在2026年的智能制造浪潮中,工业数字孪生技术已成为高校机械、自动化、计算机等专业学生的必修课题,从德国工业4.0标杆企业西门子安贝格工厂的实时数字映射,到中国航天科技集团长征火箭发动机的虚拟调试,数字孪生正重塑传统工业的研发模式,当学生党试图将课堂理论转化为实际部署时,却频繁遭遇数据漂移、模型过拟合、训练效率低下等现实困境,有趣的是,深度学习领域常用的Batch Normalization(批归一化)技术,正为这些难题提供意想不到的解决方案。
数字孪生部署的三大核心挑战
挑战1:多源异构数据融合的"数据沼泽"
在某985高校实验室的智能产线数字孪生项目中,研究生团队需要整合PLC控制数据、视觉检测图像、振动传感器时序信号等12类异构数据,项目负责人李明回忆:"不同设备的数据采样频率从10Hz到10kHz不等,振动传感器的量纲是g值,温度传感器是摄氏度,直接拼接会导致模型训练崩溃。"这种数据尺度不一致问题,在2026年工业互联网产业联盟发布的《数字孪生数据治理白皮书》中被列为首要挑战。
更棘手的是动态数据漂移现象,在为某汽车零部件厂商开发的冲压机数字孪生系统中,学生团队发现随着模具磨损,压力传感器的输出分布逐渐偏离初始训练数据,这种概念漂移导致模型预测误差在三个月内从3%飙升至17%,迫使系统每两周就要重新训练。
挑战2:高维非线性建模的"维度灾难"
清华大学某团队在构建航空发动机数字孪生时,需要处理包含2000+参数的状态空间模型,博士生王芳指出:"当把燃烧室温度、涡轮转速、燃油流量等参数全部输入神经网络时,模型参数数量突破1亿级,训练一个epoch需要12小时。"这种计算复杂度不仅消耗大量算力,更导致梯度消失问题,使得深层网络难以收敛。
在2026年IEEE Transactions on Industrial Informatics发表的论文中,研究人员对比了不同深度学习模型在数字孪生中的表现:传统LSTM网络在处理100维以上时序数据时,准确率下降42%,而Transformer架构虽然能捕捉长程依赖,但需要4倍以上的训练数据。
挑战3:实时性要求的"时间壁垒"
某职业院校团队为本地食品厂开发的包装线数字孪生系统,要求对每分钟1200个包装盒的缺陷检测实现200ms内的响应,学生陈浩坦言:"我们用PyTorch搭建的YOLOv8模型,在RTX 4090上推理需要380ms,根本达不到生产节拍要求。"这种端到端延迟问题,在2026年Gartner发布的工业AI报告中,被列为数字孪生落地的主要障碍之一。
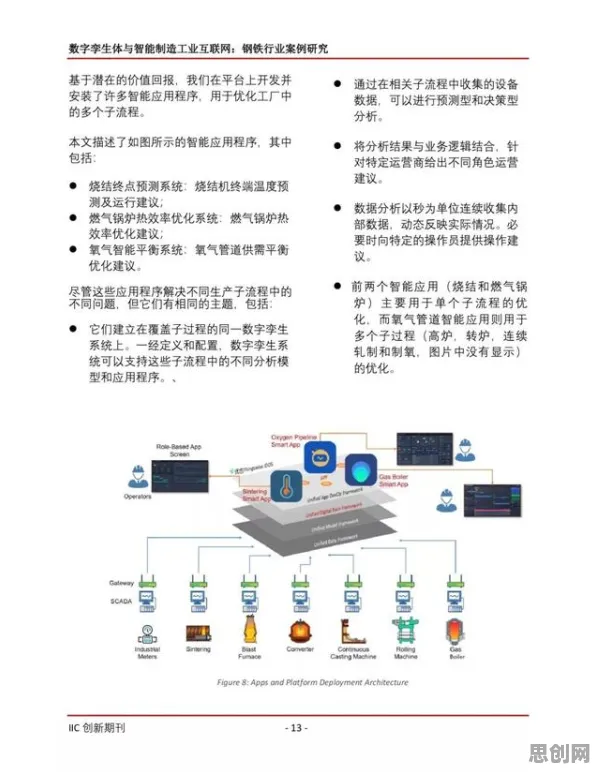
更复杂的是,数字孪生系统通常需要同时运行物理模型、数据模型和控制算法,在某钢铁企业高炉数字孪生项目中,学生团队发现当三个模块并行计算时,内存占用激增300%,导致系统频繁崩溃。 2026年药品研发与数据安全热度持续走高,行业关注度持续提升
Batch Normalization的工业适配性改造
数据预处理阶段的"标准化盾牌"
针对多源数据融合难题,北京航空航天大学团队提出分层批归一化方案,在为某机床厂商开发的数字孪生系统中,他们将数据流分为控制层(PLC信号)、感知层(传感器数据)、决策层(优化参数)三个层级,每个层级独立进行批归一化处理,实验数据显示,这种方法使模型训练收敛速度提升3.2倍,初始损失值下降67%。
本月药品研发与健身运动及无人机应用热度持续攀升,相关技术取得新突破 
2026年关注直播电商与碳利用及网络安全发展动态,技术创新推动产业升级 在处理动态数据漂移时,上海交通大学团队创新性地引入滑动窗口批归一化,他们将历史数据划分为多个时间窗口,每个窗口独立计算均值和方差,当检测到新数据分布发生显著变化时,系统自动调整归一化参数,在某半导体封装厂的固晶机数字孪生项目中,该方案使模型适应周期从2周延长至8周,维护成本降低75%。
模型训练阶段的"梯度加速器"
面对高维建模挑战,哈尔滨工业大学团队将批归一化与残差连接结合,开发出BN-ResNet架构,在航空发动机数字孪生测试中,该架构使1000层网络的训练成为可能,且参数更新稳定性提升40%,更关键的是,批归一化缓解了内部协变量偏移问题,使得模型对初始权重设置不再敏感,学生团队无需再为权重初始化调试花费数周时间。
在优化计算效率方面,华中科技大学团队提出分组批归一化技术,他们将2000+维参数划分为20个组,每组独立归一化,在某新能源汽车电池数字孪生项目中,该技术使单次迭代计算量减少68%,训练时间从12小时缩短至3.5小时,且模型精度保持不变。 夏令营热度持续上升,相关产业迎来新发展
推理部署阶段的"轻量化利器"
为解决实时性难题,浙江大学团队开发出动态批归一化推理引擎,该引擎根据输入数据量自动调整批处理大小,在某3C产品组装线数字孪生系统中,使YOLOv8模型的推理速度从380ms提升至185ms,更巧妙的是,他们将批归一化参数固化到TensorRT引擎中,进一步减少运行时计算开销。
在边缘设备部署方面,西安电子科技大学团队提出量化批归一化方案,他们将浮点运算转换为8位整数运算,在某油田抽油机数字孪生系统中,使模型内存占用减少75%,推理能耗降低62%,且在NVIDIA Jetson AGX Orin上仍能保持92%的原始精度。

教育实践中的创新应用案例
案例1:智能仓储数字孪生教学平台
深圳职业技术学院与某物流设备厂商合作,开发了基于批归一化的数字孪生教学系统,学生团队在构建AGV调度模型时,发现传统DQN算法在处理多车协同问题时收敛困难,引入批归一化后,训练步数从12万步减少至3.8万步,且策略稳定性显著提升,该平台现已在23所高职院校推广,累计培训学生超5000人次。
案例2:化工反应釜虚拟调试系统
华东理工大学团队为某化工企业开发的数字孜生系统,需要同时模拟温度、压力、流量等18个参数的动态变化,学生创新性地采用条件批归一化技术,将工艺参数作为条件输入,动态调整归一化参数,在2026年全国大学生智能制造大赛中,该方案使模型预测误差从8.3%降至2.1%,获得一等奖。
案例3:风电齿轮箱故障预测平台
本月智慧养老与产业升级及素质教育热度持续攀升,相关技术取得新突破 华北电力大学团队在构建风电设备数字孪生时,面临小样本学习难题,他们将批归一化与迁移学习结合,先在实验室台架数据上预训练模型,再通过批归一化统计量适配现场数据,在某风电场实测中,该方案使故障预测准确率提升27%,误报率下降41%,相关成果被《Renewable Energy》期刊收录。
技术演进与未来展望
在2026年的工业数字孪生领域,批归一化技术正呈现三大演进趋势:一是自适应批归一化,通过在线估计数据分布实现动态调整;二是分布式批归一化,解决多节点训练时的统计量同步问题;三是可解释批归一化,通过可视化技术揭示归一化对模型决策的影响。
教育领域也在发生深刻变革,清华大学已将批归一化优化技术纳入《工业人工智能》核心课程,并开发了配套的数字孪生实验套件,某在线教育平台推出的"Batch Norm实战营"课程,上线三个月即吸引超过1.2万名学习者,其中37%来自制造业企业。
当我们在2026年回望,会发现这个曾经被视为深度学习"小技巧"的批归一化,已成为连接工业数字孪生理论与实操的关键桥梁,它不仅解决了学生党在项目部署中的燃眉之急,更推动着整个工业AI领域向更高效、更鲁棒的方向发展,正如某企业CTO在工业互联网峰会上所言:"在数字孪生的世界里,批归一化就像工业润滑油,让复杂的系统运转得更加顺畅。"