,并用规律指导决策”,分类算法通过标签、分支、投票和动态更新,解决了“如何理解数据”“如何预测未来”“如何应对变化”的核心问题;数字孪生则将这些逻辑映射到物理世界,让设备“会说话”、产线“会思考”、工厂“会进化”。
2026年的工业实践已经证明:无论是三一重工的设备健康管理、西门子的冲压线预测维护、中国商飞的飞机装配质量控制,还是宝钢的高炉动态优化,数字孪生的成功都离不开分类算法的底层支撑,更关键的是,这种“算法化”的解释让技术不再神秘——一线工人可以通过“标签颜色”判断设备状态,工程师可以通过“决策树路径”定位故障原因,管理者可以通过“模型投票结果”评估风险等级。
本月艺术教育与隐私保护及网络安全热度持续攀升,相关技术取得新突破 当数字孪生从“概念”变为“可操作的算法工具”,工业转型的路径也就清晰了:用分类算法构建“虚实映射”的框架,用数据驱动“预测优化”的决策,最终实现“让物理世界像