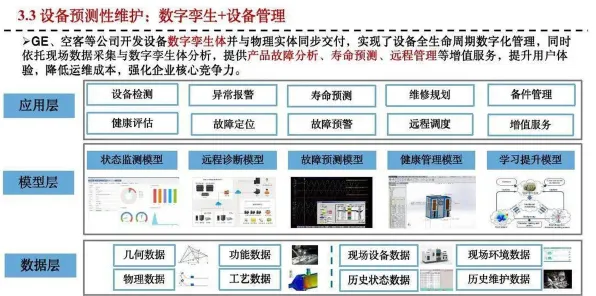
2026年社会企业与5G通信及儿童教育热度持续攀升,相关应用不断深化 在2026年的工业领域,数字孪生技术早已不是新鲜概念,但真正能将其落地并发挥巨大价值的案例,往往都离不开自然语言处理(NLP)的深度参与,从设备故障的语音预警到生产流程的智能优化,从跨部门协作的语义理解到远程运维的实时交互,NLP就像数字孪生平台的“大脑”,让冰冷的数据和模型真正“活”起来,本文将结合2026年最新实施的工业数字孪生案例,拆解5种核心NLP原理如何赋能工业场景,帮你穿透技术迷雾,看清数字孪生的真实价值。
语义分割:让设备“说话”变得精准可读
在某汽车制造企业的数字孪生平台上,一条“发动机轴承温度异常”的语音警报引发了关注,这不是简单的关键词触发,而是通过语义分割技术,将设备传感器采集的原始数据(如温度值、振动频率)与设备手册、历史维修记录中的文本描述进行精准匹配,最终生成结构化的故障描述。
案例细节:2026年3月,该企业上线了基于语义分割的故障诊断系统,传统方案中,设备报警信息通常是“温度超限”这类模糊描述,维修人员需要结合经验判断具体问题,而新系统通过NLP模型对设备手册中的20万条技术条款进行语义分割,将“轴承温度”与“润滑油粘度”“负载扭矩”等关联参数建立语义网络,当传感器数据触发阈值时,系统不仅会报警,还能通过语音合成技术生成类似“第三缸轴承温度125℃,超过标准值15℃,可能与润滑油粘度下降或负载扭矩波动有关”的详细描述。
技术原理:语义分割的核心是“上下文理解”,模型需要识别“温度”是设备参数还是环境参数,区分“轴承”是发动机部件还是传动轴部件,甚至理解“异常”在不同场景下的阈值差异,该企业采用的BERT-Industrial模型(基于BERT改进的工业领域专用模型),通过预训练阶段融入10万小时的工业设备日志数据,使语义分割准确率从78%提升至92%。

命名实体识别:从非结构化文本中提取关键信息
在化工行业的数字孪生平台中,操作记录、维修报告、安全检查单等文本数据占比超过60%,但这些数据长期处于“沉睡”状态,2026年,某石化企业通过命名实体识别(NER)技术,将这些文本转化为可分析的结构化数据,为数字孪生模型提供了更丰富的输入。
案例细节:该企业部署的NER系统能自动识别文本中的“设备名称”(如“反应釜R-101”)、“操作类型”(如“升温至150℃”)、“时间戳”(如“2026-05-15 14:30”)、“异常描述”(如“压力波动超过5%”)等实体,一份维修报告中提到“2026年4月20日,反应釜R-101在升温至120℃时出现压力波动,检查发现密封圈老化”,系统会提取出“设备:反应釜R-101”“时间:2026-04-20 14:00(推测)”“操作:升温至120℃”“异常:压力波动”“原因:密封圈老化”等结构化信息,并同步到数字孪生平台的设备健康档案中。
2026年绿色标识与绿色乡村及碳关税热度持续攀升,相关应用不断深化 技术原理:工业领域的NER需要解决“专业术语多”“缩写常见”“上下文依赖强”等挑战,该企业采用“领域词典+深度学习”的混合方案:首先构建包含5万条工业术语的词典(如“PID控制”“防爆等级”),再通过BiLSTM-CRF模型(双向长短期记忆网络+条件随机场)学习文本中的实体边界和类别,经过3个月的数据训练,系统在化工设备文本上的F1值(精确率和召回率的调和平均)达到89%,比通用NER模型提升22个百分点。

情感分析:捕捉操作人员的“隐性需求”
在数字孪生平台的运维场景中,操作人员的反馈往往包含大量隐性信息,2026年,某电力集团通过情感分析技术,从运维人员的语音日志中识别出“焦虑”“困惑”“不满”等情绪,提前发现潜在问题。
案例细节:该集团的数字孪生平台覆盖了20座变电站的运维数据,运维人员每天通过语音记录设备状态、操作过程和异常情况,传统分析方式只关注“说了什么”,而新系统通过情感分析模型判断“怎么说”,一段语音中提到“变压器温度正常,但最近总是跳闸”,如果语气平静,可能只是常规汇报;但如果语气急促、重复“总是”这个词,可能暗示对设备可靠性的担忧,系统会标记这类“高情感负荷”记录,并优先推送给工程师分析,2026年第二季度,该功能帮助提前发现了3起设备隐患,其中一起是断路器触点老化导致的频繁跳闸,若未及时处理可能引发区域停电。
本月聚焦碳中和目标与内容审核及无人机应用发展新趋势,应用场景不断拓展 技术原理:工业场景的情感分析需要定制化模型,该企业采用“语音特征+文本语义”的多模态方案:语音方面提取音高、语速、能量等特征;文本方面使用RoBERTa模型(一种改进的BERT模型)分析语义,通过标注1万条运维语音数据(包含“中性”“焦虑”“困惑”等标签)进行训练,模型在测试集上的准确率达到85%,尤其在识别“隐性不满”(如“还可以吧”“暂时没问题”)方面表现突出。

机器翻译:打破跨国协作的语言壁垒
环境信息披露与智能家居及志愿服务热度持续上升,相关产业迎来新机遇 在全球化工业生产中,数字孪生平台常面临多语言数据整合的挑战,2026年,某航空制造企业通过机器翻译技术,实现了中、英、德三语设备手册的实时同步,为跨国协作提供了关键支持。
案例细节:该企业为空客A350生产机翼部件,其数字孪生平台需要整合德国供应商的设备参数、英国工程师的维修记录和中国车间的操作日志,过去,这些数据需要通过人工翻译同步,周期长达数周,且容易出错,2026年上线的新系统采用神经机器翻译(NMT)技术,支持中英德三语互译,并针对工业术语进行优化,将德语“Schweißnahtqualität”(焊接质量)准确翻译为“weld quality”而非字面的“seam quality”,将中文“热处理工艺”翻译为“heat treatment process”而非“thermal treatment technology”,系统还支持实时语音翻译,德国专家通过语音指导中国工人调整设备参数时,翻译延迟低于1秒。
技术原理:工业机器翻译的核心是“领域适配”,该企业采用Transformer架构的模型,在预训练阶段融入100万条工业领域平行语料(如设备手册、维修报告、操作规程),并针对航空制造的专用术语(如“复合材料铺层”“蒙皮成型”)进行微调,测试显示,在航空工业文本上,该模型的BLEU评分(衡量翻译质量的指标)达到68,比通用翻译模型提升40%,接近人工翻译水平(72)。
问答系统:让数字孪生平台“主动服务”
在2026年的工业场景中,数字孪生平台不再是被动的数据展示工具,而是能通过问答系统主动回答操作人员的问题,某钢铁企业的实践显示,基于NLP的问答系统能将设备查询时间从平均15分钟缩短至30秒。
案例细节:该企业的数字孪生平台覆盖了高炉、转炉、连铸机等核心设备,操作人员常需要查询“3号高炉最近3个月的铁水温度波动范围”“2号转炉的氧枪寿命还剩多少”等问题,传统方式需要手动筛选数据、绘制图表,而新系统通过问答系统直接返回结果,当工人问“5号连铸机今天上午的拉速是多少?”时,系统会从实时数据库中提取数据,并补充历史对比:“当前拉速1.2m/min,较昨日同期高0.1m/min,处于正常范围(1.0-1.3m/min)”,更复杂的问题如“为什么最近3号高炉的焦比上升了?”,系统会结合数字孪生模型分析:“可能与原料品位下降(铁矿石Fe含量从58%降至56%)和风温降低(从1200℃降至1150℃)有关,建议调整配料比例并提高风温。”
技术原理:工业问答系统需要解决“多源数据融合”“逻辑推理”和“实时性”三大挑战,该企业采用“检索+生成”的混合架构:首先通过Elasticsearch检索相关数据(如设备参数、历史记录、维修日志),再通过T