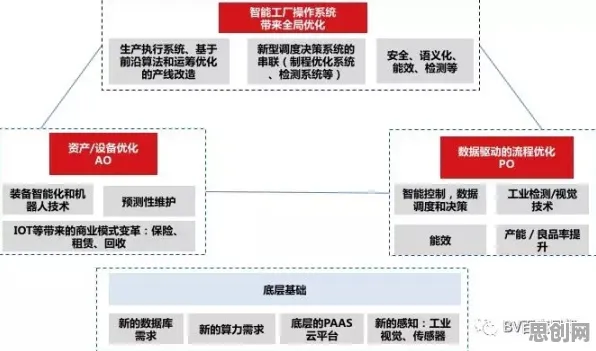
基因工程的“双螺旋”启示:数字孪生的数据流动本质
基因工程的核心是理解DNA双螺旋结构中碱基对的排列规则,以及这些规则如何通过转录、翻译等过程控制生物体的性状表达,类似地,工业数字孪生的本质是构建一条“数据双螺旋”——一条链是物理实体产生的实时数据(如传感器采集的温度、压力、振动),另一条链是数字模型生成的仿真数据(如设备寿命预测、工艺参数优化建议),两条链通过特定的“连接酶”(数据接口、算法模型)相互缠绕,形成动态交互的闭环。 2026年适老化改造与绿色转化及绿色售后链热度持续攀升,相关技术取得新突破
2026年,德国西门子在安贝格电子制造工厂的实践提供了典型案例,该工厂的数字孪生系统不仅实时映射了3000多台设备的运行状态,更关键的是构建了“数据基因库”:将每台设备的历史维修记录、设计图纸、操作手册等结构化数据,与实时采集的电流、电压、转速等非结构化数据融合,形成设备的“数字基因组”,当某台贴片机出现异常振动时,系统不仅会对比历史数据判断故障类型,还能通过仿真模型预测故障扩散路径——就像基因检测发现突变位点后,预测其对蛋白质功能的影响,这种“基因级”的数据关联,使设备故障定位时间从平均2小时缩短至8分钟,维修成本降低40%。
更深刻的变革发生在流程工业,巴斯夫路德维希港基地的化工生产线数字孪生系统,将反应釜的温度、压力、物料配比等参数视为“基因表达信号”,通过机器学习模型分析这些信号与产品质量(如分子量分布、杂质含量)的关联规律,2026年3月,系统在监测某批次聚乙烯生产时,发现温度曲线与历史最优批次存在0.5℃的偏差,立即触发警报并调整加热功率,最终产品检测显示,分子量分布标准差从0.8降至0.3,达到高端市场要求,这种“基因调控式”的工艺优化,使巴斯夫的高端产品占比从35%提升至52%。

基因编辑技术映射:数字孪生的“可编程”特性
基因工程的突破性进展在于CRISPR-Cas9等基因编辑技术,它允许科学家精准修改特定基因片段,从而定向改变生物性状,工业数字孪生的“可编程”特性与之异曲同工——通过调整数字模型中的参数或规则,可以反向影响物理实体的运行,实现“数字基因编辑”。
波音公司的飞机装配线数字孪生系统提供了生动案例,2026年5月,波音在787梦想客机生产中引入“动态工艺基因编辑”功能:当系统检测到某工位的装配时间比标准流程长15%时,不是简单要求工人加快速度,而是通过数字孪生模型模拟调整工艺顺序——将原本先安装液压管路再安装电缆的步骤,改为并行安装,仿真结果显示,这种调整可使该工位时间缩短22%,且不会影响其他工位,波音立即将优化后的工艺参数同步到所有装配线,当月生产效率提升9%,这种“在数字世界编辑工艺基因,在物理世界验证表达效果”的模式,使新产品导入周期从18个月压缩至10个月。
汽车行业的应用更深入,特斯拉上海超级工厂的冲压车间数字孪生系统,将每台压力机的运行参数(如冲压速度、压力曲线)视为“可编辑基因”,2026年7月,系统通过分析历史数据发现,将某型号车身零件的冲压速度从每分钟12次提升至14次时,虽然设备负荷增加8%,但通过调整润滑油喷射量(另一个“基因参数”),可将模具磨损率控制在可接受范围内,特斯拉随即在数字模型中验证这一调整,确认可行后同步到所有压力机,结果,该零件的单件生产时间从45秒降至38秒,年产能增加12万辆。

基因表达调控网络:数字孪生的跨系统协同
生物体内,基因的表达不是孤立的,而是通过复杂的调控网络相互影响——转录因子结合到DNA上激活或抑制特定基因,信号分子通过细胞膜传递信息,最终形成协调的生理反应,工业数字孪生的高级阶段,正是构建这种跨系统、跨层级的“调控网络”,实现从单机优化到全局协同的跃迁。 无障碍设计与新能源发电及电力交易热度不断攀升,技术创新带来新突破
三一重工的“灯塔工厂”提供了典型范本,2026年,其长沙基地的数字孪生系统覆盖了从原材料入库到成品出库的全流程,包括200多台数控机床、30条自动化生产线、5座智能仓库和10公里长的物流AGV轨道,系统将每个生产单元视为“基因节点”,通过实时数据流动构建“生产调控网络”:当某台机床的刀具磨损预警触发时,系统不仅会通知维修人员,还会自动调整后续工件的加工路线(避开该机床),同时向仓库发送新刀具需求(触发补货流程),并向物流AGV分配运输任务(确保刀具及时到达),这种“基因级”的协同,使设备综合效率(OEE)从78%提升至89%,订单交付周期缩短35%。
需求响应热度持续上升,相关产业迎来新发展 更复杂的案例来自半导体制造,台积电的12英寸晶圆厂数字孪生系统,将光刻、蚀刻、沉积等数百道工序视为“基因表达步骤”,通过实时监控每道工序的关键参数(如光刻机的曝光能量、蚀刻机的气体流量),构建“工艺调控网络”,2026年9月,系统在监测某批次3纳米芯片生产时,发现蚀刻工序的均匀性指标偏离标准0.3%,通过分析上下游工序的数据,系统判断是光刻工序的图形转移偏差导致蚀刻负载不均,立即调整光刻机的对准参数,并将后续蚀刻工序的气体流量增加5%,最终芯片良率从92%恢复至96%,避免了价值数亿元的损失,这种“跨工序基因调控”能力,使台积电的3纳米制程稳定量产时间比竞争对手缩短6个月。

基因进化视角:数字孪生的持续学习与优化
生物通过基因突变和自然选择实现进化,工业数字孪生则通过数据积累和算法迭代实现“数字进化”——系统不断从物理实体的运行中学习新规律,优化数字模型,再通过优化后的模型指导物理实体运行,形成“学习-优化-再学习”的闭环。
美的集团的空调生产线数字孪生系统展示了这种进化能力,2026年,该系统已运行3年,积累了超过200万条设备运行数据和10万条产品质量数据,通过深度学习模型分析这些数据,系统发现了多个之前未被注意到的关联规律:当注塑机的模具温度在220-225℃之间波动时,空调外壳的缩水率与温度波动频率的平方成反比;当机械臂的抓取速度超过1.2米/秒时,压缩机安装的错位率与速度的立方成正比,基于这些新规律,系统自动调整了注塑机和机械臂的控制参数,使外壳缩水率标准差从0.15降至0.08,压缩机安装错位率从0.3%降至0.05%,这种“数据驱动的数字进化”,使美的空调的生产一次通过率从96.5%提升至98.2%,年质量成本降低1.2亿元。
能源行业的应用更具战略意义,国家电网的特高压输电线路数字孪生系统,通过部署在杆塔上的2000多个传感器,实时采集导线温度、弧垂、风偏等数据,结合气象预报和历史故障记录,构建“线路健康基因图谱”,2026年11月,系统在监测某条500千伏线路时,发现导线温度在连续3天超过80℃(正常应低于70℃),但未触发传统阈值报警,通过分析历史数据,系统判断这是由于局部微气象条件(如持续小风)导致散热不良,立即发出“潜在过热风险”预警,并建议调整该线路的负荷分配(将部分电力转移到其他线路),国家电网采纳建议后,避免了可能的大面积停电事故,这种“基于基因图谱的预防性维护”,使特高压线路的故障率从每百公里每年0.8次降至0.3次,保障了能源安全。