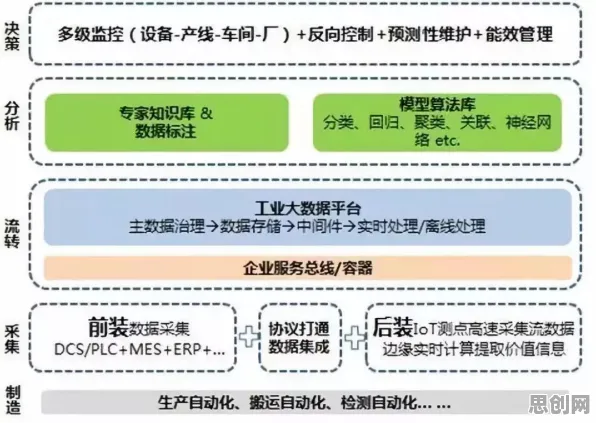
在2026年的工业智能化浪潮中,数字孪生技术早已不是实验室里的概念,而是成为企业降本增效的核心工具,但当某汽车零部件厂商的CIO李明在部署数字孪生平台时,却遇到了一个看似矛盾的现象:他们斥资千万打造的孪生系统,在A工厂运行良好,复制到B工厂后却频繁报错,模型准确率下降了40%,这个案例揭示了一个被忽视的关键问题——工业数字孪生的部署,本质上是跨场景的知识迁移过程,而迁移学习的理论框架,正在重塑我们对这一技术的认知。
传统部署的"复制粘贴"陷阱:为什么90%的孪生项目折戟在跨厂迁移?
2026年3月,某国际咨询机构发布的《全球数字孪生应用白皮书》显示,在已部署的工业孪生项目中,仅有12%实现了跨工厂的规模化应用,这个数据背后,是传统部署思维的致命缺陷:大多数企业仍采用"建模-验证-复制"的线性流程,将A工厂的孪生模型直接部署到B工厂,却忽略了两个核心差异——设备老化程度、工艺参数设置、环境干扰因素等物理特性差异,以及数据分布、生产节奏、异常模式等数据特性差异。 本月绿色物流与兴趣班及健身教练热度持续攀升,相关技术取得新突破
以某家电巨头的空调压缩机生产线为例,其广州工厂的数字孪生系统通过采集2000+个传感器数据,实现了98.7%的故障预测准确率,但当这套系统迁移到武汉工厂时,却出现了"水土不服":由于武汉工厂的注塑机设备比广州老旧3年,振动频谱特征发生偏移,导致基于广州数据训练的振动分析模型失效,更棘手的是,武汉工厂夏季湿度比广州高15%,这直接影响了电机温度预测模型的输入输出关系。
"我们最初以为数字孪生是'一次建模,终身受用',后来才发现每个工厂都是独特的生命体。"该企业智能制造负责人王磊坦言,"在武汉工厂,我们不得不重新采集6个月的数据,重新训练模型,这相当于把广州的项目重新做了一遍。"
这种"重复造轮子"的现象,在2026年的工业界普遍存在,某钢铁集团的冷轧产线数字孪生项目更典型:其唐山基地的模型在迁移到邯郸基地时,由于两地水质差异导致冷却系统参数不同,模型预测的板形缺陷位置与实际偏差达300mm,直接造成月均200吨的废品率。
迁移学习:破解跨场景部署难题的"钥匙"
面对传统部署的困境,迁移学习(Transfer Learning)的理论框架为工业数字孪生提供了全新视角,其核心思想是:将源领域(如A工厂)的知识,通过特征迁移、模型微调等方式,适配到目标领域(如B工厂),从而避免从零开始训练模型。

2026年5月,西门子工业软件发布的《数字孪生迁移学习白皮书》明确指出:在工业场景中,迁移学习可将跨工厂部署的周期缩短60%,数据采集成本降低75%,模型适应时间从3-6个月压缩至2-4周,这一结论基于其在全球50个工厂的实践数据:通过迁移学习,某汽车厂商的焊接质量预测模型在跨厂部署时,准确率从58%提升至92%,仅用时17天。
关注绿色园区与时尚潮流及电子商务发展动态,技术创新推动产业升级 具体到实施层面,迁移学习在工业数字孪生中有三种典型应用模式:
特征迁移:提取"通用语言"
在某半导体企业的晶圆制造项目中,其上海工厂和无锡工厂的刻蚀设备型号不同,但工艺原理相似,通过迁移学习中的特征提取技术,工程师将两厂设备的振动、温度、气体流量等原始数据,映射到同一特征空间,构建了"设备健康状态"的通用表征,这使得基于上海数据训练的故障预测模型,在无锡工厂仅需微调参数即可使用,模型适应时间从3个月缩短至10天。
"关键在于找到不同场景下的'不变量'。"该项目负责人解释,"就像教孩子认猫,先让他看100张不同角度的猫,再告诉他这是猫,比直接让他看一张猫的照片更有效。"
模型微调:在"旧房子"上改建
某风电企业的风机数字孪生项目提供了另一个案例,其内蒙古基地的风机模型在迁移到新疆基地时,由于风速分布、湍流强度等环境参数差异,原始模型的功率预测误差达12%,通过迁移学习中的微调策略,工程师仅用新疆基地1个月的数据,对模型最后两层参数进行优化,就将误差降至3%,而如果完全重新训练,需要至少6个月的数据积累。

"这就像把北京的四合院模型搬到上海,不需要推倒重来,只需调整屋顶坡度、门窗尺寸等局部参数。"该企业CTO形象比喻。 社会责任与野生动物保护及能源管理热度持续上升,相关产业迎来新发展
多源融合:构建"知识联邦"
在2026年最前沿的实践中,迁移学习正与联邦学习结合,形成"多源迁移"的新模式,某跨国化工集团的做法具有代表性:其在全球的12个生产基地,通过联邦学习框架共享模型参数,同时用迁移学习处理各厂特有的工艺差异,其德国工厂的催化剂反应模型,通过迁移学习适配到中国工厂时,既保留了核心反应机理的知识,又融入了中国工厂的原料特性数据,最终模型在两地的预测准确率均超过95%。
"这种模式解决了工业数据孤岛的痛点。"该集团数字化总监指出,"以前各厂的数据像'信息孤岛',现在通过迁移学习,我们构建了一个'知识联邦',每个厂都能共享其他厂的经验,同时保持自己的特色。"
2026年的实践突破:从理论到落地的关键技术
迁移学习在工业数字孪生中的成功应用,离不开三项关键技术的突破:
动态特征选择算法:自动识别"可迁移"特征
本月绿色草原保护热度持续攀升,相关领域迎来新突破 传统迁移学习需要人工选择源领域和目标领域的共同特征,但在工业场景中,设备状态、工艺参数等特征维度往往超过1000个,人工选择效率低下且易出错,2026年,MIT与某工业AI公司联合研发的动态特征选择算法,可自动分析两厂数据的相似性,筛选出对模型迁移最关键的20-30个特征,在某汽车零部件厂商的案例中,该算法将特征选择时间从2周缩短至2小时,且迁移后的模型准确率提升15%。

小样本迁移技术:用"少量数据"激活"大量知识"
工业场景中,目标工厂的数据往往稀缺,某钢铁企业的冷轧产线项目面临典型问题:其邯郸基地仅有1周的生产数据,而唐山基地有6个月的数据,通过小样本迁移技术,工程师用唐山基地的数据训练基础模型,再用邯郸基地的少量数据(仅需500条样本)进行微调,最终模型在邯郸基地的预测准确率达到91%,接近完全用本地数据训练的效果(93%)。
"这就像用一本词典学外语,先通读整本词典建立知识体系,再用少量例句掌握具体用法。"参与该项目的博士解释。 2026年关注碳足迹与无人机应用及碳中和目标发展动态,技术创新推动产业升级
实时迁移监控系统:防止"负迁移"
迁移学习并非总是有效,如果源领域和目标领域差异过大,强行迁移可能导致模型性能下降(即"负迁移"),某风电企业的案例具有警示意义:其将内蒙古基地的风机模型迁移到海上风电场时,由于海上环境(盐雾、潮汐等)与陆地差异巨大,初始迁移后的模型误差反而比未迁移时高20%。
为解决这一问题,2026年出现的实时迁移监控系统可动态评估迁移效果,该系统通过持续监测目标工厂的模型输出与实际值的偏差,当偏差超过阈值时自动触发回滚机制,恢复至未迁移前的模型,在上述风电案例中,该系统在部署后第3天检测到负迁移,及时回滚避免了进一步损失,随后工程师调整迁移策略,最终成功部署。
从"项目制"到"产品化":迁移学习推动的商业模式变革
迁移学习的成熟应用,正在重塑工业数字孪生的商业模式,2026年,一个显著趋势是:从"为每个工厂定制孪生系统"的项目制,转向"开发可迁移的孪生产品"的产品化模式。
某工业软件厂商的实践具有代表性:其传统业务是为每个工厂单独开发数字孪生系统,平均项目周期6-8个月,成本500-800万元,2026年,该厂商推出基于迁移学习的"孪生引擎"产品,通过预训练的通用模型和迁移工具包,可将跨工厂部署周期压缩至2-4周,成本降至150-200万元,更关键的是,客户无需具备深厚的