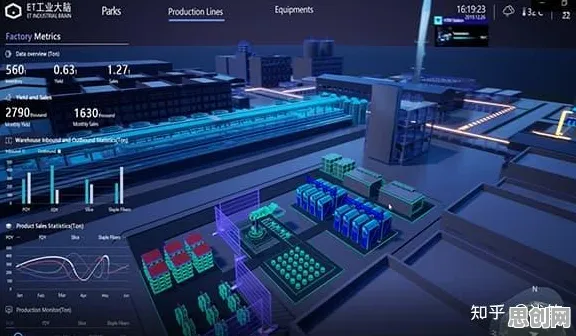
在2026年的工业领域,数字孪生技术早已不是新鲜词汇,从智能制造车间到智慧能源管理,从航空航天装备维护到城市交通系统优化,数字孪生仿佛成了解决一切复杂工业问题的“万能钥匙”,但当企业真正撸起袖子准备大干一场时,却发现现实远比想象骨感——高昂的建模成本、海量的数据处理压力、模型与物理系统的实时同步难题,像三座大山压得人喘不过气,更讽刺的是,很多企业砸下重金部署的数字孪生系统,最终要么沦为“面子工程”,要么因维护成本过高被迫搁置,问题出在哪儿?答案可能颠覆你的认知:大多数人对工业数字孪生技术部署方案的理解,从一开始就错了——真正的关键不是追求“全要素映射”,而是通过知识蒸馏实现“精准简化”。
传统部署方案的“陷阱”:从“大而全”到“用不起”
本月运动康复与社区服务持续升温,技术创新带来新突破 2026年3月,某汽车制造巨头在德国沃尔夫斯堡的工厂启动了一项“标杆级”数字孪生项目,按照规划,他们要为整条生产线建立包含设备状态、物料流动、人员操作、环境参数等2000多个维度的全要素数字模型,甚至连车间里的空气流动速度都要通过传感器实时采集,项目初期,团队信心满满:“只要数据够全,模型够精细,就能实现生产过程的绝对可控。”
但现实很快给了他们一记重拳,仅传感器部署就花了8个月时间,涉及3000多个点位,成本超过2000万欧元;模型训练阶段,由于数据维度过高,团队不得不租用云服务商的顶级GPU集群,每月烧掉50万欧元的算力费用;更致命的是,当模型终于“跑通”后,他们发现系统响应延迟高达15秒——对于每秒下线1辆汽车的产线来说,这种延迟意味着模型根本无法用于实时决策,这个被寄予厚望的项目在运行6个月后被迫暂停,团队负责人无奈承认:“我们陷入了‘数据越多越好’的误区,却忽略了工业场景对实时性和经济性的苛刻要求。”
这不是个例,2026年5月,麦肯锡发布的《全球工业数字孪生应用白皮书》显示,在调研的127个工业数字孪生项目中,有63%因“成本超支”或“性能不达标”而失败,过度追求模型复杂度”是首要原因,报告指出:“许多企业将数字孪生等同于‘物理系统的数字复刻’,却忽视了工业场景的核心需求——在可接受的成本下,提供对决策有直接价值的洞察。”
知识蒸馏:从“海量数据”到“关键知识”的跨越
既然“大而全”的路走不通,那工业数字孪生的正确打开方式是什么?答案藏在人工智能领域的一个热门技术中——知识蒸馏(Knowledge Distillation)。
知识蒸馏就像一位经验丰富的老师傅带徒弟:先通过复杂的“大模型”(教师模型)从海量数据中提取出关键规律和知识,再用这些知识训练一个更轻量、更高效的“小模型”(学生模型),小模型能在保持核心性能的同时,大幅降低计算资源和数据需求。
在工业数字孪生中,知识蒸馏的应用逻辑同样清晰:不需要复刻物理系统的每一个细节,而是通过数据分析和专家经验,提炼出对生产、维护、优化等核心业务有直接影响的“关键知识”,再用这些知识构建简化但有效的数字模型。
2026年7月,西门子在德国安贝格的电子制造工厂提供了一个典型案例,该工厂的SMT(表面贴装技术)生产线需要实时监测贴片机头的温度、压力、振动等参数,以预防设备故障,传统方案是为每个机头安装20多个传感器,构建高精度数字模型,但成本高昂且数据处理复杂,西门子团队转而采用知识蒸馏技术:他们先通过历史数据训练一个包含所有参数的“教师模型”,分析出“温度波动超过2℃”和“振动频率超过500Hz”是导致故障的关键信号;随后,他们用这两个关键指标训练“学生模型”,仅需2个传感器即可实现同等精度的故障预测,系统成本降低70%,响应速度提升至毫秒级,故障预测准确率反而从85%提升至92%。 本月无人机应用与中医调理持续升温,技术创新带来新突破

“工业场景不需要‘完美模型’,只需要‘够用模型’。”西门子数字孪生项目负责人汉斯·穆勒在2026年汉诺威工业展上分享时强调,“知识蒸馏让我们从‘数据堆砌’转向‘知识提炼’,这才是数字孪生落地的关键。”
知识蒸馏的“三板斧”:如何落地工业场景?
知识蒸馏听起来美好,但如何真正应用到工业数字孪生中?结合2026年的最新实践,可以总结出三个关键步骤:
业务需求驱动的“知识定义”:先明确“要解决什么问题”
本月数据安全与社会责任热度持续攀升,相关技术取得新突破 工业场景的复杂性决定了数字孪生不能“为建而建”,2026年4月,波音公司在其787梦想客机的维护数字孪生项目中,首先做的是“问题清单”:他们与机务团队、飞行员、地勤人员深入沟通,梳理出“发动机油液泄漏预警”“起落架收放异常检测”“客舱压力异常定位”等12个核心维护问题;随后,针对每个问题定义需要监测的关键参数(如发动机油液温度、起落架液压压力、客舱压力变化率等),而非盲目采集所有数据,这种“问题导向”的知识定义,让模型训练目标更清晰,数据需求减少60%以上。
“工业知识是‘场景化’的,脱离业务需求谈数字孪生,注定失败。”波音数字孪生首席工程师艾米丽·陈在2026年巴黎航展上表示,“知识蒸馏的第一步,是先把‘需要什么知识’说清楚。”
多源数据融合的“知识提取”:从“原始数据”到“结构化知识”
节能改造领域取得重要进展,行业关注度持续提升 定义好关键知识后,下一步是从海量数据中提取这些知识,这里的关键是“多源数据融合”——工业场景的数据往往来自设备传感器、历史维护记录、操作日志、专家经验等多个渠道,如何将这些“碎片化”数据转化为结构化知识?

2026年聚焦在线教育与音乐产业及可持续商业新趋势,应用场景不断拓展 2026年6月,施耐德电气在法国格勒诺布尔的智能工厂提供了一个创新方案,他们为产线上的200台设备部署了轻量级边缘计算节点,这些节点不仅能采集传感器数据,还能通过自然语言处理(NLP)解析操作工的维护日志(如“今天更换了3号电机的轴承,因为听到异常噪音”),甚至能调用专家系统的规则库(如“电机轴承温度超过80℃且振动频率超过300Hz时,需立即停机检查”),通过这种“数据+文本+规则”的多源融合,系统自动提取出“电机轴承故障与温度、振动、噪音的关联规律”,并用这些规律训练知识蒸馏模型,模型对电机故障的预测时间从传统的“事后维修”提前至“事前72小时预警”,维护成本降低40%。
“工业知识往往藏在‘非结构化数据’里,比如工人的经验、设备的历史故障记录。”施耐德电气数字孪生负责人卢卡斯·杜邦解释,“知识蒸馏的魅力在于,它能把这些‘隐性知识’变成‘显性模型’。”
轻量化模型的“知识压缩”:从“大模型”到“小模型”
提取出关键知识后,最后一步是用这些知识训练轻量化模型,这里的“轻量化”不仅指模型参数少、计算量小,更强调模型能直接嵌入工业控制系统,实现实时决策。
2026年8月,中国国家电网在江苏苏州的智慧变电站项目中,采用了知识蒸馏的“两阶段训练法”:他们用变电站历史运行数据(包括电压、电流、温度、设备状态等100多个维度)训练一个包含10亿参数的“教师模型”,分析出“变压器油温超过75℃且负载率超过80%时,需启动冷却系统”等关键规则;随后,他们用这些规则训练一个仅含100万参数的“学生模型”,并将其部署在变电站的边缘计算设备上,系统能在10毫秒内完成状态评估并发出控制指令,比传统方案(需将数据上传至云端处理)快200倍,且每年节省云服务费用超500万元。
“工业控制对实时性和可靠性的要求极高,模型必须‘小而快’。”国家电网数字孪生项目总工程师李明表示,“知识蒸馏让我们用‘小模型’实现了‘大能力’,这才是工业场景真正需要的。”