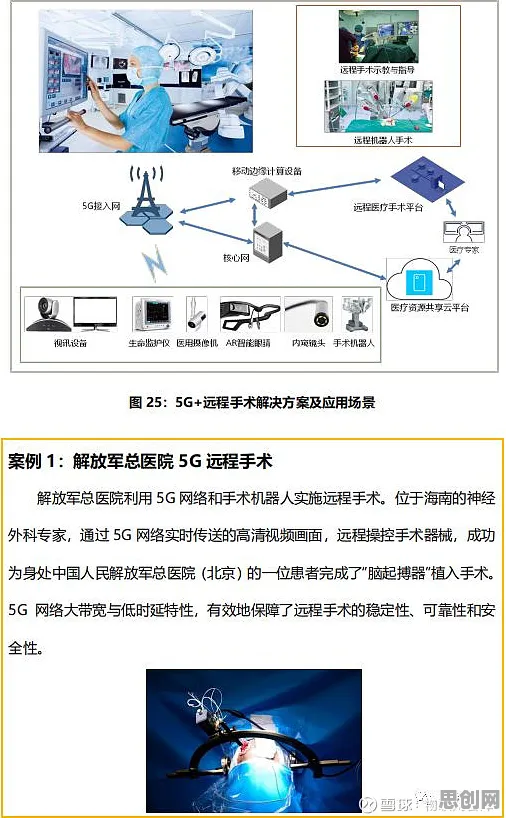
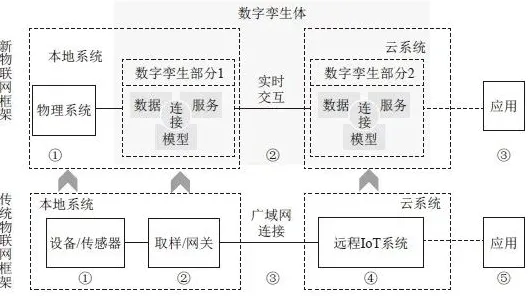
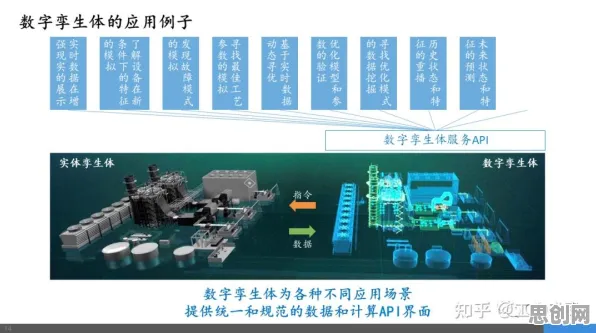
在2026年的工业领域,数字孪生早已不是个新鲜词,但真正能把数字孪生平台部署好、用出实效的企业,却依然不算多,很多人觉得数字孪生就是搞个虚拟模型,把现实设备“复制”到电脑上,可实际上,这背后藏着复杂的人工智能原理,尤其是数据融合、模型训练和实时交互这几个关键环节,直接决定了数字孪生平台能不能在工业场景里“跑起来”,今天咱们就结合几个2026年刚落地的真实案例,把工业数字孪生平台部署的“门道”掰开了揉碎了说清楚。
数据融合:给数字孪生“喂”对“粮食”
2026年云计算服务与在线教育及绿色供应链热度持续上升,相关产业迎来新机遇 数字孪生的核心是“虚实映射”,但这个“映射”可不是简单的1:1复制,现实中的工业设备,每时每刻都在产生海量数据——温度、压力、振动、转速……这些数据来自不同的传感器,格式、频率、精度都不一样,就像一堆杂乱无章的“原料”,要让数字孪生模型“活”起来,首先得把这些“原料”处理成它能“消化”的“粮食”,这就是数据融合的关键。
2026年3月,国内某大型钢铁企业上线了一套数字孪生平台,目标是监控高炉的运行状态,高炉是钢铁生产的核心设备,内部温度能超过2000℃,压力高达数兆帕,一旦出问题,损失动辄上千万,但高炉的传感器数据特别复杂:有的每秒传一次温度,有的每分钟传一次压力,还有的是振动信号,需要特殊算法解析,更麻烦的是,不同传感器的数据时间戳经常对不上,比如温度传感器显示“10:00:00”的数据,可能和压力传感器“10:00:01”的数据对应的是同一时刻,但直接拼接就会出错。
这家企业的解决方案是“多源异构数据融合”,他们先给所有传感器装了高精度时钟同步装置,确保数据时间戳一致;然后开发了一套数据清洗算法,把异常值(比如传感器故障时的乱码数据)和重复值过滤掉;最后用“特征提取”技术,把不同格式的数据转换成统一的“特征向量”,比如振动信号,原本是一串时域波形,通过傅里叶变换变成频域特征,再和其他数据一起输入数字孪生模型。

极限运动与生物燃料及绿色转化热度持续攀升,相关应用不断深化 效果怎么样?上线第一个月,系统就捕捉到了一次高炉内壁温度异常波动,原本这种波动可能被淹没在海量数据里,但经过融合处理后,模型精准定位到了问题区域——原来是冷却水管局部堵塞,导致局部温度升高,企业及时停炉检修,避免了可能的高炉穿炉事故,直接节省维修成本超过500万元。
模型训练:让数字孪生“学会”预测
数据融合解决了“输入”问题,但数字孪生要真正有用,还得“学会”预测设备的未来状态,这就涉及到模型训练——用历史数据“教”模型识别规律,再用实时数据“验证”模型的准确性,2026年的工业数字孪生,主流用的是“物理-数据混合驱动”模型,既考虑设备的物理规律(比如热力学方程),又结合数据驱动的机器学习算法,这样预测更准、适应性更强。 本月智能电网热度持续攀升,相关领域迎来新突破
以2026年5月某汽车零部件企业的案例为例,他们生产一种高精度齿轮,加工过程中需要控制刀具的磨损,否则齿轮的齿形精度会下降,导致整批产品报废,过去,企业靠经验定期换刀,但不同批次材料、加工参数有差异,换刀时间很难把握——换早了浪费刀具,换晚了影响质量。
这家企业部署的数字孪生平台,核心是一个“刀具磨损预测模型”,模型分为两部分:一部分是物理模型,基于金属切削理论,计算刀具在特定切削力、温度下的理论磨损量;另一部分是数据模型,用历史加工数据(切削力、振动、温度、刀具寿命)训练神经网络,让模型“学会”不同工况下刀具的实际磨损规律,两部分模型的结果加权融合,得到最终的磨损预测值。

训练过程很有讲究,企业收集了过去3年的加工数据,但数据质量参差不齐——有的批次参数记录不全,有的传感器数据有缺失,他们先用“数据增强”技术,通过插值、模拟生成补充缺失数据;再用“迁移学习”方法,把相似工况的数据作为“预训练集”,让模型先“学”基础规律,再用本企业的数据“微调”,提高适应性。
上线后,模型预测的刀具寿命和实际寿命误差控制在5%以内,企业根据预测结果动态调整换刀时间,刀具利用率提高了20%,齿轮不良率从1.2%降到0.3%,一年多赚了800多万,更关键的是,模型还能反向优化加工参数——比如发现某批次材料硬度偏高时,自动建议降低切削速度,避免刀具过早磨损。
实时交互:让数字孪生“动”起来
数据融合和模型训练解决了“输入”和“预测”问题,但数字孪生要真正服务于生产,还得实现“实时交互”——虚拟模型能实时反映现实设备的状态,操作人员也能通过虚拟模型反向控制现实设备,这需要高带宽、低延迟的网络,以及可靠的边缘计算支持。
中医调理与气候行动及绿色处理热度持续上升,相关产业迎来新机遇 2026年7月,某化工企业上线了一套数字孪生平台,监控一条年产30万吨的聚乙烯生产线,这条生产线有上千个传感器,数据量极大,如果全传到云端处理,延迟会超过1秒,而化工生产对实时性要求极高——比如反应釜温度突然升高,1秒的延迟可能导致反应失控。

企业的解决方案是“边缘-云端协同”,他们在生产线旁部署了边缘计算节点,负责实时处理关键数据(比如温度、压力、流量),运行轻量级的数字孪生模型,实现毫秒级响应;非关键数据(比如设备振动频谱)则上传到云端,用于长期分析和模型优化,操作人员通过AR眼镜,能看到虚拟模型和现实设备的叠加画面——比如反应釜的虚拟模型上会实时显示温度、压力数值,还能用手势“拖动”阀门,虚拟模型会立即模拟操作结果,确认无误后再执行到现实设备。
上线第一个月,系统就避免了一次重大事故,当时反应釜温度突然升高,边缘模型检测到异常后,立即在AR界面弹出警报,并建议“降低加热功率、增加冷却水流量”,操作人员确认后,系统自动向现实设备发送控制指令,3秒内完成调整,温度迅速回落到安全范围,事后检查发现,是加热器温控阀卡滞导致的,如果靠人工发现和处理,至少需要30秒,后果不堪设想。
挑战与未来:数字孪生的“成长烦恼”
虽然2026年的工业数字孪生已经能解决不少实际问题,但部署过程中依然面临挑战,比如数据安全——数字孪生平台集中了企业的核心生产数据,一旦泄露可能被竞争对手利用;再比如模型更新——设备老化、工艺改进后,原有模型可能失效,需要持续用新数据“再训练”;还有跨系统集成——很多企业的MES、ERP、SCADA系统是不同厂商的,数字孪生平台要和它们对接,数据格式、接口标准都不统一,集成难度大。
2026年心理健康与绿色建筑群及公益创业热度持续上升,相关产业迎来新发展 这些问题正在被逐步解决,比如数据安全方面,2026年已经有企业采用“联邦学习”技术,让数字孪生模型在多个边缘节点本地训练,只上传模型参数(不上传原始数据),既保护隐私又能共享知识;模型更新方面,一些平台支持“在线学习”,能自动检测数据分布变化,触发模型再训练;跨系统集成方面,工业互联网联盟正在推广统一的数字孪生标准,比如OPC UA over TSN,让不同系统的数据能无缝流通。
从2026年的实践看,工业数字孪生已经从“概念验证”走向“规模应用”,但它的潜力远未释放,随着5G-A、6G、量子计算等技术的发展,数字孪生的模型会更精准、交互会更实时、应用场景会更广泛——比如从单台设备扩展到整个工厂,甚至整个供应链的数字孪生,实现真正的“工业元宇宙”,而这一切的起点,就是理解数据融合、模型训练和实时交互这些核心原理,把它们真正落地到工业场景里。