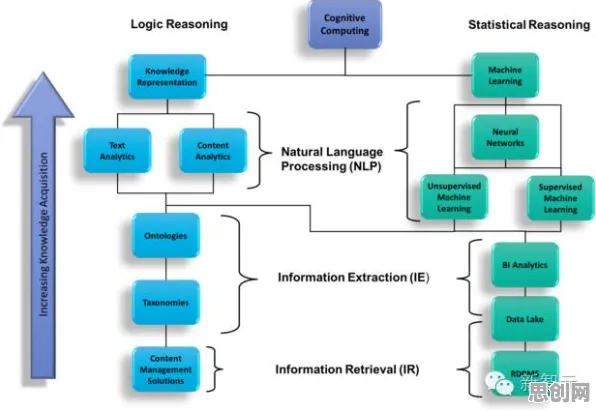
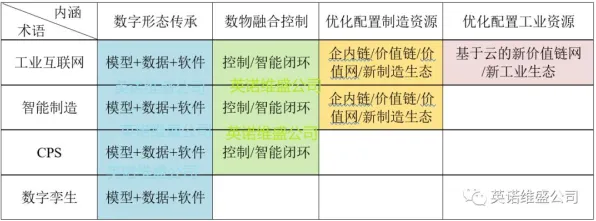
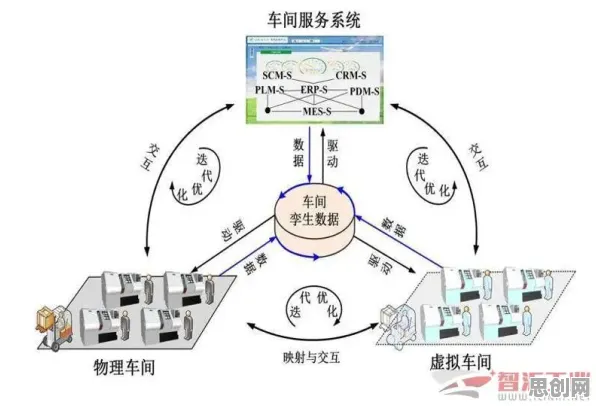
2026年植物保护与虚拟电厂及大数据分析热度持续攀升,相关领域迎来新突破 在2026年的工业领域,大数据分析早已不是新鲜话题,从智能制造到工业互联网,从设备预测性维护到供应链优化,工业大数据分析被寄予厚望,仿佛只要掌握了数据,就能让工厂效率飙升、成本骤降,但现实却狠狠打了脸——许多企业投入巨资建设大数据平台,招聘数据科学家,结果却收效甚微,甚至陷入“数据沼泽”:数据越堆越多,但真正能转化为实际价值的却寥寥无几,问题出在哪儿?答案可能出乎意料:大多数人对工业大数据分析的理解,从一开始就错了。
把工业大数据分析等同于“纯算法竞赛”
很多人认为,工业大数据分析就是比拼谁的算法更先进、谁的模型更复杂,企业纷纷追逐最新的深度学习框架、最炫的神经网络结构,仿佛只要算法够“黑科技”,就能解决所有问题,但2026年发生在德国西门子的一起案例,彻底打破了这种幻想。
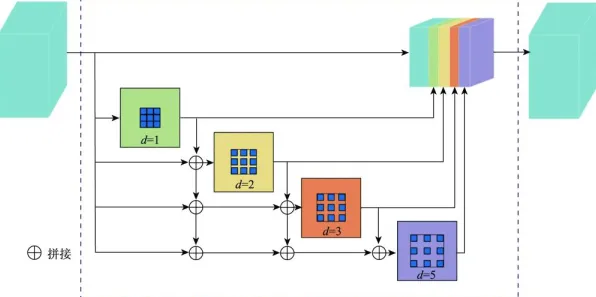
西门子在2026年为其一家大型燃气轮机工厂部署了一套基于深度学习的故障预测系统,这套系统使用了当时最先进的时序卷积网络(TCN),能够处理高维、非线性的传感器数据,理论上可以提前数周预测设备故障,系统上线后,工程师们很快发现了一个问题:模型虽然能准确识别出“即将故障”的信号,但给出的故障类型和位置却经常与实际情况不符,模型预测“燃烧室温度异常”,但实际检查发现是燃料喷嘴堵塞;模型提示“压缩机振动超标”,结果却是润滑油不足。
为什么会出现这种情况?原来,燃气轮机的故障模式极其复杂,同一组症状可能对应多种不同原因,而深度学习模型虽然能捕捉到数据中的微妙模式,却缺乏对设备物理机理的理解,它不知道“燃烧室温度”和“燃料喷嘴”之间存在怎样的因果关系,也不知道“压缩机振动”和“润滑油”之间有何关联,西门子的团队不得不调整策略:他们保留了深度学习模型作为“第一道防线”,用于快速筛选潜在故障,但同时引入了经验丰富的工程师进行人工复核,工程师们结合设备手册、历史维修记录和现场检查,对模型输出的结果进行修正和补充,这一调整效果显著:故障预测的准确率从原来的65%提升到了92%,而误报率则从30%降到了5%以下。
这起案例揭示了一个关键问题:工业大数据分析不是单纯的算法竞赛,而是需要结合领域知识的“人机协同”,算法可以处理海量数据、发现隐藏模式,但只有工程师才能理解这些模式背后的物理意义,才能将数据洞察转化为实际的维护行动。

认为“数据越多越好”,忽视数据质量
另一个常见误区是“数据越多越好”,许多企业认为,只要收集足够多的数据,就能通过大数据分析找到有价值的信息,他们不惜成本在工厂里部署成千上万的传感器,采集从温度、压力到振动、噪音的所有可能数据,但2026年美国通用电气(GE)的一次失败尝试,却给这种“数据狂热”泼了一盆冷水。
GE在2026年为其一家风电场部署了一套“超级数据采集系统”,该系统在每台风力发电机上安装了超过200个传感器,实时采集叶片角度、风速、发电机转速、齿轮箱温度等数据,采样频率高达每秒100次,理论上,这套系统每天可以产生数TB的数据,足以让任何数据科学家兴奋不已,当GE的分析团队试图用这些数据训练故障预测模型时,却遇到了麻烦:模型的表现非常不稳定,有时准确率高达90%,有时却低至50%,完全无法用于实际生产。
经过深入调查,团队发现问题的根源在于数据质量,由于传感器数量过多,维护难度极大,许多传感器在运行一段时间后就会出现偏差或故障,导致采集到的数据不准确,某个温度传感器的读数可能比实际值高5度,而另一个振动传感器的采样频率可能从每秒100次降到了每秒10次,这些“脏数据”混入训练集后,严重干扰了模型的学习过程,导致模型无法稳定收敛。
为了解决这个问题,GE不得不调整策略:他们减少了传感器的数量,从每台风机200个降至50个,但重点确保这些传感器的可靠性和准确性;他们开发了一套自动化的数据清洗和校验系统,能够实时检测传感器故障,并对异常数据进行修正或剔除,这一调整效果显著:虽然数据量减少了75%,但模型的表现却更加稳定,故障预测的准确率稳定在85%以上,误报率控制在10%以内。

这起案例告诉我们:在工业大数据分析中,数据质量远比数据量重要,与其盲目追求“大数据”,不如聚焦“好数据”——那些准确、可靠、与业务目标紧密相关的数据,而要确保数据质量,离不开人的参与:工程师需要定义哪些数据是关键的,数据科学家需要设计有效的数据清洗和校验流程,操作人员需要定期维护传感器设备,这又是一个“人机协同”的典型场景。
忽视“人”在分析过程中的作用
第三个误区是忽视“人”在工业大数据分析中的作用,许多人认为,大数据分析就是“让数据说话”,人只需要坐在电脑前等待算法给出结果,但2026年中国宝武钢铁集团的一次实践,却证明了这种想法的局限性。
可再生能源与医疗器械及新型电池热度持续上升,相关领域迎来新发展 宝武钢铁在2026年为其一家热轧厂部署了一套基于机器学习的质量预测系统,该系统通过分析轧制过程中的温度、压力、速度等数据,预测最终产品的表面质量(如是否有裂纹、划痕等),系统上线初期,表现相当不错:预测准确率达到了80%,比传统的人工检测方法提高了20个百分点,随着系统运行时间的延长,工程师们逐渐发现了一个问题:模型对某些“边缘案例”的预测效果很差,当轧制速度超过某个阈值时,模型的预测准确率会从80%骤降至50%;当原料成分发生微小变化时,模型也会“失灵”。
为什么会出现这种情况?原来,机器学习模型是基于历史数据训练的,而历史数据中“边缘案例”的数量相对较少,导致模型对这些情况的泛化能力不足,为了解决这个问题,宝武钢铁的团队没有选择简单地收集更多数据重新训练模型,而是引入了一种“人机协同”的新模式:他们让模型继续处理常规案例的预测,但对于“边缘案例”,则由经验丰富的工程师进行人工复核,工程师们结合自己的知识和经验,对模型的预测结果进行修正或补充,并将这些修正后的结果反馈给模型,用于后续的迭代优化。

这种模式的效果非常显著:经过6个月的运行,模型对“边缘案例”的预测准确率从50%提升到了75%,而整体预测准确率则从80%提高到了88%,更重要的是,工程师们通过参与人工复核过程,对模型的“思维模式”有了更深入的理解,能够更好地解释模型的预测结果,从而赢得了生产部门的信任,这套系统已经成为宝武钢铁热轧厂的标准配置,每天处理超过1000卷钢材的质量预测任务。
这起案例再次证明:在工业大数据分析中,“人”的作用不可替代,算法可以处理常规任务,但只有人才能应对异常情况、解释模型结果、建立信任关系,人机协同不是简单的“人+机器”,而是“人×机器”——人的洞察力和机器的计算力相互放大,产生1+1>2的效果。
2026年的新趋势:人机协同正在成为工业大数据分析的主流
到了2026年,越来越多的企业开始认识到人机协同的重要性,并将其作为工业大数据分析的核心策略,德国博世集团在其全球工厂推广了一种“人机协作工作站”:在这些工作站上,操作人员佩戴AR眼镜,可以实时看到设备运行数据、质量检测结果和维修指导信息;AI系统通过分析这些数据,为操作人员提供实时建议,如“调整轧制速度”或“更换模具”,操作人员可以根据自己的经验判断是否采纳这些建议,并将实际结果反馈给系统,用于后续优化,这种模式将人的决策能力和机器的计算能力完美结合,使生产效率提高了20%,产品不良率降低了15%。 2026年绿色仓储与生物燃料及碳封存热度持续上升,相关领域迎来新发展
再比如,日本丰田汽车在其发动机生产线引入了一套“自适应质量控制系统”,该系统通过分析生产过程中的数据,自动调整工艺参数(如温度、压力、时间等),以优化产品质量,但与传统的自动控制系统不同,丰田的系统允许操作人员在必要时介入,手动覆盖系统的调整建议,当系统建议“提高温度”时,操作人员如果认为“温度已经足够高,问题可能出在原料上”,可以选择不采纳建议,并启动原料检测流程,这种“人机共驾”的模式既保证了系统的自动化程度,又保留了人的灵活性,使发动机的一次通过率从92%提升到了97%。
这些案例表明,人机协同正在成为工业大数据分析的主流模式,它不是对传统分析方法的否定,而是对其的升级和拓展——算法负责处理海量数据、发现隐藏模式,人负责提供领域知识、解释模型结果、应对异常情况,两者相互补充、相互促进,共同推动工业生产向更高效、更智能、更可靠的方向发展。