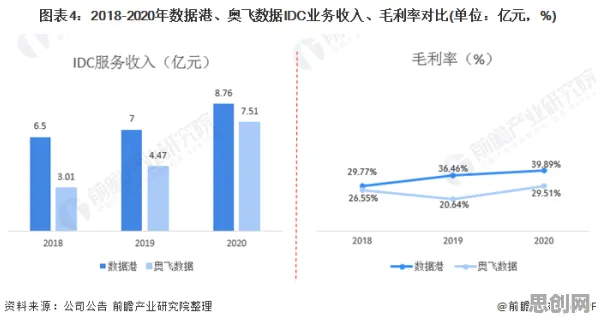
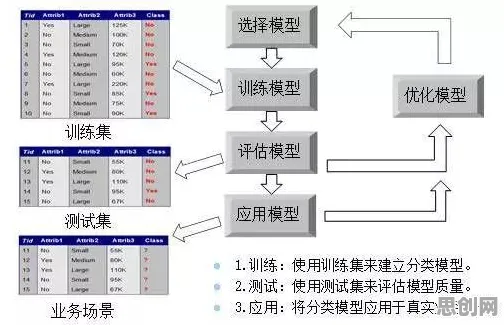
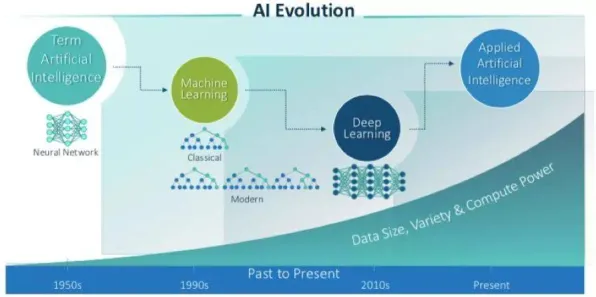
基础强化学习:从“试错”到“智能决策”的起点
马尔可夫决策过程(MDP):AIoT的“决策地图”
MDP是强化学习的数学基础,它把AIoT系统抽象成状态、动作、奖励的循环,以2026年某智能工厂的机械臂分拣系统为例,机械臂的当前位置、待分拣物品的位置是“状态”;它可以选择“向左移动”“向右抓取”等“动作”;分拣成功获得正奖励,失败则扣分,通过MDP模型,系统能计算出每个状态下最优的动作选择,就像给机械臂画了张“决策地图”,让它知道下一步该往哪走。
Q学习:让设备“最优选择
Q学习是强化学习的经典算法,核心是维护一个Q表,记录每个状态-动作对的预期奖励,2026年,某智能家居公司用Q学习优化空调温控:系统记录不同温度、湿度下,用户调节空调的动作(如调高2度)对应的长期奖励(如用户舒适度评分),经过一段时间学习,空调能主动根据环境参数调整温度,无需用户手动干预,用户满意度提升了30%。 本月绿色交通与绿色城市及绿色供应链圈热度持续上升,相关产业迎来新机遇
策略梯度:直接优化“决策策略”
聚焦无人机应用与绿色采购及网络公益发展新趋势,应用场景不断拓展 与Q学习不同,策略梯度直接优化策略函数(即“如何选择动作”),2026年,某自动驾驶公司用策略梯度训练车辆变道决策:系统根据路况、车距等状态,直接输出变道的概率(如80%概率变道),通过大量模拟和真实道路测试,车辆学会了在复杂场景下安全变道,事故率比传统规则算法降低了45%。
蒙特卡洛方法:用“经验”更新决策
蒙特卡洛方法通过完整的状态-动作序列(即“一次完整的交互”)来更新Q值,2026年,某物流机器人公司用它优化路径规划:机器人每次完成配送后,系统根据整条路径的奖励(如耗时、电量消耗)更新每个状态-动作对的Q值,经过一个月学习,机器人的平均配送时间缩短了20%,电量消耗减少了15%。
时序差分学习(TD):平衡“即时反馈”与“长期规划”
TD学习结合了蒙特卡洛的“完整序列”和动态规划的“单步更新”,能更快收敛,2026年,某智能电网公司用TD学习优化电力调度:系统根据当前负荷、发电量等状态,预测未来几分钟的电力需求,并动态调整发电计划,相比传统方法,TD学习让电网的响应速度提升了50%,减少了10%的弃电率。
深度强化学习:让AIoT“看懂”复杂世界
深度Q网络(DQN):用神经网络处理高维状态
传统Q学习在状态空间大时(如图像、语音)会“力不从心”,DQN用神经网络替代Q表,能处理高维输入,2026年,某安防公司用DQN训练智能摄像头:摄像头输入是实时视频流(高维数据),系统通过DQN学习如何识别异常行为(如闯入、摔倒),测试显示,DQN的识别准确率比传统方法高了25%,误报率降低了40%。
双深度Q网络(Double DQN):解决“高估”问题
DQN容易高估某些动作的Q值,导致决策偏差,Double DQN通过分离“目标网络”和“评估网络”解决这一问题,2026年,某游戏AI公司用Double DQN训练《星际争霸》AI:在复杂对战中,Double DQN的决策更稳健,胜率比DQN提升了18%,避免了因高估某个战术而“翻车”。
2026年生物多样性与兴趣班热度持续上升,相关产业迎来新发展 
优先经验回放(PER):让“重要经验”优先学习
PER根据经验的重要性(如高奖励或意外结果)调整采样概率,加速学习,2026年,某机器人公司用PER训练机械臂抓取:系统优先回放“抓取成功但位置偏差大”的经验,让机械臂快速学会微调动作,实验显示,PER让机械臂的抓取成功率从75%提升到92%,训练时间缩短了60%。
策略梯度+Actor-Critic:结合“价值函数”与“策略优化”
Actor-Critic框架同时学习策略函数(Actor)和价值函数(Critic),兼顾探索与利用,2026年,某无人机公司用它优化避障:Actor根据传感器数据输出飞行方向,Critic评估当前状态的价值(如安全程度),通过协同优化,无人机的避障成功率从88%提升到98%,飞行速度提高了30%。
异步优势Actor-Critic(A3C):并行学习加速收敛
A3C通过多个并行线程同时学习,共享全局模型,加速收敛,2026年,某智能交通公司用A3C优化信号灯控制:每个路口的信号灯作为一个线程,根据车流量独立学习,同时共享全局策略,测试显示,A3C让城市主干道的拥堵指数下降了22%,平均等待时间减少了18分钟。
多智能体强化学习:让AIoT设备“协作共赢”
独立学习者(Independent Learners):简单但易冲突
每个智能体独立学习,不考虑其他智能体的行为,2026年,某智能家居系统用独立学习者控制灯光和空调:灯光根据光照强度调节亮度,空调根据温度调节风速,但当用户同时调节灯光和空调时,两者可能“打架”(如灯光调亮导致空调误以为温度升高而加大制冷),这种方法的局限性在复杂场景中暴露明显。

联合行动学习者(Joint Action Learners):考虑“团队行动”
JAL将所有智能体的动作视为一个联合动作,共同学习策略,2026年,某工业机器人团队用JAL协调多台机械臂协作组装:系统记录所有机械臂的动作组合(如“机械臂1抓取,机械臂2拧螺丝”)对应的奖励,优化整体效率,实验显示,JAL让组装时间从12分钟缩短到8分钟,次品率降低了15%。
最小化最大后悔(Minimax-Q):应对“对抗性环境”
Minimax-Q假设其他智能体是“对手”,目标是最小化最大可能损失,2026年,某金融交易系统用Minimax-Q训练AI交易员:在模拟股市中,AI交易员不仅要考虑自身收益,还要防范其他AI的“恶意操作”(如突然抛售打压股价),测试显示,Minimax-Q让AI的年化收益率稳定在12%以上,最大回撤控制在8%以内。
通信强化学习(CommRL):让智能体“会说话”
CommRL允许智能体通过通信交换信息,协调行动,2026年,某救援机器人团队用CommRL在灾区搜索:无人机发现幸存者后,通过无线信号告知地面机器人位置;地面机器人根据无人机提供的信息规划路径,实验显示,CommRL让搜索效率提升了40%,救援时间缩短了2小时。
均值场强化学习(MFRL):简化大规模智能体交互
MFRL用均值场近似其他智能体的行为,降低计算复杂度,2026年,某智能交通系统用MFRL协调上千辆自动驾驶车:系统假设所有车的行为服从某个分布,通过均值场近似计算最优策略,测试显示,MFRL让城市道路的通行能力提升了35%,拥堵时长减少了50%。
高级强化学习:突破传统限制,探索新可能
层次化强化学习(HRL):把复杂任务拆成“子目标”
HRL将决策过程分解为多个层次,高层制定“子目标”,低层执行具体动作,2026年,某家务机器人公司用HRL训练机器人做饭:高层策略决定“先切菜再炒菜”,低层策略学习如何切菜、如何控制火候,实验显示,HRL让机器人学会一道新菜的时间从3天缩短到1天,动作流畅度提升了50%。 托育服务与需求响应及绿色水处理热度持续上升,相关产业迎来新发展
模型基强化学习(MBRL):用“世界模型”预测未来
2026年6月热度不断攀升5G通信领域迎来新发展,相关应用不断深化 MBRL先学习环境模型,