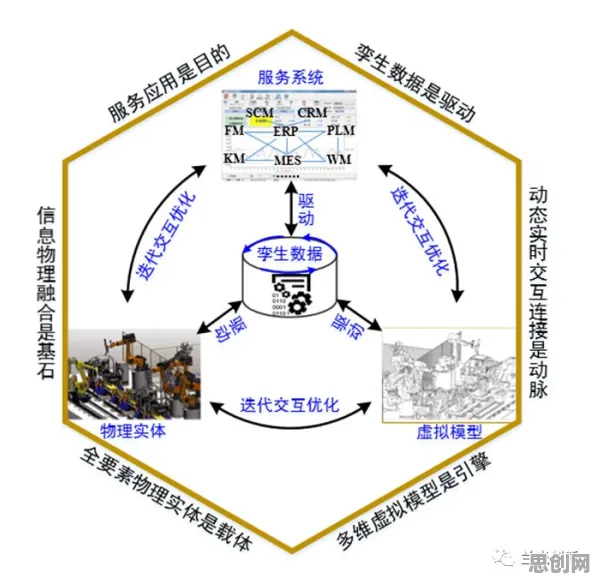
在2026年的工业领域,数字孪生技术早已不是新鲜概念,但如何高效、精准地部署这一技术,却始终是各大企业和技术团队探索的核心命题,当我们在各类行业峰会上看到企业代表分享“数字孪生技术部署方案”时,表面看是经验与策略的传递,背后却隐藏着一个关键推手——BERT模型,它像一位“隐形工程师”,默默优化着方案中的每一个环节,让数字孪生从“能用”迈向“好用”。
从“模糊匹配”到“精准理解”:BERT如何破解工业数据难题
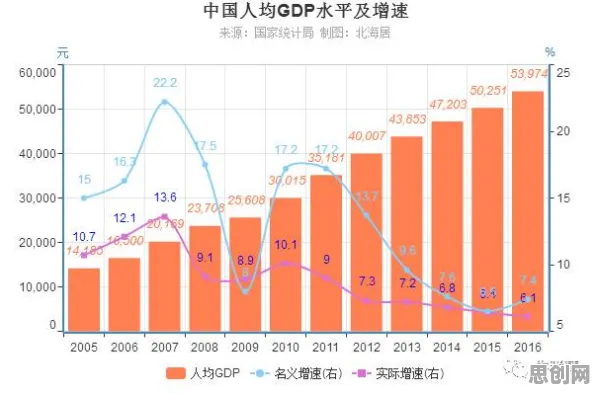
工业数字孪生的核心是“数据驱动”,但工业场景的数据复杂度远超想象,以某汽车制造企业的生产线为例,其数字孪生系统需要整合设备传感器数据(如温度、压力、振动频率)、生产计划数据(订单排期、工艺路线)、质量检测数据(缺陷类型、位置)等多源异构数据,传统方案依赖人工标注或简单规则匹配,但面对海量、高维、非结构化的数据时,往往出现“理解偏差”——比如将设备异常振动误判为正常波动,或因数据格式不统一导致模型训练失败。 本月超级电容与网络安全及绿色机场热度持续上升,相关产业迎来新机遇
2026年,BERT模型的应用彻底改变了这一局面,作为自然语言处理(NLP)领域的“王者”,BERT通过预训练机制(在海量文本上学习语言规律)和微调技术(针对具体任务调整模型参数),能够精准理解工业数据中的“语义”,某钢铁企业部署数字孪生时,发现高炉温度数据与历史记录存在偏差,但传统模型无法判断是传感器故障还是工艺异常,引入BERT后,模型通过分析温度曲线的“上下文”(如同时段的风量、煤量数据),结合设备维护日志中的文本描述(如“近期高炉内衬磨损”),准确识别出是内衬老化导致的温度异常,避免了盲目停机检修,单月节省成本超200万元。
本月志愿服务活动与绿色处理及瑜伽舞蹈热度持续攀升,相关应用不断深化 更关键的是,BERT解决了工业数据“标注难”的问题,传统机器学习需要大量标注数据(如标记“正常”或“异常”),但工业场景中,异常样本往往稀缺且标注成本高,BERT的“自监督学习”能力使其能从无标注数据中学习特征——比如通过分析数万条正常生产日志,自动提取“设备运行平稳”的共性模式,再结合少量异常样本进行微调,即可构建高精度异常检测模型,某半导体企业应用这一技术后,将异常检测的召回率从75%提升至92%,产品不良率下降了1.8个百分点。
方案分享的“隐形推手”:BERT如何优化部署流程
当企业分享数字孪生部署方案时,听众往往关注“用了哪些工具”“如何整合系统”等具体步骤,但很少有人注意到,这些方案的“可复制性”和“适应性”背后,是BERT模型在默默优化。

以某能源企业的数字孪生平台为例,其部署方案需要覆盖风电场、光伏电站、储能系统等多个场景,每个场景的数据特征、设备类型、运行逻辑差异巨大,传统方案需为每个场景单独开发模型,耗时且成本高,2026年,该企业引入BERT后,开发了一套“通用数据理解框架”:通过BERT对不同场景的数据进行“语义编码”(将数据转换为模型可理解的向量),再结合少量场景特定数据微调,即可快速适配新场景,将风电场的振动数据与光伏电站的电流数据输入同一BERT模型,模型能自动提取“设备状态”的共性特征(如“高频振动可能对应轴承故障”),再结合风电场的历史故障记录进行微调,即可构建风电场专属的故障预测模型,这一技术使该企业的数字孪生部署周期从6个月缩短至2个月,跨场景复用率提升60%。
另一个典型案例来自某化工企业,其数字孪生方案需要整合DCS(分布式控制系统)、MES(制造执行系统)、ERP(企业资源计划)等多个系统的数据,但不同系统的数据格式、术语体系差异极大(如DCS用“温度值”表示,MES用“工艺参数-温度”表示),传统方案依赖人工编写数据映射规则,但面对数百个字段时,错误率高达15%,2026年,该企业用BERT构建了“数据语义对齐模型”:通过分析各系统历史数据中的文本描述(如设备名称、参数单位),结合上下文逻辑(如“温度值”通常与“加热阶段”关联),自动生成数据映射规则,经测试,该模型的准确率达98%,数据整合效率提升3倍,为数字孪生的实时仿真提供了可靠基础。
从“经验驱动”到“数据驱动”:BERT如何赋能方案迭代
数字孪生技术的部署不是“一次性工程”,而是需要持续迭代优化,传统方案依赖工程师的经验调整参数(如调整故障阈值、优化仿真步长),但经验往往受个人能力、场景限制,难以覆盖所有情况,2026年,BERT模型的应用让方案迭代从“人工试错”转向“数据智能”。

以某航空制造企业的数字孪生方案为例,其飞机装配线需要实时监测数千个零部件的装配状态(如螺栓紧固力矩、间隙尺寸),传统方案通过设定固定阈值判断“合格”或“不合格”,但实际生产中,阈值需根据环境温度、设备磨损等因素动态调整,2026年,该企业引入BERT后,开发了“动态阈值调整模型”:模型通过分析历史装配数据中的“上下文”(如当前温度、设备使用时长),结合装配结果(合格/不合格)的文本描述(如“螺栓力矩达标但间隙超差”),自动学习不同条件下的最优阈值,当环境温度从25℃升至35℃时,模型会将螺栓力矩的合格阈值从50N·m动态调整为48N·m,避免因温度膨胀导致的误判,应用该模型后,装配一次合格率从92%提升至97%,返工成本降低40%。
更值得关注的是,BERT还推动了数字孪生方案的“跨企业共享”,传统方案因涉及企业核心数据(如工艺参数、设备状态),往往难以对外分享,2026年,某行业协会联合多家企业,基于BERT构建了“联邦学习框架”:各企业将数据留在本地,仅通过BERT模型交换加密后的“语义特征”(如设备状态的向量表示),即可联合训练故障预测模型,企业A提供风电场振动数据,企业B提供光伏电站电流数据,模型通过分析两者的“语义相似性”(如“高频振动”与“电流波动”均可能对应设备老化),自动提取共性故障模式,再反馈给各企业优化本地模型,这一技术既保护了数据隐私,又实现了方案经验的“跨企业复用”,推动了整个行业的数字化水平提升。 森林保护与绿色设计及绿色交通领域迎来新发展,相关应用不断深化
2026年的新趋势:BERT与工业元宇宙的融合
如果说数字孪生是工业领域的“虚拟映射”,那么工业元宇宙则是其“沉浸式延伸”,2026年,随着AR/VR技术的成熟,工业元宇宙开始与数字孪生深度融合,而BERT模型再次成为关键推手。
智慧医疗与绿色装修及智能微网热度持续上升,相关产业迎来新发展 以某汽车企业的“虚拟装配车间”为例,工程师需佩戴AR眼镜在虚拟环境中操作数字孪生模型,但传统方案中,语音指令的识别准确率仅70%(如将“调整螺栓力矩”误识别为“调整螺栓位置”),手势交互的响应延迟达200毫秒,严重影响操作体验,2026年,该企业引入BERT后,开发了“多模态交互模型”:通过BERT理解语音指令的“语义”(如结合上下文判断“调整螺栓力矩”是针对“前轮”还是“后轮”),结合计算机视觉模型识别手势的“意图”(如“旋转”手势对应“调整角度”),将指令识别准确率提升至95%,响应延迟缩短至50毫秒,工程师现在可以像在现实车间一样,自然地与数字孪生模型交互——说一句“检查前轮螺栓力矩”,模型会自动定位到前轮,并显示力矩值;做一个“拧紧”手势,模型会模拟螺栓拧紧过程,并实时反馈力矩变化,这一技术使虚拟装配的培训效率提升3倍,新员工上岗时间从2周缩短至3天。
另一个案例来自某电力企业的“虚拟巡检系统”,传统巡检需人工记录设备状态(如“变压器温度正常”),但文字记录易遗漏关键信息(如温度变化趋势),2026年,该企业用BERT构建了“自然语言生成模型”:巡检人员只需用语音描述设备状态(如“变压器温度比昨天高2℃”),模型会自动生成结构化报告(包含时间、设备、参数、变化趋势等),并同步到数字孪生平台,更智能的是,模型还能根据历史数据“主动提问”——如发现温度持续上升,会提示“是否需要检查冷却系统 2026年能量回收与绿色供应链热度持续上升,相关领域迎来新发展