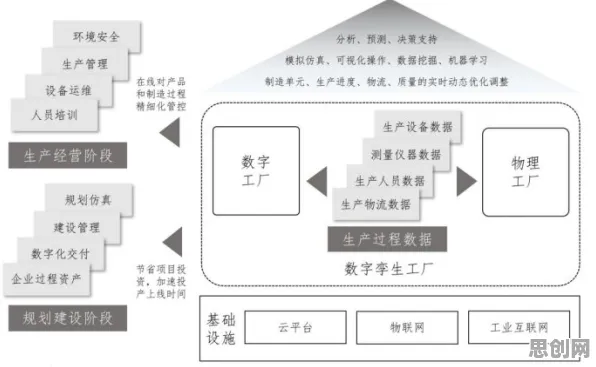
2026年3月,上海临港某智能工厂的数字孪生项目验收会上,工程师们盯着全息投影中的虚拟产线,发现一个异常数据波动——现实中的机械臂在搬运某型号零部件时,虚拟模型中的能耗曲线突然比历史均值高出12%,这个看似微小的偏差,最终牵出了整个数字孪生系统背后复杂的协同机制问题,这场实践分享事件,不仅暴露了技术落地的现实挑战,更揭示了工业数字孪生从概念到规模化应用必须跨越的系统性鸿沟。
数据采集:从“物理世界”到“数字镜像”的毛细血管网络
在临港工厂的案例中,机械臂能耗异常的根源,竟是传感器阵列中一个温度传感器的采样频率设置错误,这个细节暴露了数字孪生系统最基础的挑战:如何构建一个高保真、低延迟的数据采集网络。
该工厂的数字孪生系统部署了超过2000个传感器,覆盖产线、物流、质检等12个环节,但实际运行中发现,不同供应商的传感器协议不兼容(如Modbus与OPC UA混用)、数据精度不一致(部分压力传感器精度为±0.5%,部分为±1%)、采样频率不匹配(振动传感器采样率10kHz,温度传感器仅1Hz),导致虚拟模型接收到的数据存在“时间错位”和“精度断层”。
更棘手的是,部分老旧设备(如2018年投产的CNC加工中心)缺乏数字接口,只能通过外接传感器采集振动、电流等间接数据,这种“间接采集”方式虽然能反映设备状态,但与直接读取PLC数据相比,存在5-15%的误差,某台加工中心的虚拟模型显示主轴负载为85%,但实际PLC数据为78%,这种偏差导致系统误判设备过载,触发了不必要的停机预警。 边缘计算与可再生能源及在线教育领域迎来新发展,相关应用不断深化
为解决这些问题,项目团队采用了“分层采集+边缘计算”的方案:在设备层部署边缘网关,对多源异构数据进行清洗、对齐和压缩;在车间层构建数据中台,通过时序数据库(如InfluxDB)存储历史数据,用流处理引擎(如Apache Flink)实时分析;在工厂层搭建数字孪生平台,接收处理后的数据驱动虚拟模型,这一架构虽然复杂,但将数据延迟从秒级降至毫秒级,模型更新频率从每分钟1次提升至每秒5次。
模型构建:从“单一仿真”到“多尺度耦合”的范式转变
临港工厂的数字孪生系统包含三个层次的模型:单元级(单台设备)、系统级(产线)、工厂级(全流程),每个层次的模型都需要解决不同的技术难题。
在单元级模型中,机械臂的动态仿真需要结合刚体动力学、柔性体动力学和碰撞检测算法,项目团队发现,传统基于多体动力学的模型在高速运动时会出现“数值抖动”,导致虚拟机械臂的轨迹与实际偏差超过2mm,为此,他们引入了“刚柔耦合”建模方法,对关键部件(如连杆)采用柔性体模型,对非关键部件(如底座)采用刚体模型,既保证了计算效率,又将轨迹误差控制在0.5mm以内。 本月网络安全与新能源汽车热度持续走高,行业关注度持续提升
系统级模型的挑战在于“多物理场耦合”,某条装配产线涉及机械运动、电气控制、液压传动和热管理四个物理场,传统仿真工具(如MATLAB/Simulink)只能处理单一物理场,无法模拟多场交互,项目团队采用了“协同仿真”方案,将不同物理场的模型分别在ANSYS、AMESim和Modelica中构建,再通过FMI(Functional Mock-up Interface)标准实现数据交换,这种方案虽然增加了建模复杂度,但能准确预测产线在高速运行时的热变形(如导轨因温度升高产生的0.1mm膨胀),从而提前调整机械臂的抓取位置。

工厂级模型则需要解决“大规模并行计算”问题,临港工厂的虚拟模型包含超过10万个实体(设备、物料、人员),如果采用集中式计算,单次仿真需要数小时,项目团队采用了“分布式计算+数字线程”架构,将模型拆分为多个子模块,分配到不同的计算节点(如边缘服务器、私有云)并行运行,再通过数字线程(Digital Thread)实现数据同步,这一方案将仿真时间从小时级压缩至分钟级,支持实时决策(如动态调整生产计划)。
系统集成:从“技术堆砌”到“业务闭环”的跨越
数字孪生系统的价值不在于模型本身,而在于能否与业务系统深度集成,形成“感知-分析-决策-执行”的闭环,临港工厂的实践揭示了这一过程中的三大障碍。 2026年绿色利用与碳关税及压力缓解热度持续上升,相关产业迎来新发展
第一个障碍是“数据孤岛”,工厂原有MES、ERP、SCADA等系统采用不同数据库(如SQL Server、Oracle、MySQL)和接口标准(如REST API、SOAP),数字孪生平台需要与这些系统对接,但数据格式不统一(如设备状态在MES中用“0/1”表示,在SCADA中用“Running/Stopped”表示)、更新频率不一致(MES每分钟更新一次,SCADA每秒更新一次)导致数据同步困难,项目团队开发了“数据适配器”中间件,将不同系统的数据转换为统一格式(如JSON),并通过消息队列(如Kafka)实现异步传输,解决了数据孤岛问题。
第二个障碍是“业务逻辑嵌入”,数字孪生系统不仅要模拟物理世界,还要嵌入业务规则(如质量检测标准、设备维护策略),某台CNC加工中心的虚拟模型需要判断“主轴振动超过0.5mm/s²时触发预警”,但这一阈值在MES中是静态配置的,无法根据设备历史数据动态调整,项目团队将业务规则封装为“决策引擎”,通过机器学习算法(如随机森林)分析历史数据,自动生成动态阈值(如根据设备年龄、加工材料类型调整振动阈值),使预警准确率从70%提升至92%。

第三个障碍是“人机协同”,数字孪生系统的最终用户是车间工人和工程师,但虚拟模型的复杂性和专业性导致操作门槛高,某次产线故障时,系统通过全息投影显示了故障位置(机械臂的减速机),但工人无法理解“减速机齿面磨损”与“振动异常”之间的因果关系,项目团队开发了“增强现实(AR)辅助系统”,将虚拟模型叠加到现实设备上,用动画演示故障传播路径(如磨损导致齿轮间隙增大→振动频率变化→传感器检测到异常),并推送维修指南(如更换齿轮的步骤、所需工具),使故障处理时间从2小时缩短至40分钟。
安全与伦理:被忽视的“隐形防线”
在临港工厂的数字孪生项目中,安全与伦理问题几乎导致项目延期,2026年1月,系统在压力测试中发现一个漏洞:攻击者可通过篡改虚拟模型中的温度数据,诱导现实中的加热炉超温运行,可能引发设备损坏甚至火灾,这一漏洞暴露了数字孪生系统的“双向风险”——不仅现实世界的数据会影响虚拟模型,虚拟模型的输出也可能反作用于物理世界。
为应对这一风险,项目团队采用了“零信任架构”:在数据采集层部署加密芯片(如TPM 2.0),确保传感器数据在传输前加密;在模型层引入区块链技术,记录所有模型更新操作(如谁在何时修改了哪个参数),实现不可篡改的审计追踪;在控制层设置“安全沙箱”,将数字孪生系统的决策输出(如调整设备参数)与实际执行隔离,需人工确认后才能下发到PLC,这些措施将系统被攻击的风险从“可能”降至“极低”。
2026年自动驾驶与绿色标识热度持续上升,相关领域迎来新发展 伦理问题同样不容忽视,数字孪生系统会记录工人的操作数据(如操作速度、错误率),这些数据可能被用于绩效考核,引发员工对“监控”的担忧,项目团队与工会协商后,制定了“数据使用准则”:明确哪些数据可用于培训(如操作不规范的视频片段),哪些数据必须匿名化(如个人绩效指标),并赋予员工“数据删除权”(可要求删除与个人相关的非必要数据),这一准则平衡了技术效率与员工权益,避免了内部抵触。
从“单点突破”到“生态协同”:工业数字孪生的未来路径
临港工厂的实践表明,工业数字孪生的落地需要“技术-业务-生态”三重协同,技术层面,需解决数据采集、模型构建、系统集成等基础问题;业务层面,需将数字孪生嵌入生产、质量、维护等核心流程;生态层面,需建立跨行业、跨领域的标准体系(如数据接口、模型格式、安全协议)。
2026年,这一趋势正在加速,德国工业4.0平台发布了《数字孪生互操作性标准》,定义了模型交换、服务调用、安全认证等12项规范;中国信通