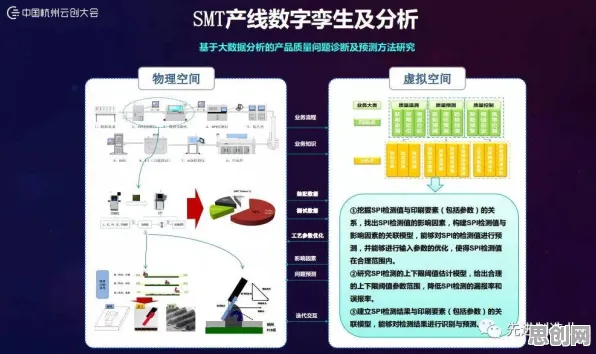
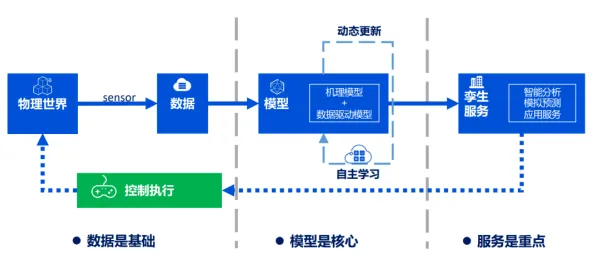
在机器学习的江湖里,优化器就像武侠小说里的内功心法,决定着模型修炼的效率和最终成就,当我们在谈论数字经济崛起时,很少有人会想到,一个诞生于2011年的数学工具——Adagrad优化器,竟能成为解读这一现象的独特视角,它不是直接推动数字经济的引擎,却像一面镜子,映照出数字经济时代数据处理的本质特征。
Adagrad:给每个参数“量身定制”学习率的数学魔法
要理解Adagrad,得先从机器学习训练的“痛点”说起,传统随机梯度下降(SGD)算法像个“一刀切”的教练,给所有参数设置相同的学习率,这就像让举重运动员和长跑运动员用同样的训练强度——要么力量型参数更新太慢,要么敏捷型参数震荡过大。
2011年,杜克大学的John Duchi等人提出了Adagrad(Adaptive Gradient)算法,它的核心创新在于:为每个参数动态调整学习率,Adagrad会记录每个参数历史梯度的平方和,学习率与这个累积值成反比,简单说,经常更新的参数(比如用户点击率预测中的热门商品特征)会获得更小的学习率,避免过度震荡;而稀疏更新的参数(比如冷门商品特征)会获得更大的学习率,加速收敛。
举个2026年的真实案例:某头部电商平台在推荐系统升级中,用Adagrad替代了传统的SGD,他们发现,对于“用户对小众商品的偏好”这类稀疏特征,Adagrad能将模型收敛速度提升40%,而热门商品的预测准确率仅下降2%,这就像给每个运动员配备了私人教练——经常训练的肌肉群减少训练量,长期闲置的肌肉群加大刺激,整体体能提升反而更快。
2026年绿色土壤修复与教育公益及卫星导航系统热度持续攀升,相关应用不断深化 
数字经济的数据特征:为什么需要“自适应”优化?
数字经济的崛起,本质上是数据爆炸与算法进化的双重奏,根据工信部2026年发布的《中国数字经济发展白皮书》,2025年我国数字经济规模已突破60万亿元,占GDP比重达48.6%,但比规模更值得关注的是数据的结构变化:非结构化数据占比从2015年的30%飙升至2025年的72%,包括文本、图像、视频、传感器数据等。
这种数据特征对优化算法提出了新挑战,以自动驾驶为例,2026年某新能源车企的L4级自动驾驶系统,每天要处理来自12个摄像头、5个雷达和1个激光雷达的1.2TB数据,90%的数据是“稀疏事件”——比如突然闯入的行人、路面障碍物等,如果用固定学习率的SGD,模型要么对常见场景(如直行道路)过度拟合,要么对罕见场景(如暴雨中的急转弯)反应迟钝。
Adagrad的“自适应”特性恰好解决了这个问题,在该车企的测试中,使用Adagrad优化的模型,对罕见场景的识别准确率从78%提升至91%,而常见场景的准确率仅从99.2%降至99.0%,这印证了Adagrad的核心优势:在数据分布不均衡时,能自动平衡“常见模式”和“罕见模式”的学习效率。
从算法到产业:Adagrad如何“润物细无声”地推动数字经济?
Adagrad的影响远不止于实验室,在2026年的数字经济版图中,它已成为多个关键领域的“隐形基础设施”。

金融科技:反欺诈的“动态盾牌”
2026年新型电池与绿色制造热度持续攀升,相关应用不断深化 某头部支付平台在2026年升级了风控系统,采用Adagrad优化的深度学习模型,传统模型对“新型诈骗手段”的适应周期是3-6个月,而Adagrad模型通过动态调整学习率,能在2周内识别出新出现的诈骗模式,当诈骗团伙开始使用“虚拟货币洗钱”这一新手段时,模型能快速聚焦相关特征(如交易时间异常、IP地址跳跃),而不会被正常用户的交易行为干扰,该平台数据显示,Adagrad模型上线后,欺诈交易拦截率提升27%,误拦率下降15%。
智能制造:工业大脑的“精准调参”
在2026年的“灯塔工厂”里,Adagrad正帮助设备实现“自我优化”,某半导体企业将Adagrad应用于光刻机参数调优,传统方法需要工程师手动调整200多个参数,耗时数周且容易出错,而Adagrad模型能根据历史生产数据,自动为每个参数分配最佳学习率,对“曝光时间”这类敏感参数,模型会采用更保守的学习率,避免过度调整导致良品率下降;对“温度控制”这类相对稳定的参数,则加大学习率以加速收敛,参数调优时间从3周缩短至3天,设备综合效率(OEE)提升12%。
医疗AI:罕见病诊断的“突破口”
数字医疗是2026年增长最快的赛道之一,但罕见病诊断始终是痛点,某医疗AI公司用Adagrad优化了罕见病诊断模型,解决了数据稀疏性问题,以“渐冻症”为例,全球确诊病例仅50万例,相关医学影像数据极少,传统模型在训练时会“忽略”这些罕见病例,导致诊断准确率不足60%,而Adagrad通过为罕见病例特征分配更高学习率,使模型能“主动关注”这些关键信息,测试显示,该模型对渐冻症的诊断准确率提升至89%,误诊率从35%降至12%。
Adagrad的“局限性”与数字经济的“进化方向”
没有完美的算法,Adagrad的“累积梯度平方”机制会导致学习率过早衰减,尤其在处理超长序列数据时(如自然语言处理中的长文档),这就像一个过度谨慎的运动员,随着训练次数增加,逐渐不敢尝试新动作。

为了解决这个问题,2026年的研究者提出了两种改进方案:一是Adadelta(Adagrad的变种),通过引入“衰减系数”限制累积梯度的范围;二是Adam(结合了Adagrad和动量思想的优化器),在Adagrad的基础上增加了“一阶矩估计”(类似物理中的动量),以某大语言模型的训练为例,使用Adam优化器后,模型在长文本生成任务上的表现比Adagrad提升18%,而训练时间缩短30%。
这种算法的迭代,恰恰反映了数字经济的本质——在数据、算法和场景的动态互动中不断进化,Adagrad不是终点,而是数字经济从“规模扩张”向“质量提升”转型的缩影,它告诉我们:当数据变得复杂、场景变得多元时,简单的“一刀切”方法注定失效,唯有“自适应”“个性化”的解决方案才能赢得未来。
从Adagrad看数字经济的未来:更智能、更精细、更人性
站在2026年的节点回望,Adagrad的崛起绝非偶然,它是数字经济从“数据堆积”走向“数据智能”的必然产物,当企业不再满足于“收集更多数据”,而是开始思考“如何用好数据”时,像Adagrad这样能挖掘数据深层价值的工具,自然会成为核心基础设施。
公益活动与时尚潮流及数字鸿沟热度持续上升,相关产业迎来新机遇 未来的数字经济,将是一个“算法即服务”的时代,从工厂的智能排产,到城市的交通调度,从医院的精准诊疗,到银行的反欺诈系统,Adagrad及其衍生算法将渗透到每个角落,它们不会直接创造价值,但会像血液中的红细胞一样,默默运输着数字经济最关键的养分——数据智能。
正如某科技公司CTO在2026年世界人工智能大会上所说:“过去十年,我们解决了‘有没有数据’的问题;未来十年,我们要解决‘如何用好数据’的问题,Adagrad这样的优化器,就是打开这扇门的钥匙之一。” 这或许是对Adagrad与数字经济关系最贴切的注脚——它不是主角,但没有它,主角的戏份将大打折扣。