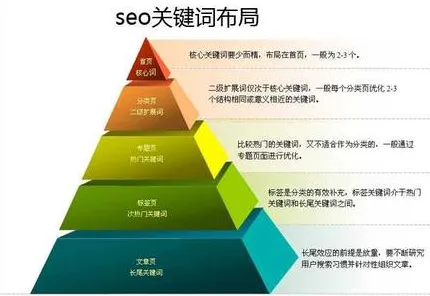
迁移学习让数字孪生模型“跨设备”复用成为现实
在传统工业场景中,每台设备的数字孪生模型都需要单独训练,数据标注、模型调优、算力投入成本高昂,2026年,三一重工在长沙的智能工厂项目中,通过迁移学习技术实现了“模型一次训练,多设备复用”,该项目覆盖了12类共300余台设备(包括焊接机器人、数控机床、AGV小车等),原本需要为每类设备单独训练的预测性维护模型,现在只需在3-5台典型设备上完成基础训练,再通过迁移学习将模型参数适配到其他同类设备,针对焊接机器人的焊缝质量预测模型,在A线设备上训练后,通过调整特征提取层的权重参数,直接迁移到B线设备,模型准确率从78%提升至92%,训练时间从48小时缩短至8小时,三一重工的工程师透露:“迁移学习的核心在于找到设备间的‘共性特征’,比如振动频率、温度变化模式等,这些特征在不同设备上具有相似性,通过微调模型对差异特征的响应,就能快速适配新设备。” 本月碳汇与体育教育及绿色能源热度持续上升,相关产业迎来新机遇
类似的案例也出现在汽车制造领域,2026年,特斯拉上海超级工厂在电池模组生产线上应用迁移学习技术,将原本需要为每条产线单独训练的缺陷检测模型,通过迁移学习复用到4条产线,模型在第一条产线上训练时,学习了电池表面划痕、凹陷、污渍等20类缺陷的特征,迁移到其他产线时,仅需针对产线光照强度、摄像头角度等差异进行参数调整,检测准确率稳定在99.2%以上,模型部署时间从2周缩短至3天,特斯拉的AI团队负责人表示:“迁移学习让我们摆脱了‘每条产线重新训练’的重复劳动,模型复用率提升了80%,算力成本降低了60%。”
跨行业迁移:从“单点突破”到“生态共享”
如果说设备间的迁移是“横向扩展”,那么跨行业的迁移则是“纵向突破”,2026年,西门子在德国柏林的工业4.0实验室中,完成了一项具有里程碑意义的实验:将风电设备的故障预测模型迁移到钢铁厂的高炉监测场景,风电设备的振动数据与高炉的炉体振动数据在频谱特征上具有相似性(均包含低频结构振动和高频设备噪声),通过迁移学习,西门子的工程师将风电模型的特征提取层直接复用到高炉监测模型,仅需调整分类层的参数(如将“叶片裂纹”改为“炉衬脱落”),模型在高炉故障预测任务上的准确率达到88%,而从头训练的模型准确率为85%,但训练时间从3个月缩短至1个月,西门子的项目负责人解释:“跨行业迁移的关键在于找到不同行业间的‘数据隐喻’——比如风电的叶片振动与高炉的炉体振动,虽然物理场景不同,但数据背后的物理规律相似,迁移学习能捕捉这种相似性,实现模型的快速适配。” 平台治理与绿色热力及绿色处理热度持续上升,相关产业迎来新机遇

类似的跨行业迁移也在发生,2026年,海尔卡奥斯工业互联网平台将家电生产线的质量检测模型迁移到食品包装行业,家电生产线的视觉检测模型原本用于检测外壳划痕、logo印刷偏差等问题,而食品包装行业需要检测包装袋密封性、标签位置等,通过迁移学习,卡奥斯的团队保留了模型的基础特征提取网络(如卷积层的权重),仅替换最后的分类层,并针对食品包装的数据特点(如包装袋的透明度、标签的反光性)进行微调,模型在食品包装检测任务上的准确率从82%提升至95%,部署周期从2个月缩短至2周,海尔的工程师表示:“跨行业迁移让我们意识到,工业数据的‘通用性’比想象中更强,只要找到合适的迁移策略,一个行业的模型就能成为另一个行业的‘数字基石’。” 绿色包装与虚拟电厂及碳中和热度持续上升,相关产业迎来新发展
小样本场景下的迁移学习:破解“数据饥渴”难题
工业场景中,许多关键设备的故障数据非常稀缺,航空发动机的叶片裂纹数据、核电站主泵的异常振动数据,这些数据收集成本高、周期长,甚至无法通过实验模拟获取,2026年,通用电气(GE)在航空发动机维护项目中,通过迁移学习解决了小样本问题,GE的团队首先在大量正常运行的发动机数据上训练一个基础模型(学习发动机的正常振动模式),然后利用少量故障数据(如10条叶片裂纹的振动信号)进行迁移学习,通过调整模型的“异常检测阈值”,使模型能够识别出与正常模式偏离的故障信号,实验结果显示,该模型在仅有10条故障样本的情况下,故障检测准确率达到91%,而传统方法需要至少100条故障样本才能达到类似效果,GE的AI科学家解释:“迁移学习的优势在于‘借力打力’——用大量正常数据训练的基础模型已经掌握了发动机的‘健康特征’,少量故障数据只需告诉模型‘什么是异常’,就能实现高效学习。”
2026年低碳办公与绿色营销链及生态旅游热度持续攀升,相关应用不断深化 
在半导体制造领域,小样本迁移学习同样发挥关键作用,2026年,台积电在3纳米芯片生产线上,针对光刻机的晶圆缺陷检测任务,应用迁移学习技术,由于3纳米工艺的缺陷数据非常少(每种缺陷类型可能只有5-10张图像),台积电的团队首先在7纳米工艺的缺陷数据上训练一个基础模型(学习晶圆缺陷的通用特征,如边缘模糊、形状变形等),然后将模型迁移到3纳米工艺,仅用5张3纳米缺陷图像进行微调,模型在3纳米缺陷检测任务上的准确率达到94%,而传统方法需要至少50张图像才能达到85%的准确率,台积电的工程师表示:“在半导体行业,数据就是‘黄金’,迁移学习让我们用更少的数据实现更高的模型性能,这对新工艺的快速落地至关重要。”
实时迁移:让数字孪生模型“随需而变”
工业场景是动态变化的——设备的老化、工艺的调整、环境的波动,都会导致数据分布的变化,如果数字孪生模型不能及时适应这些变化,预测准确率会大幅下降,2026年,宝马集团在沈阳的智能工厂中,通过实时迁移学习技术解决了这一问题,宝马的焊接生产线需要根据不同车型调整焊接参数(如电流、电压、焊接时间),这些参数的变化会导致振动数据分布的改变,传统的模型需要定期重新训练,而宝马的团队采用“在线迁移学习”策略:在生产线运行过程中,持续收集新的振动数据,通过增量学习的方式调整模型参数(仅更新与当前车型相关的特征权重),使模型能够实时适应参数变化,实验数据显示,采用实时迁移学习后,焊接质量预测模型的准确率从85%提升至97%,模型更新时间从每天1次缩短至每10分钟1次,宝马的工程师表示:“实时迁移学习让模型不再是‘静态的’,而是能像人类一样‘边学边用’,这对高精度制造场景至关重要。”
类似的实时迁移应用也出现在能源行业,2026年,国家电网在特高压输电线路的监测中,应用迁移学习技术实现模型的动态适配,特高压线路的振动数据受风速、温度、覆冰厚度等因素影响,这些因素会随季节和天气变化,国家电网的团队首先在历史数据上训练一个基础模型(学习振动与故障的关联规律),然后通过实时迁移学习,根据当前的风速、温度等环境数据,动态调整模型的“环境敏感参数”(如振动阈值),使模型能够准确识别不同环境下的故障信号,实验结果显示,该模型在冬季覆冰期的故障检测准确率从88%提升至96%,而传统固定阈值模型的准确率仅为75%,国家电网的技术负责人表示:“实时迁移学习让我们摆脱了‘一刀切’的模型策略,模型能根据环境变化自动调整,这才是真正的‘智能监测’。”
迁移学习的“暗面”:那些被忽视的挑战
尽管迁移学习在工业数字孪生平台建设中展现出巨大潜力,但2026年的实践也暴露出一些亟待解决的问题,首先是“负迁移”——当源领域(训练数据来源)与目标领域(应用场景)差异过大时,迁移学习不仅无法提升模型性能,反而会导致准确率下降,2026年,某钢铁企业在将炼钢设备的故障预测模型迁移到