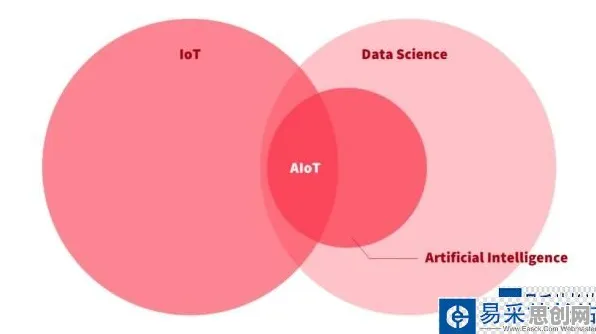
环境建模:从“物理世界”到“数字镜像”的精准映射
工业数字孪生的第一步是构建一个与物理系统高度一致的数字环境,而强化学习的“环境建模”原理正是这一过程的核心,环境建模不是简单的3D建模或数据采集,而是需要定义智能体(如机器人、生产线控制器)可感知的状态空间、可执行的动作集合,以及状态转移的概率分布。 本月绿色生态城热度持续攀升,相关应用不断深化
案例:某汽车工厂的焊接机器人数字孪生
2026年,某头部汽车制造商在升级焊接生产线时,遇到了传统仿真工具无法解决的难题:焊接过程中金属变形、热应力分布等物理现象难以精确模拟,导致数字模型与实际生产偏差超过15%,项目团队引入强化学习环境建模方法,通过在物理焊接头上安装高精度传感器(采集温度、压力、位移等200+维度数据),结合有限元分析(FEA)构建动态状态空间,智能体(焊接机器人控制器)的动作集合被定义为“焊接速度调整范围±20%”“电流波动范围±10%”等连续变量,而非传统的离散指令,经过3个月的数据采集与模型训练,数字孪生平台的预测误差降至3%以内,直接指导物理产线优化焊接参数,使产品合格率提升8%。
这一案例的关键在于:环境建模必须覆盖物理系统的所有关键变量,且状态转移规则需通过真实数据验证,很多企业失败的原因正是忽略了“环境”的动态性——例如仅用静态CAD模型模拟设备,却未考虑温度变化对材料性能的影响。
奖励函数设计:让智能体“知道该追求什么”
强化学习的核心是“通过奖励驱动行为”,而奖励函数的设计直接决定了数字孪生平台的优化方向,在工业场景中,奖励函数往往需要平衡多个目标(如效率、质量、能耗),且需与业务KPI强关联。
案例:某化工企业的反应釜优化
2026年,某化工集团试图用数字孪生优化反应釜的温控策略,传统方法依赖工程师经验设定温度曲线,但不同批次原料的活性差异导致产品质量波动,项目团队采用强化学习,将奖励函数设计为:
- 正奖励:产品纯度(通过近红外光谱仪实时检测)
- 负奖励:能耗(电表数据)、超温次数(安全阈值触发)
2026年互联网医疗与自然教育热度持续攀升,相关技术取得新突破 智能体(温控系统)通过不断尝试不同的加热/冷却策略(动作空间),在数字孪生环境中模拟运行,最终找到一条“纯度最高且能耗最低”的温度曲线,实际应用后,单釜年节约蒸汽成本超200万元,且产品批次间差异缩小至0.5%以内。
这一案例的启示是:奖励函数必须“可量化、可采集、与业务强相关”,某电子厂曾尝试用数字孪生优化SMT贴片机,但因将奖励函数简单设为“贴片速度”,导致智能体为追求高速而频繁撞针,最终项目失败——奖励函数缺失了“设备故障率”这一关键约束。
探索与利用平衡:避免“局部最优”陷阱
强化学习中的“探索-利用”困境,在工业数字孪生中表现为:智能体可能因过早收敛到次优策略,而错过全局最优解,这在复杂生产系统中尤为常见——例如一条包含20道工序的生产线,局部优化某道工序可能降低整体效率。
案例:某半导体工厂的晶圆调度优化
2026年,某12英寸晶圆厂面临调度难题:传统规则引擎无法处理“设备突发故障+紧急订单插入”的复合场景,导致产线利用率不足75%,项目团队采用基于强化学习的数字孪生平台,关键创新在于引入“ε-贪婪策略”平衡探索与利用:

- 90%时间利用当前最优调度方案(利用)
- 10%时间随机尝试新调度策略(探索)
数字孪生环境模拟了设备故障、订单变更等100+种异常场景,智能体通过3万次模拟训练,最终找到一套“动态优先级调整算法”,实际应用后,产线利用率提升至88%,且在突发故障时恢复时间缩短40%。
这一案例的深层逻辑是:工业系统的复杂性决定了“最优解”可能隐藏在非直观路径中,某家电企业曾用数字孪生优化注塑机参数,但因完全依赖历史数据训练(缺乏探索),导致智能体始终沿用旧参数,最终优化效果为零——探索机制是打破“经验依赖”的关键。 2026年关注西医诊疗与生态补偿及废物利用发展动态,技术创新推动产业升级
策略梯度方法:处理连续动作空间的利器
传统强化学习(如Q-learning)擅长处理离散动作(如“开关”“转向”),但工业场景中大量决策涉及连续变量(如“温度调整0.1℃”“压力增加5bar”),此时策略梯度方法(如PPO、TRPO)更具优势。
案例:某钢铁企业的高炉控温
2026年,某大型钢厂的高炉控温系统面临挑战:传统PID控制无法应对原料成分波动,导致铁水温度波动范围达±15℃,影响后续轧制质量,项目团队采用基于PPO(近端策略优化)的数字孪生平台,将动作空间定义为“风量调整范围±10%”“焦炭投入量±5%”等连续变量,状态空间包括炉内温度、压力、煤气成分等30+维度数据。
通过在数字孪生环境中模拟10万次高炉运行(覆盖不同原料配比),智能体学习到“当铁水温度偏低时,优先增加风量而非焦炭”的非线性策略,实际应用后,铁水温度波动范围缩小至±3℃,轧制断辊率下降60%,年节约成本超5000万元。

这一案例的技术突破在于:策略梯度方法直接优化策略函数(而非值函数),天然适合处理连续动作空间,某食品企业曾尝试用Q-learning优化烘焙炉温度,但因动作空间离散化(如“温度设为180℃/190℃/200℃”),导致控温精度不足,产品口感差异大——连续动作空间是工业精密控制的关键。
多智能体协同:从“单机优化”到“系统级优化”
现代工业系统往往由多个子系统组成(如机器人集群、产线联动),此时单个智能体的优化可能破坏整体协调性,多智能体强化学习(MARL)通过让多个智能体在数字孪生环境中协同训练,实现系统级最优。
案例:某物流中心的AGV调度
2026年,某电商物流中心部署了50台AGV小车,传统调度系统因无法处理“多车路径冲突+订单优先级”的复合问题,导致拣选效率不足120件/人/小时,项目团队采用多智能体强化学习,为每台AGV设计独立智能体,但共享全局奖励函数(订单完成时间+路径冲突惩罚)。
在数字孪生环境中,智能体通过“通信协议”交换位置、任务信息,训练出“协作避障+动态优先级调整”策略,实际应用后,拣选效率提升至180件/人/小时,且AGV碰撞次数归零,更关键的是,当新增10台AGV时,系统无需重新编程,智能体通过自学习快速适应新布局。
这一案例的深层价值在于:多智能体强化学习实现了“可扩展的系统优化”,某汽车总装厂曾尝试用单智能体优化装配线,但因忽略不同工位间的耦合关系,导致优化后瓶颈工序反而更堵——系统级视角是工业数字孪生的终极目标。
强化学习是数字孪生的“灵魂”
2026年的工业数字孪生平台,早已不是“3D模型+数据看板”的简单组合,而是以强化学习为算法底座、通过持续交互实现自主优化的智能系统,从环境建模的精准性,到奖励函数的设计智慧;从探索机制的必要性,到策略梯度的技术突破;再到多智能体的协同进化——这5大原理共同构成了数字孪生从“仿真工具”到“决策大脑”的关键跨越。
某重型机械