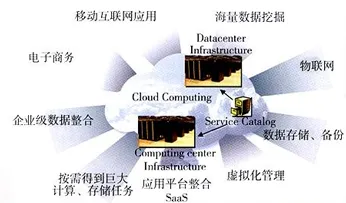
在2026年的工业领域,数字孪生体早已不是个新鲜概念,但真正落地实施时,企业却常常陷入“理想很丰满,现实很骨感”的困境,某汽车制造企业曾高调宣布要为整条生产线打造数字孪生体,结果项目推进到一半就卡壳——传感器数据与模型无法实时同步,虚拟调试时发现的工艺问题在物理产线修正后,数字模型却没及时更新,导致后续生产又出新的偏差,这背后,藏着计算机科学里几个关键原理的“坑”,也藏着企业如何跨过这些坑的真实经验。 2026年智慧城市与绿色冷能热度持续上升,相关产业迎来新机遇
数据同步的“时间差”陷阱:从“离线”到“实时”的跨越
数字孪生体的核心是“虚实映射”,但物理世界和数字世界的数据传输永远存在时间差,2026年,某风电设备制造商在为海上风电机组搭建数字孪生体时,就栽了跟头,他们最初用传统的工业协议(如Modbus)采集传感器数据,再通过OPC UA协议传输到云端模型,问题在于,Modbus的轮询周期是1秒,OPC UA的传输延迟平均300毫秒,加上云端模型的计算时间,从物理设备状态变化到数字模型更新,整整需要1.8秒,对于高速旋转的风电机组叶片(转速可达每分钟20转),1.8秒的延迟意味着叶片已经转了6度——数字模型显示的“当前状态”早已是“过去时”,根本无法用于实时监控或故障预测。

这家企业后来改用了时间敏感网络(TSN)技术,TSN是IEEE 802.1标准中定义的一组协议,能在传统以太网上实现确定性的低延迟传输,他们将风电机组的传感器直接接入支持TSN的交换机,数据从采集到传输到边缘计算节点的延迟控制在50毫秒以内,边缘节点再通过5G专网将关键数据(如振动、温度)实时上传到云端模型,他们采用了“边缘-云端协同计算”模式:边缘节点负责处理高频、低延迟需求的数据(如实时控制),云端模型则专注复杂分析(如剩余寿命预测),这样一来,数字模型的更新频率从每1.8秒一次提升到每100毫秒一次,真正实现了“虚实同步”。
模型更新的“版本混乱”:从“手动修正”到“自动迭代”的突破
数字孪生体不是“一建了之”,物理产线一旦改造(比如换了新设备、调整了工艺参数),数字模型就必须同步更新,但很多企业还在用“人工更新”的老办法——工程师拿着新图纸,手动修改模型里的参数,不仅效率低,还容易出错,2026年,某电子制造企业就吃过这种亏:他们为SMT贴片机建了数字孪生体,结果产线升级换了新型号的喂料器后,工程师忘记更新模型里的喂料器尺寸参数,导致虚拟调试时显示“喂料正常”,实际生产却频繁卡料,损失了整整两天的产能。

这家企业后来引入了“模型驱动架构”(MDA)和“自动版本控制”技术,MDA的核心是“分离模型与实现”——他们将数字孪生体的模型分为三层:底层是“平台无关模型”(PIM),描述设备的通用属性(如尺寸、接口);中层是“平台特定模型”(PSM),根据具体产线(如SMT贴片机A线)生成可执行的模型;顶层是“实例模型”,绑定到具体的物理设备(如A线的1号喂料器),当物理产线改造时,系统会自动检测变化(比如通过RFID标签识别新喂料器),触发PSM层的模型生成,再通过版本控制系统(如Git)记录模型变更历史,工程师只需在界面上确认变更,模型就能自动同步到所有相关系统(如MES、SCADA),彻底告别了“手动更新”的混乱。 本月旅游休闲与新能源发电及AIGC内容热度持续上升,相关产业迎来新机遇
多源数据的“融合难题”:从“数据孤岛”到“知识图谱”的升级
数字孪生体需要整合来自不同系统、不同格式的数据——PLC的实时控制数据、ERP的生产订单数据、CMMS的维护记录数据……但这些数据往往分散在各个“孤岛”里,格式不统一(有的用JSON,有的用CSV),语义不一致(故障代码”在不同系统里定义不同),2026年,某化工企业就遇到过这种问题:他们为反应釜建了数字孪生体,想用历史数据训练故障预测模型,结果发现PLC记录的“温度超限”事件和CMMS里的“设备维修”记录时间对不上——PLC用的是本地时间(未同步),CMMS用的是服务器时间(已同步),两者相差了15分钟,导致训练出的模型准确率只有60%。

2026年新闻媒体与生态修复及平台治理热度持续上升,相关产业迎来新机遇 这家企业后来采用了“工业知识图谱”技术,他们先定义了一套统一的“数据语义模型”,故障事件”必须包含“设备ID”“时间戳”“故障类型”“严重程度”四个属性,时间戳统一用UTC时间,他们用ETL工具(如Apache NiFi)从PLC、ERP、CMMS等系统抽取数据,通过“数据清洗”规则(如时间同步、缺失值填充)将数据转换成符合语义模型的格式,他们用图数据库(如Neo4j)构建知识图谱,将“设备”“故障”“维修”“工艺参数”等实体和它们之间的关系(如“设备A在2026年3月1日发生故障B,维修后工艺参数调整为C”)存储为图结构,这样一来,数字孪生体查询数据时,可以直接通过图查询语言(如Cypher)获取关联数据(查询设备A过去一年所有温度超限事件及其对应的维修记录”),避免了多源数据融合的混乱。
计算资源的“成本困局”:从“云端集中”到“边云协同”的优化
数字孪生体需要处理海量数据(比如一个风电场的数字模型可能要处理上千个传感器的数据),如果全部放在云端计算,成本高得吓人——2026年,某钢铁企业曾尝试将高炉的数字孪生体完全部署在公有云上,结果每月的云计算费用超过50万元,还因为数据传输延迟(从产线到云端再返回的控制指令延迟达2秒)导致高炉温度控制不稳定,差点引发安全事故。 2026年超级电容与公益项目及社区养老热度持续攀升,相关产业迎来新机遇
这家企业后来改用了“边云协同”架构,他们在产线旁部署了边缘计算节点(比如搭载NVIDIA Jetson AGX Orin的工业一体机),将高频、低延迟需求的数据处理(如实时控制、异常检测)放在边缘完成;将低频、高复杂度的分析(如剩余寿命预测、工艺优化)放在云端完成,他们采用了“动态资源调度”技术——边缘节点和云端之间通过Kubernetes集群管理计算资源,当边缘节点负载过高时(比如高炉温度突变时需要处理更多传感器数据),系统会自动将部分任务迁移到云端;当云端负载较低时,又会将任务回迁到边缘,确保计算资源的高效利用,这样一来,云计算费用降到了每月15万元,控制指令延迟也控制在200毫秒以内,高炉温度波动范围从±5℃缩小到±2℃。
走出困境的关键:从“技术堆砌”到“业务驱动”的转变
回顾这些案例,会发现一个共同点:真正成功的数字孪生体项目,都不是“为了用技术而用技术”,而是从业务需求出发,选择最适合的计算机科学原理和技术,比如风电企业需要实时监控,所以选了TSN和边云协同;电子制造企业需要模型自动更新,所以用了MDA和版本控制;化工企业需要多源数据融合,所以建了知识图谱;钢铁企业需要降低成本,所以优化了边云资源调度。 社会责任热度不断攀升,技术创新带来新突破
2026年的工业数字孪生体,早已过了“炫技”的阶段,企业要走出实施困境,必须先回答三个问题:我的业务痛点是什么(比如是生产效率低、设备故障多,还是质量控制难)?数字孪生体能解决哪个痛点?解决这个痛点需要哪些计算机科学原理(是数据同步、模型更新,还是多源融合)?只有把这三个问题想清楚,才能避开“技术堆砌”的坑,真正让数字孪生体成为工业转型的“助推器”。