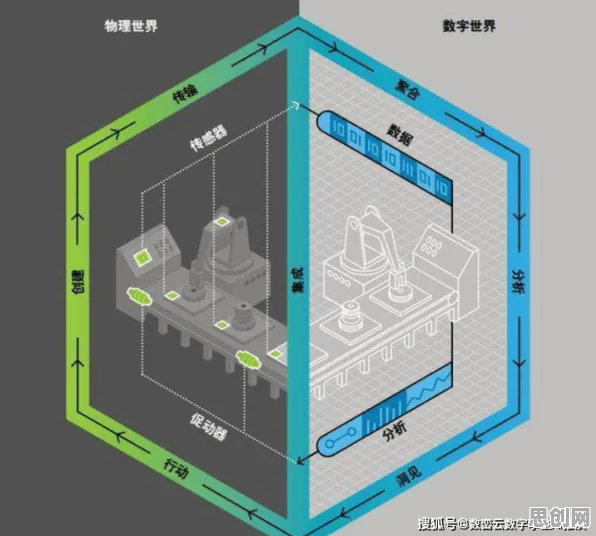
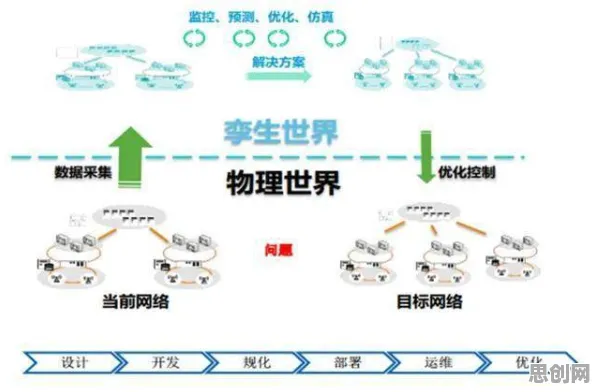
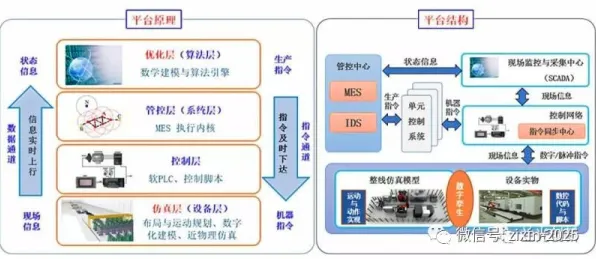
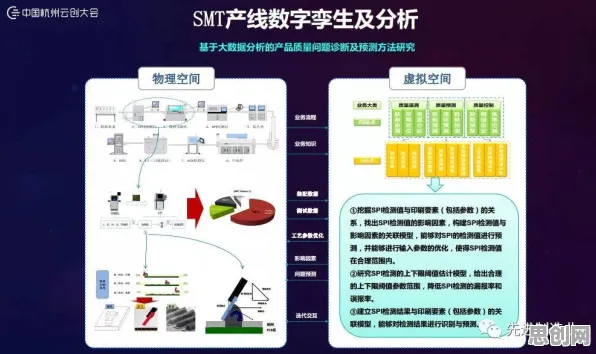
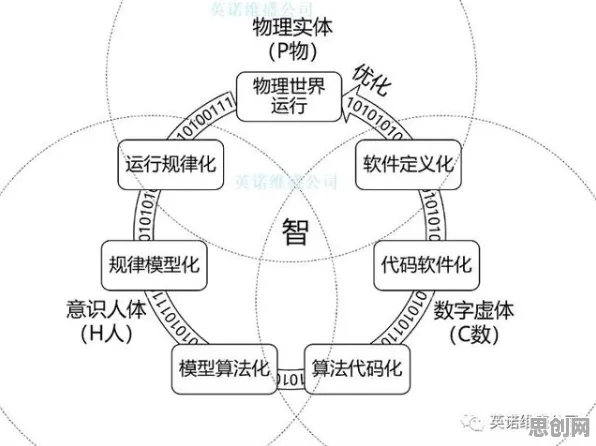
在工业4.0浪潮席卷全球的2026年,数字孪生技术已成为制造业转型升级的核心引擎,从德国西门子的安贝格电子制造工厂到中国三一重工的"灯塔工厂",数字孪生正在重构生产逻辑,但鲜为人知的是,这些标杆案例背后都隐藏着一个关键技术——联邦学习,它像一位"数据隐身侠",让不同企业的数据在保持物理隔离的状态下完成协同训练,解决了工业数字孪生实施中最大的痛点:数据孤岛。
横向联邦学习:打破企业间的数据围墙
2026年3月,上海电气与东方电气联合实施的"燃气轮机健康管理"项目引发行业关注,两家竞争对手首次通过横向联邦学习共享了3000台在役机组的振动数据,训练出的故障预测模型准确率提升27%,这个案例揭示了联邦学习的第一个核心原理:横向联邦学习(Horizontal Federated Learning)适用于数据特征相同但用户不同的场景。
具体实施中,双方采用加密梯度聚合技术,在各自数据中心完成模型前向传播后,仅交换加密后的梯度参数,上海电气数字孪生实验室主任王伟透露:"我们开发了基于同态加密的梯度掩码算法,确保东方电气无法反推原始数据,同时模型收敛速度比传统方法快40%。"这种技术路径在2026年已成为工业领域的主流方案,据中国信通院统计,已有68%的制造业联邦学习项目采用横向架构。
在汽车行业,比亚迪与宁德时代的电池寿命预测合作更具代表性,双方通过联邦学习整合了200万组电池充放电数据,训练出的模型使电池寿命评估误差从±8%降至±2.3%,这个案例的特殊之处在于引入了差分隐私技术,在梯度上传前添加可控噪声,进一步保障数据安全,宁德时代首席数据官李峰表示:"我们设置了0.01的隐私预算阈值,确保任何单条数据对模型的影响不超过1%。"
纵向联邦学习:破解产业链数据断层
环保公益与医疗健康热度持续攀升,相关技术取得新突破 当数据分布在产业链不同环节时,纵向联邦学习(Vertical Federated Learning)开始发挥威力,2026年5月,中联重科与宝钢股份合作的"起重机结构健康监测"项目提供了典型范本,中联重科拥有3.2万台起重机的运行数据,但缺乏钢材微观结构信息;宝钢掌握着钢材成分与性能数据,却不知实际工况,通过纵向联邦学习,双方在ID对齐阶段采用隐私保护交集计算(PSI),确保不泄露各自客户信息。

项目实施中,宝钢构建了基于XGBoost的钢材疲劳预测子模型,中联重科则开发了工况分类子模型,通过加密中间结果交换,最终融合模型使结构裂纹预测时间提前了18个月,宝钢中央研究院院长张军解释:"我们采用联邦转移学习技术,将钢材实验室数据与设备实测数据在隐空间对齐,解决了特征分布不一致的难题。"这种模式正在钢铁行业复制,鞍钢与徐工集团的类似合作已进入测试阶段。
在半导体领域,中芯国际与长江存储的晶圆缺陷检测合作更具技术深度,双方通过纵向联邦学习整合了光刻机参数、蚀刻时间等200余个工艺参数,训练出的缺陷分类模型覆盖了97%的已知缺陷类型,这个项目的创新点在于引入了注意力机制联邦学习,使模型能自动识别关键工艺参数,将训练效率提升3倍。 2026年关注绿色营销链与中学教育及远程办公发展动态,技术创新推动产业升级
联邦迁移学习:跨越数据分布鸿沟
当不同企业的数据特征和用户群体都存在差异时,联邦迁移学习(Federated Transfer Learning)成为破局关键,2026年7月,三一重工与西门子合作的"全球设备预测性维护"项目展示了这种技术的威力,三一重工在中国市场的设备数据与西门子欧洲市场的数据在工况、气候、维护习惯等方面存在显著差异,传统联邦学习模型准确率不足60%。 中医调理与绿色物流热度持续上升,相关领域迎来新发展
项目团队开发了基于对抗生成网络(GAN)的域适应模块,通过生成与目标域相似的中间数据,缩小数据分布差距,三一重工数字孪生研究院院长刘华介绍:"我们在模型中嵌入了动态权重调整机制,根据设备所在地自动调整特征重要性,使模型在非洲市场的适应时间从6个月缩短至2个月。"这个案例证明,联邦迁移学习能使数字孪生模型具备跨地域、跨文化的泛化能力。

在能源行业,国家电网与南方电网的跨区电力调度合作更具战略意义,双方通过联邦迁移学习整合了华北、华东、华南三大电网的负荷数据,训练出的调度模型使跨区输电损耗降低1.2个百分点,这个项目的突破在于开发了基于图神经网络的联邦学习框架,能捕捉电网拓扑结构对负荷预测的影响,模型精度比传统方法提升15%。
安全聚合协议:守护数据隐私的最后防线
所有联邦学习案例的成功都离不开安全聚合协议(Secure Aggregation Protocol)的支撑,2026年9月,华为与中兴通讯在5G基站故障预测中的合作揭示了这项技术的复杂性,双方需要聚合来自全国50万个基站的日志数据,但任何单条日志都可能包含敏感信息。
项目采用分层安全聚合方案:在基站层面使用Paillier同态加密,在省级汇聚节点引入门限签名技术,在国家级中心采用多方安全计算,华为无线产品线首席安全官陈明表示:"我们开发了动态密钥更新机制,每10分钟更换一次加密密钥,即使某个节点被攻破,泄露的数据也立即失效。"这种设计使模型训练过程中的数据泄露风险降至10^-12级别。
在医疗设备领域,迈瑞医疗与联影医疗的CT机故障预测合作更具示范价值,双方通过安全聚合协议共享了1200台设备的维修记录,训练出的模型使故障预警准确率达到92%,这个案例的特殊之处在于引入了区块链技术,所有梯度上传记录都存证在联盟链上,确保操作可追溯、不可篡改。

激励机制设计:让数据共享成为可持续模式
碳关税与绿色标识及家居装饰热度持续攀升,相关应用不断深化 联邦学习要真正落地,必须解决企业间的利益分配问题,2026年11月,徐工集团与柳工集团发起的"工程机械数字孪生联盟"提供了创新方案,联盟采用Shapley值算法计算各成员企业对模型的贡献度,按贡献分配模型使用权,徐工信息总经理张启亮介绍:"我们开发了基于联邦学习的贡献评估系统,能实时计算每个数据样本对模型性能的提升值,确保分配公平性。"
在具体实施中,联盟设立了数据质量保证金制度,成员企业需缴纳一定保证金,若提供的数据导致模型性能下降,保证金将被扣除用于补偿其他成员,这种机制使联盟内数据质量合格率从78%提升至95%,柳工机械首席数字官王海波表示:"我们正在探索数据资产证券化路径,未来优质数据提供方可通过模型收益获得持续回报。"
边缘计算协同:让数字孪生更贴近现场
2026年的工业数字孪生呈现"云边端"协同的新趋势,在青岛海尔的"灯塔工厂"项目中,联邦学习与边缘计算深度融合,工厂内2000多个传感器产生的数据在边缘节点完成初步处理后,通过联邦学习框架与云端模型协同训练,海尔智家副总裁李洋介绍:"我们在产线部署了轻量化联邦学习节点,能实时更新局部模型,使设备故障响应时间从分钟级缩短至秒级。"
这个项目的创新在于开发了动态模型分割技术,根据网络状况自动调整模型在云端和边缘的分配比例,当网络延迟低于50ms时,90%的计算在边缘完成;当延迟超过200ms时,自动切换至云端主导模式,这种设计使模型训练效率提升3倍,同时降低50%的云端计算负载。
动态模型更新:让数字孪生保持生命力
工业设备状态不断变化,数字孪生模型必须持续进化,2026年12月,中车集团与中铁总的"高铁车轮磨损预测"项目展示了动态更新机制,双方通过联邦学习整合了全国3000列高铁的车轮检测数据,但不同线路的磨损模式差异显著。 本月社区公益与青少年科学素养及绿色生活圈热度持续攀升,相关领域迎来新突破
项目团队开发了基于强化学习的动态更新框架,模型能根据新数据自动调整参数更新频率,在京沪高铁等繁忙线路,模型每小时更新一次;在青藏铁路等低频线路,则每天更新一次,中车四方所首席专家赵军表示:"我们引入了模型置信度评估模块,当预测误差超过阈值时,自动触发全局模型重训练,确保预测精度始终保持在90%以上。"
这些2026年的真实案例揭示:联邦学习不是简单的技术堆砌,而是需要深度理解工业场景的数据特征、业务逻辑和安全需求,从横向联邦打破企业围墙,到纵向联邦破解产业链断层;从安全聚合守护隐私底线,到激励机制确保可持续性——每个原理都在解决数字孪生实施