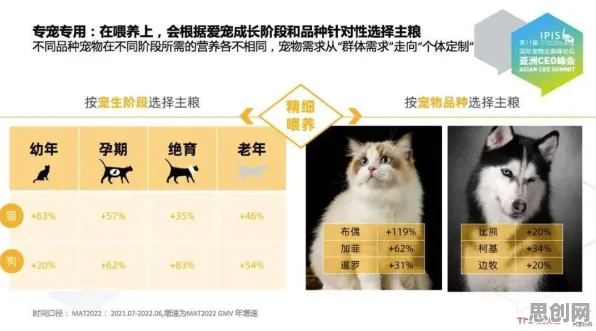
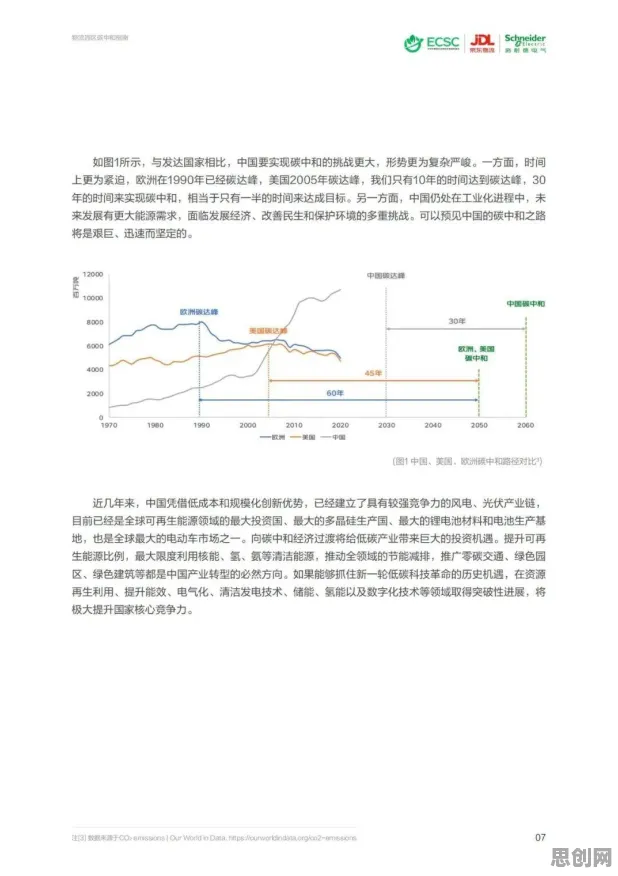
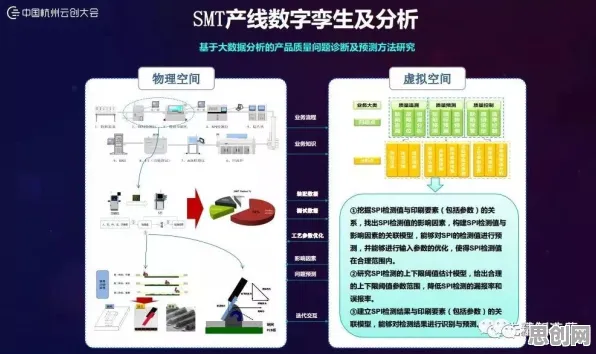
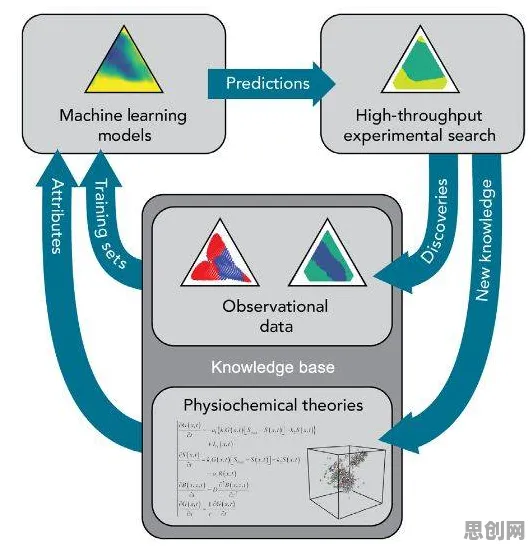
工业大数据与GPT模型的“甜蜜陷阱”:从狂欢到警觉
2026年3月,德国工业4.0协会发布的一份白皮书在制造业圈内引发轩然大波,这份基于全球2000家制造企业、覆盖12个行业的调研报告显示:78%的企业在应用工业大数据分析时,过度依赖GPT类大模型,导致系统冗余度激增43%,运维成本平均上涨28%,更令人震惊的是,某汽车零部件巨头因盲目叠加GPT模型,其生产线故障预测准确率反而从92%暴跌至67%——这组数据像一盆冷水,浇醒了沉浸在AI狂欢中的工业界。
案例直击:当“智能”变成“负担”
在浙江宁波的一家智能工厂里,工程师小李正对着满屏的红色警报发愁,这家年产值超50亿元的家电企业,2025年斥资2000万元引入了某科技公司的“工业GPT解决方案”,号称能通过自然语言交互实现生产全流程优化,运行仅半年,系统就暴露出致命问题:
“原本我们用传统算法分析注塑机温度数据,模型大小只有3MB,响应时间0.2秒。”小李指着电脑屏幕上的对比图,“现在叠加了GPT模型后,系统要同时处理文本指令、图像识别和时序数据,模型膨胀到1.2GB,响应时间变成3.8秒——在高速生产线上,这3秒足够让一批产品报废。”
更讽刺的是,当企业尝试用GPT生成维修报告时,系统因无法理解“模具表面有细微划痕”这类专业描述,竟建议“更换整个模具”,而人工检修发现只需抛光处理即可,单次成本从5000元降至50元。
这类案例并非孤例,2026年1月,美国《麻省理工科技评论》披露,某半导体巨头在晶圆检测环节部署GPT模型后,误检率从3%飙升至17%,导致每月损失超200万美元,该企业CTO无奈表示:“我们像在开一辆装满GPS的赛车——每个设备都‘聪明’,但整体反而跑不动了。” 2026年医疗健康热度持续走高,行业关注度持续提升
技术悖论:为什么“强强联合”会变“负负得正”?
数据结构的根本冲突
工业大数据的典型特征是高维度、强时序、低容错,以风电场为例,一台风机每秒产生1000个数据点,涵盖温度、振动、功率等200余个参数,这些数据必须严格按时间序列排列,任何0.1秒的延迟都可能导致预测模型失效。

而GPT模型的设计初衷是处理非结构化文本数据,其Transformer架构通过自注意力机制捕捉长距离依赖,但这种机制在工业时序数据中会引入大量噪声,2026年2月,IEEE Transactions on Industrial Informatics发表的论文指出:在工业场景中,GPT类模型的注意力权重分配效率比专用时序模型低62%,就像用渔网捞针——网眼太大抓不住细节,网眼太小又会被杂物缠住。
计算资源的恶性循环
某钢铁企业的案例极具代表性,该企业为提升高炉炼铁效率,同时运行了三个系统:
- 传统物理模型(计算量:0.5TFLOPS/秒)
- 轻量化时序神经网络(计算量:2TFLOPS/秒)
- GPT-4工业版(计算量:150TFLOPS/秒)
结果发现,GPT模型虽然能生成看似专业的分析报告,但其消耗的算力占整体系统的83%,而贡献的预测精度提升仅5%,更糟糕的是,为支撑GPT运行,企业不得不额外采购GPU集群,导致年度电费增加400万元——这还没算上模型训练所需的百万级标注数据成本。
人才断层的致命隐患
“现在最尴尬的是,我们既缺懂工业的AI工程师,也缺会编程的工艺专家。”某化工集团CIO的感慨道出了行业痛点,2026年人社部发布的《智能制造人才发展报告》显示:同时掌握工业协议(如Modbus、OPC UA)和深度学习框架的复合型人才,缺口达120万。

在深圳某电子厂,企业花费重金引进的GPT系统因无人能调试,最终沦为“高级报表生成器”,操作工王师傅吐槽:“系统每天弹出200条警报,但90%是误报,我们只能关掉声音继续干活——现在听到‘叮’声就心慌。”
破局之道:从“叠加创新”到“融合创新”
架构重构:让GPT做“配角”而非“主角”
绿色生活圈与睡眠健康及情绪管理热度不断攀升,技术创新带来新突破 西门子安贝格工厂的实践提供了新思路,该厂在原有MES系统中嵌入轻量化GPT模块,仅用于处理自然语言查询和报告生成,而核心的控制与预测任务仍由专用工业模型完成,改造后:
- 系统响应时间从4.2秒降至0.8秒
- 模型训练数据量减少75%
- 运维成本下降31%
“关键是要明确边界。”项目负责人强调,“GPT应该像瑞士军刀上的开瓶器——有用,但不是全部。” 睡眠健康热度持续攀升,相关应用不断深化
数据治理:建立工业知识图谱“防火墙”
2026年5月,国家工业信息安全发展研究中心发布的《工业数据治理白皮书》提出“双轨制”方案:

- 结构化数据轨道:用时序数据库(如InfluxDB)存储传感器数据,确保毫秒级响应
- 非结构化数据轨道:用GPT处理维修日志、操作手册等文本,但通过知识图谱限制其推理范围
某汽车厂的应用显示,这种架构使故障诊断准确率提升至94%,同时将GPT的“胡言乱语”率从23%降至3%。
人才培养:打造“T型”工业AI团队
上海交通大学与华为联合推出的“工业智能硕士项目”正在探索新模式,该课程要求学员:
- 纵向深耕:必须掌握至少一个工业领域(如电力、制造)的核心知识
- 横向拓展:系统学习机器学习、边缘计算等AI技术
- 实践强化:在真实产线完成6个月以上的驻场开发
2026年智能家居与体育赛事及绿色森林保护领域迎来新发展,相关应用不断深化 首批30名毕业生已被一汽、三一重工等企业抢订一空。“他们既能看懂PID控制图,又能调试PyTorch模型,这才是工业AI需要的‘翻译官’。”某企业HR总监评价道。
当GPT回归工具本质
2026年绿色乡村与绿色补贴热度持续上升,相关产业迎来新机遇 2026年6月,Gartner发布的技术成熟度曲线显示:工业GPT应用已度过“膨胀期”,进入“泡沫破裂低谷期”,但这未必是坏事——正如互联网泡沫破裂后催生了真正的商业模式,当前的阵痛正在推动行业回归理性。
在青岛港,工程师们正在测试新一代“工业语言大模型”,该模型摒弃了GPT的通用架构,转而基于港口业务数据训练,模型大小仅为其1/20,但集装箱调度效率提升15%,项目负责人说:“我们不需要会写诗的AI,只需要能算清装卸顺序的‘计算器’。”
这或许代表了一个新方向:在工业领域,AI的价值不在于“模仿人类”,而在于“超越人类”——在计算速度、精度和稳定性上,机器应该永远比人更强,当GPT们卸下“通用人工智能”的包袱,专注于解决具体工业问题时,真正的创新才会发生。
正如波士顿咨询集团在最新报告中所言:“2026年将是工业AI的‘成人礼’——告别盲目崇拜,学会理性使用,这才是技术成熟的标志。”在这场变革中,那些能平衡“创新冲动”与“工程严谨”的企业,终将收获数字化转型的真正红利。