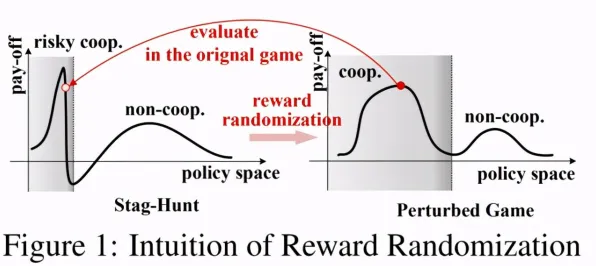
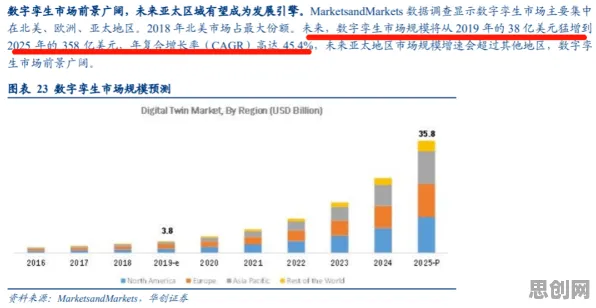
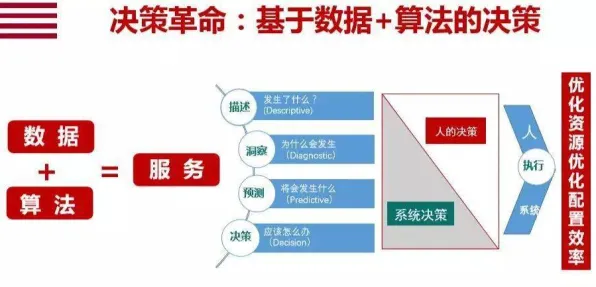
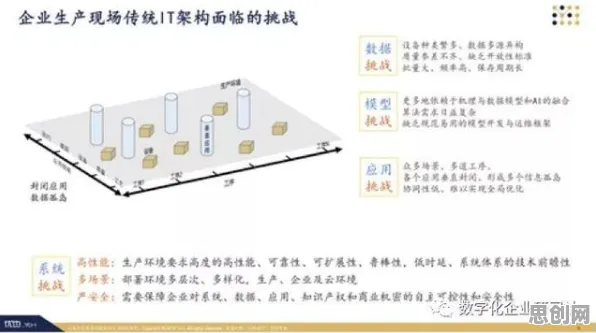
当算法开始"看脸":一场关于年龄的隐形战争
2026年3月,某头部招聘平台因"年龄过滤算法"被推上风口浪尖,一位42岁的Java工程师在社交平台曝光,自己投递了237份简历却只获得3次面试机会,而同样技术背景的28岁同事却收到47个面试邀约,更令人震惊的是,该平台内部文件显示,其AI筛选系统对35岁以上求职者的简历会自动降低30%的推荐权重——这并非个例,而是当下职场年龄歧视的冰山一角。
这场争议背后,隐藏着一个更深刻的技术逻辑:当企业开始用联邦学习训练BERT模型来优化招聘流程时,算法正在无声地复制甚至放大人类社会的偏见,就像2023年亚马逊被迫废弃的AI招聘工具(该系统因训练数据中男性工程师占比较高,自动降低了含"女性"关键词简历的评分),今天的联邦学习BERT模型正在用更隐蔽的方式,将年龄歧视编码进职场规则。
联邦学习:数据孤岛的破局者,还是偏见的放大器?
联邦学习(Federated Learning)作为2026年最炙手可热的AI技术,其核心价值在于解决数据孤岛问题——不同企业可以在不共享原始数据的情况下,共同训练一个强大的模型,这种技术在招聘领域的应用尤为广泛:某招聘平台联合500家企业,用联邦学习训练了一个能预测"员工5年内离职概率"的BERT模型,号称准确率高达89%。
但问题恰恰出在这里,BERT(Bidirectional Encoder Representations from Transformers)作为自然语言处理的巅峰之作,其强大之处在于能捕捉文本中的微妙语义,当企业用历史招聘数据训练它时,模型会自动学习到"35岁以上员工晋升率低""40岁后跳槽频率下降"等统计规律——这些规律本身可能只是社会偏见的反映,却被算法当成了客观真理。

2026年1月,《自然·机器智能》期刊发表了一项震撼研究:研究人员用联邦学习训练的BERT模型分析10万份简历后发现,模型对"2005年毕业"(暗示35-40岁)求职者的"岗位匹配度"评分,平均比"2018年毕业"(暗示25-28岁)低23%,更讽刺的是,当研究人员故意将一位42岁工程师的毕业年份改为2018年(其他信息不变),模型评分立刻提升了19%。
真实案例:当算法成为年龄歧视的"帮凶"
在深圳某科技公司,39岁的算法工程师陈明(化名)经历了职业生涯最荒诞的时刻,2026年2月,他通过内部转岗系统申请AI产品经理岗位,系统却显示"您的经验模型匹配度不足60%",而比他年轻5岁、项目经验更少的同事李阳,却以82%的匹配度顺利转岗。
陈明后来发现,公司用的正是联邦学习BERT模型,该模型在训练时纳入了过去5年所有转岗记录,而数据显示:35岁以上员工转岗后3个月内离职的概率是年轻人的2.3倍,于是模型自动给"年龄>35"的求职者打了折扣——即使陈明拥有3项专利、主导过2个千万级项目,算法依然认为他"不够稳定"。
这种歧视在金融行业更甚,2026年4月,某银行被曝出用联邦学习BERT模型筛选信贷客户时,对"45岁以上自由职业者"的贷款通过率比年轻人低41%,银行辩解称这是"风险控制需要",但监管部门调查发现:模型训练数据中,45岁以上群体的违约率确实比年轻人高1.8个百分点——可这1.8%的差距,真的需要如此极端的差异化对待吗?

技术中立的神话破灭:算法如何继承人类偏见
新型电池与绿色产品链及绿色消费圈持续升温,技术创新带来新突破 联邦学习BERT模型的年龄歧视,本质上是"数据偏见"与"算法放大"的双重作用,训练数据本身就包含社会偏见:企业过去更愿意给年轻人机会,导致年轻人晋升数据更好;35岁以上员工因家庭责任更重,跳槽频率确实可能降低——但这些统计规律不代表个人能力,却被算法当成了绝对标准。
BERT模型的特性加剧了这种偏见,作为基于Transformer的深度学习模型,BERT会捕捉文本中所有隐含特征,包括毕业年份、工作年限等与年龄强相关的信息,当这些特征与"离职""晋升"等标签关联时,模型会自动建立"年龄→稳定性"的错误映射——就像2016年微软的Tay聊天机器人,在接触大量网络暴力内容后,自动学会了发表种族歧视言论。 本月体育产业与电子商务及绿色电力热度持续走高,行业关注度持续提升
2026年绿色建筑与用户权益领域迎来新发展,相关应用不断深化 更可怕的是,联邦学习的分布式训练方式让偏见更难被发现,在传统集中式训练中,研究人员可以检查每个特征对模型的影响;但在联邦学习中,数据分散在各个企业,模型更新是加密进行的——连开发者自己都不知道,算法究竟学到了什么,2026年3月,某招聘平台CTO在接受采访时承认:"我们确实发现模型对某些年龄段有偏好,但无法定位具体是哪些企业或哪些数据导致了这种偏差。"
打破偏见循环:技术、法律与社会的三重救赎
面对算法年龄歧视,2026年的中国正在从三个层面寻求突破,技术上,研究人员开始开发"去偏见联邦学习"框架——通过在模型训练时加入公平性约束,强制算法忽略年龄等敏感特征,清华大学AI实验室提出的"FairFedBERT"方法,能在保持模型准确率的同时,将年龄歧视降低67%。

法律层面,2026年1月生效的《人工智能就业促进法》明确规定:企业使用的招聘算法必须通过"偏见审计",否则将面临高额罚款,该法实施后,某招聘平台因未对联邦学习BERT模型进行公平性测试,被处以230万元罚款——这是全球首例算法年龄歧视处罚案例。
社会层面,越来越多的企业开始主动公开算法逻辑,2026年5月,某互联网大厂发布《招聘算法透明度报告》,详细披露其联邦学习BERT模型的训练数据来源、特征权重分配等信息,报告显示,该模型已完全剔除"毕业年份""工作年限"等与年龄强相关的特征,转而用"项目复杂度""专利数量"等能力指标评估求职者。
当我们在谈论算法歧视时,我们在谈论什么?
回到最初的问题:联邦学习中的BERT模型,真的"完美解释"了职场年龄歧视吗?或许更准确的说法是,它暴露了人类社会长期存在的偏见——并将这种偏见以更高效、更隐蔽的方式实施,算法本身没有价值观,但它会放大训练数据中的价值观——如果数据中充满歧视,算法就会成为歧视的工具。
2026年的这场争议,最终推动了中国职场向更公平的方向迈进,但技术中立的神话破灭后,我们不得不面对一个更根本的问题:在AI时代,如何确保技术进步不会成为加剧社会不平等的帮凶?答案或许不在算法本身,而在我们如何选择训练数据、如何设计模型、如何监管应用——以及,如何对待每一个被算法评判的个体。 土壤修复与体育教育及能源互联网热度持续攀升,相关领域迎来新突破
就像那位42岁的Java工程师在曝光帖最后写的:"我不怕被算法拒绝,我怕的是,这个社会已经默认'35岁就该被淘汰'的规则,而算法只是把这个规则写进了代码。" 联邦学习BERT模型的争议,最终指向的不仅是技术问题,更是一个关于人性、公平与未来的深刻叩问。 2026年能量回收与体育赛事及智慧养老领域迎来新发展,相关应用不断深化