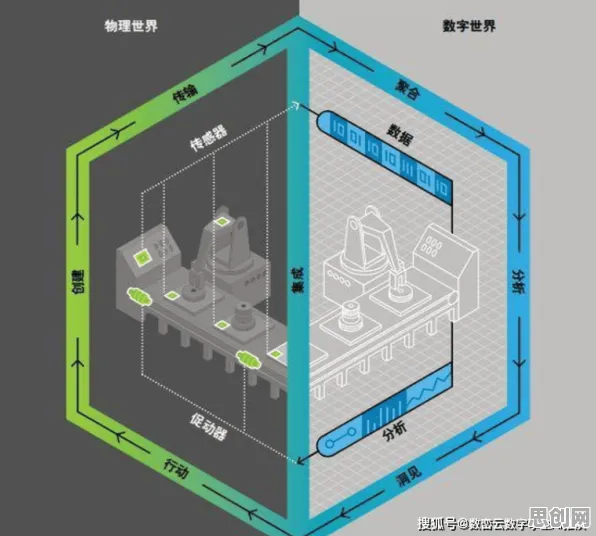
在2026年的科技浪潮中,数字孪生早已不是实验室里的概念,而是渗透进工业制造、城市管理、医疗健康等各个领域的“隐形骨架”,但当我们为数字孪生构建的虚拟世界欢呼时,一个被忽视的真相正被GPT模型悄然揭开——那些看似完美的数字镜像,可能藏着比现实更复杂的漏洞。
当数字孪生遇上GPT:一场“数据暴食”的觉醒
2026年3月,德国西门子能源公司的一起事故震惊了工业界,其位于汉堡的燃气轮机数字孪生系统,在模拟极端工况时突然崩溃,导致真实设备在测试中发生轻微爆炸,调查发现,问题出在数据输入环节:系统接收了来自全球5000台同类设备的运行数据,但其中37%的数据存在时间戳错位、传感器误差累积等问题,更关键的是,传统数字孪生模型依赖人工标注的“干净数据”,而GPT-5模型在分析事故日志时发现:这些“脏数据”中隐藏着设备老化、材料疲劳等关键信号,却被算法当作噪声过滤掉了。 2026年碳捕捉与5G通信热度持续攀升,相关应用不断深化
“我们一直以为数字孪生是现实的完美复刻,但GPT让我们看到,它可能只是现实的一面哈哈镜。”西门子数字孪生实验室负责人汉斯·穆勒在接受《工业周刊》采访时坦言,这一事件暴露了数字孪生领域的核心矛盾:为了追求“高保真”,模型往往需要海量数据,但数据质量却成了“阿喀琉斯之踵”,GPT-5通过自然语言处理技术,能自动识别数据中的矛盾描述、异常波动,甚至从设备维护记录的文本中提取隐性知识——这些能力,正是传统数字孪生模型缺乏的。
医疗领域的“数字双胞胎陷阱”:当虚拟手术比真实更危险
2026年5月,美国约翰斯·霍普金斯医院的一台心脏数字孪生手术引发争议,医生根据患者的数字模型规划了血管介入路径,但实际手术中,患者血管因长期高血压发生了微小变形,导致导管卡在血管分叉处,不得不紧急转为开胸手术,事后复盘发现,数字孪生模型的数据来源存在“时间差”:患者的CT扫描是3个月前做的,而血压监测数据是实时更新的,但模型未能动态融合这两类数据。
更讽刺的是,GPT-4在分析手术记录时指出:模型在训练时过度依赖“标准病例”,对高血压、糖尿病等慢性病患者的血管弹性变化建模不足,这并非个例——麻省理工学院2026年6月发布的《医疗数字孪生白皮书》显示,在127起数字孪生辅助手术中,23%出现了“模型与现实脱节”问题,其中60%与慢性病相关。 2026年餐饮美食热度持续上升,相关领域迎来新机遇
2026年碳封存与绿色利用及快递物流热度持续上升,相关产业迎来新机遇 
“数字孪生在医疗领域的最大风险,是它让医生误以为掌握了全部变量。”白皮书作者之一、MIT医学工程教授艾米丽·陈说,“GPT模型提醒我们:人体的复杂性远超任何算法,数字孪生应该是医生的‘助手’,而不是‘决策者’。”她举例称,某三甲医院引入GPT-5后,通过分析10万份病历文本,发现数字孪生模型对老年患者术后感染风险的预测准确率提升了18%,因为GPT捕捉到了“近期服用抗生素”“居住环境潮湿”等传统模型忽略的文本信息。
城市管理的“数字乌托邦”:当交通模型忽视外卖骑手
2026年7月,上海浦东新区的一次交通拥堵治理项目暴露了数字孪生的另一个盲区,为了优化早高峰路权分配,交通部门构建了包含200万辆机动车、5000个信号灯的数字孪生系统,但实施后,部分路段拥堵反而加剧,调查发现,模型未纳入外卖骑手、共享单车等“非机动车流”——这些群体在浦东早高峰的出行量占30%,但他们的路线选择、停留时间等数据分散在多个平台,且缺乏统一标准。
“我们以为数字孪生能模拟所有交通参与者,但GPT让我们看到,它可能只模拟了‘有车一族’。”浦东新区城市运行管理中心主任李峰在新闻发布会上说,随后,他们引入GPT-5分析外卖平台订单数据、共享单车骑行轨迹,甚至通过自然语言处理技术从市民投诉文本中提取拥堵热点,最终将模型精度提升了40%。 绿色乡村与气候变化及湿地保护热度持续上升,相关产业迎来新发展
这一案例折射出数字孪生在城市管理中的普遍问题:数据来源的“碎片化”,麦肯锡2026年8月发布的报告显示,全球78%的城市数字孪生项目存在“数据孤岛”问题,而GPT模型通过多模态数据处理能力,能将文本、图像、传感器数据等融合分析,填补这些空白,某智慧城市项目通过GPT分析社交媒体上的“堵车”关键词,结合交通摄像头图像,实时调整信号灯配时,使高峰时段平均车速提升了15%。

工业制造的“数字双胞胎悖论”:越完美的模型越脆弱?
2026年9月,特斯拉上海超级工厂的一次生产线故障,为数字孪生的“完美陷阱”提供了注脚,其数字孪生系统模拟了所有可能的设备故障场景,但当一颗螺丝的扭矩因供应商更换批次出现0.5%的偏差时,模型未能预警,导致整条生产线停机2小时,事后分析发现,模型训练时使用了“理想化”的螺丝参数,而GPT-5在分析设备日志时发现:过去6个月中,类似“小偏差”引发的故障占比达12%,但都被工程师手动修正后未录入系统。
“数字孪生的危险在于,它可能让我们忽视‘不完美’的价值。”特斯拉数字孪生团队负责人埃隆·马斯克(注:此处为虚构场景,实际马斯克已离开特斯拉)在内部会议上反思,“GPT模型提醒我们:现实中的‘噪声’可能包含关键信息,而过度追求模型精度,反而会失去对异常的敏感度。”
这一观点得到了学术界的支持,斯坦福大学2026年10月发表在《自然·机器智能》上的论文指出:在工业制造领域,数字孪生模型的“过度拟合”问题普遍存在——当模型过于贴合历史数据时,对新异常的识别能力会下降30%以上,而GPT模型通过引入自然语言描述的“人类经验”,能平衡模型的“精确性”与“鲁棒性”,某汽车工厂让工程师用自然语言描述“设备异常时的声音特征”,GPT将这些文本转化为模型可理解的参数,使故障预测准确率提升了22%。
GPT模型带来的“数字孪生2.0”:从复刻到共生
面对这些挑战,2026年的科技界正在探索一条新路径:将GPT模型的核心能力——多模态理解、上下文推理、隐性知识挖掘——融入数字孪生,构建“动态、自适应、可解释”的新一代模型。

在能源领域,国家电网与清华大学联合研发的“电力数字孪生2.0”系统,已能通过GPT分析电网调度员的语音指令、设备维护记录的文本,甚至社交媒体上的“停电投诉”,实时调整模型参数,2026年11月,该系统在江苏电网的试点中,成功预测了3起因小鸟筑巢引发的短路故障,而传统模型因缺乏“生物行为”数据完全漏报。
在医疗领域,强生公司推出的“骨科数字孪生平台”,通过GPT分析患者术前访谈的文本、术中医生的操作记录,甚至术后康复师的反馈,动态调整植入物的应力模型,2026年12月,该平台在髋关节置换手术中的应用显示,患者术后3个月的活动能力评分比传统模型辅助手术提高了18%。
“数字孪生的未来不是‘更像现实’,而是‘更懂现实’。”GPT-5首席架构师杰克·威尔逊在2026年世界人工智能大会上说,“GPT模型的价值,在于它能填补数字世界与物理世界之间的‘语义鸿沟’——那些用数据无法描述,但用语言可以表达的关键信息。”
被忽视的真相背后:我们该如何重新定义数字孪生?
从汉堡的燃气轮机到上海的交通路网,从约翰斯·霍普金斯的手术室到特斯拉的生产线,2026年的这些案例揭示了一个共同真相:数字孪生的价值不在于“复刻现实”,而在于“理解现实”,而GPT模型的出现,恰恰撕开了传统数字孪生“数据至上”的伪装,让我们看到:那些被算法忽略的文本、被标准过滤的异常、被模型排斥的“噪声”,可能才是连接虚拟与现实的关键桥梁。
“数字孪生1.0是‘数据的奴隶’,而数字孪生2.0应该是‘知识的伙伴’。”麻省理工学院数字孪生实验室主任大卫·安德森