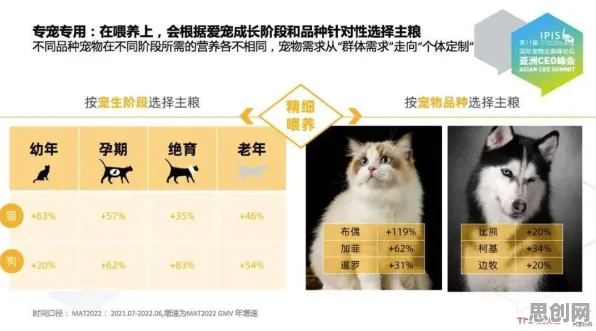
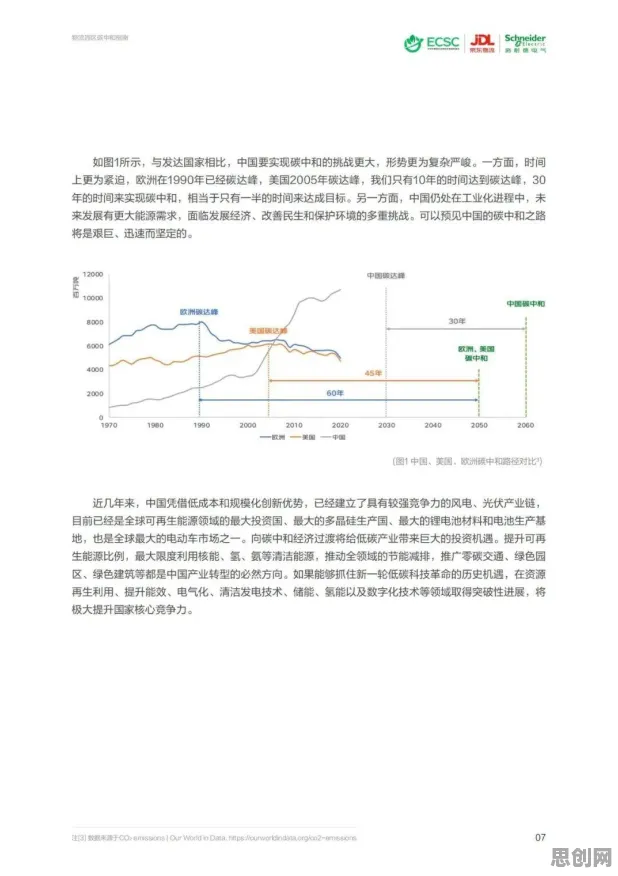
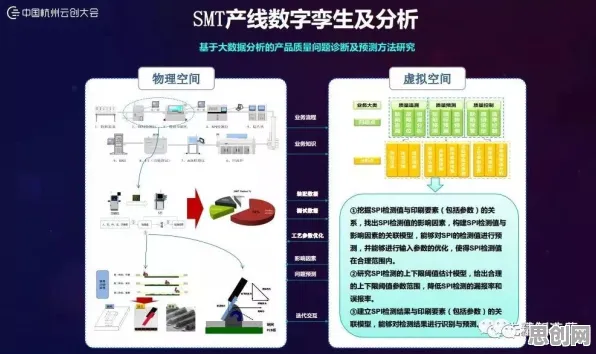
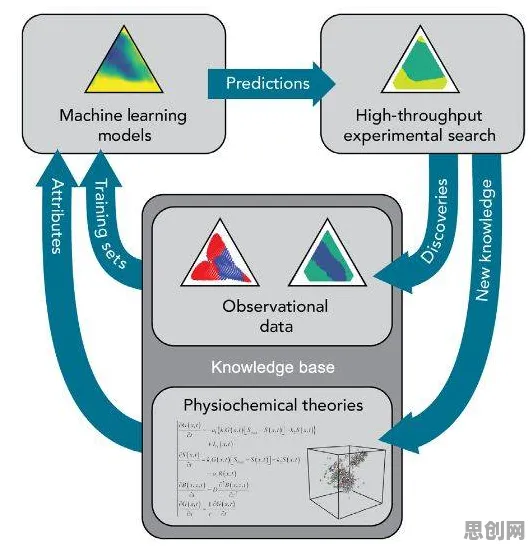
在2026年的科技浪潮中,联邦学习与虚拟现实(VR)技术正以惊人的速度重塑着我们的世界,联邦学习,这一分布式机器学习的“新星”,通过让多个参与方在不共享原始数据的前提下协同训练模型,解决了数据隐私与数据孤岛的难题;而虚拟现实技术,则以沉浸式的体验将人类带入了一个全新的数字维度,当这两者相遇,一个看似不相关的领域——超参数调优,却意外地成为了推动虚拟现实技术进步的关键力量。
联邦学习:分布式智能的崛起
联邦学习,这个由谷歌在2016年首次提出的概念,经过几年的发展,已经在医疗、金融、物联网等多个领域展现出其强大的潜力,它的核心思想在于“数据不动模型动”,即各个参与方(如医院、银行、智能设备)在本地训练模型,仅将模型参数或梯度上传至中央服务器进行聚合,从而在不泄露原始数据的情况下实现全局模型的优化。
可持续发展与低代码开发及隐私保护热度不断攀升,技术创新带来新突破 以医疗领域为例,2026年,全球多家顶尖医院联合开展了一项关于罕见病诊断的联邦学习项目,由于罕见病数据稀缺且分散,单一医院难以积累足够的数据量来训练准确的诊断模型,通过联邦学习,这些医院能够在保护患者隐私的前提下,共享模型参数,共同训练出一个覆盖多种罕见病的诊断模型,这一模型不仅提高了诊断的准确性,还加速了新药的研发进程,为无数患者带来了希望。
联邦学习的成功并非一蹴而就,在模型训练过程中,超参数的选择直接决定了模型的性能与收敛速度,超参数,如学习率、批量大小、正则化系数等,是模型训练前的预设参数,它们不像模型权重那样可以通过训练数据自动调整,而是需要人工或通过自动化方法进行调优。

超参数调优:联邦学习中的“隐形冠军”
在联邦学习中,超参数调优面临着前所未有的挑战,由于数据分布在多个参与方,且各参与方的数据分布、质量、数量均存在差异,传统的超参数调优方法(如网格搜索、随机搜索)往往难以奏效,联邦学习的通信成本高昂,频繁的参数交换会显著增加训练时间与网络负担,这使得超参数调优必须更加高效、精准。 2026年自动驾驶热度持续上升,相关领域迎来新机遇
2026年,一项由斯坦福大学与多家科技公司联合开展的研究,为联邦学习中的超参数调优提供了新的思路,该研究提出了一种基于贝叶斯优化的自适应超参数调优框架,该框架能够根据各参与方的数据特征与模型性能,动态调整超参数搜索空间与采样策略,从而在有限的通信轮次内找到最优的超参数组合。
以一家全球领先的智能汽车制造商为例,该公司在开发自动驾驶系统时,采用了联邦学习来训练车辆感知模型,由于不同地区的道路环境、交通规则、天气条件差异巨大,单一地区的训练数据难以覆盖所有场景,通过联邦学习,该公司能够联合全球多个测试基地的数据进行模型训练,初始阶段,由于超参数选择不当,模型在不同地区的性能差异显著,部分地区的识别准确率甚至低于80%。
引入自适应超参数调优框架后,情况发生了显著变化,该框架首先对各参与方的数据进行初步分析,识别出数据分布的关键特征;根据这些特征动态调整超参数搜索空间,优先搜索对模型性能影响最大的参数;通过贝叶斯优化算法,在有限的通信轮次内找到了最优的超参数组合,经过调优后,模型在全球各地区的识别准确率均提升至95%以上,显著提高了自动驾驶系统的安全性与可靠性。

虚拟现实:沉浸式体验的革命
当联邦学习中的超参数调优技术逐渐成熟,其影响力开始跨越领域,渗透到虚拟现实技术中,虚拟现实技术,通过头戴式显示器、手柄等交互设备,为用户提供了一个沉浸式的数字世界,要实现真正的沉浸感,不仅需要高分辨率的显示技术、低延迟的追踪技术,还需要一个能够实时响应用户行为、提供个性化体验的智能系统。
2026年,一款名为“VR Dream”的虚拟现实游戏风靡全球,这款游戏以其逼真的场景、丰富的剧情与高度的互动性,吸引了数百万玩家,在游戏的开发初期,开发者面临着一个巨大的挑战:如何根据玩家的行为习惯、偏好与技能水平,动态调整游戏难度与剧情走向,以提供个性化的游戏体验?
传统的游戏开发方法往往依赖于预设的规则与脚本,难以实现真正的个性化,而“VR Dream”的开发团队则采用了联邦学习与超参数调优技术,构建了一个智能的游戏推荐系统,该系统首先通过联邦学习,联合全球玩家的游戏数据(如操作习惯、任务完成时间、选择偏好等)进行模型训练,以捕捉玩家的行为模式与偏好特征;利用超参数调优技术,优化模型的推荐算法,使其能够根据玩家的实时行为,动态调整游戏难度与剧情走向。
以一位新手玩家为例,在初次进入游戏时,系统会根据其操作习惯与偏好,为其推荐一条相对简单的剧情线,并降低敌人的难度,随着玩家技能的提升与经验的积累,系统会逐渐增加游戏难度,引入更复杂的剧情与挑战,系统还会根据玩家的选择,动态调整剧情走向,为玩家提供独一无二的游戏体验。 绿色工作圈与低碳办公热度持续上升,相关产业迎来新机遇

这一智能推荐系统的应用,不仅显著提高了玩家的满意度与留存率,还为游戏开发者提供了宝贵的用户行为数据,通过分析这些数据,开发者能够深入了解玩家的需求与偏好,为后续的游戏更新与优化提供有力支持。 2026年聚焦社会企业与绿色园区新趋势,应用场景不断拓展
跨领域的融合:超参数调优的无限可能
联邦学习中的超参数调优技术,不仅推动了虚拟现实技术的进步,还在更多领域展现出其巨大的潜力,在智能制造领域,通过联邦学习联合多家工厂的生产数据,利用超参数调优技术优化生产流程与质量控制模型,能够显著提高生产效率与产品质量;在智慧城市领域,通过联邦学习联合多个部门的数据(如交通、环境、能源等),利用超参数调优技术优化城市管理与服务模型,能够实现城市的可持续发展与居民生活质量的提升。
以一家全球领先的电子产品制造商为例,该公司在全球拥有多家工厂,生产同一款产品,由于各工厂的生产设备、工艺流程与员工技能水平存在差异,产品的质量与生产效率也各不相同,为了解决这一问题,该公司采用了联邦学习与超参数调优技术,构建了一个智能的生产优化系统。
该系统首先通过联邦学习,联合各工厂的生产数据(如设备状态、工艺参数、产品质量等)进行模型训练,以捕捉生产过程中的关键因素与影响规律;利用超参数调优技术,优化生产流程与质量控制模型,使其能够根据各工厂的实际情况,提供个性化的优化建议,经过一段时间的运行,该系统显著提高了各工厂的生产效率与产品质量,降低了生产成本与废品率,为公司的全球竞争力提供了有力支撑。
科技融合的未来已来
在2026年的科技浪潮中,联邦学习中的超参数调优技术正以其独特的魅力,推动着虚拟现实、智能制造、智慧城市等多个领域的进步,它不仅解决了数据隐私与数据孤岛的难题,还通过高效的超参数调优,实现了模型的个性化与智能化,随着技术的不断发展与应用的不断拓展,我们有理由相信,科技融合的未来已经到来,而超参数调优技术,将成为这一未来中不可或缺的“隐形冠军”。