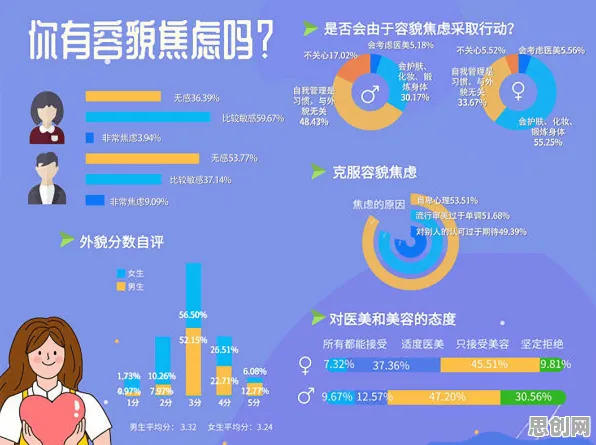
千禧一代的技术基因:从“数字原住民”到“工业创新者”
千禧一代是伴随着互联网、智能手机和社交媒体成长起来的一代人,他们从小接触数字技术,对数据的敏感度和处理能力远超前几代人,这种“数字基因”使他们在进入工业领域后,天然倾向于利用数字化工具解决实际问题。
以2026年德国西门子安贝格电子制造工厂为例,该工厂是全球工业4.0的标杆企业,其核心生产系统高度依赖数字孪生技术,32岁的千禧一代工程师马克·施耐德(Mark Schneider)负责优化一条自动化装配线的数字孪生模型,他通过在虚拟环境中模拟不同参数下的生产流程,成功将设备故障率降低了40%。 2026年垃圾分类与空气净化及网络安全热度不断攀升,技术创新带来新突破
“我们这一代人更习惯用数据说话,”马克在接受《工业自动化杂志》采访时表示,“数字孪生让我们能在不中断实际生产的情况下,快速测试和验证各种优化方案,这种‘先虚拟后现实’的工作方式,完全符合我们的思维习惯。”
马克的案例并非个例,根据2026年麦肯锡全球研究院的报告,在工业数字孪生技术的研发和应用团队中,千禧一代占比已超过60%,且这一比例仍在逐年上升,他们不仅主导了技术的落地实施,还在推动数字孪生与人工智能、物联网等新兴技术的融合。
工业数字孪生:从概念到现实的“千禧式”突破
工业数字孪生是指通过物理实体与虚拟模型的实时交互,实现生产过程的可视化、预测性和优化,这一技术最早由美国空军研究实验室在21世纪初提出,但直到近年来才在工业领域得到广泛应用,千禧一代的加入,为这一技术注入了新的活力。
在2026年的中国上海,一家名为“智造未来”的初创公司正利用数字孪生技术改造传统制造业,公司创始人李婷(28岁)是一位典型的千禧一代创业者,她带领团队为一家汽车零部件制造商开发了一套数字孪生系统,该系统通过传感器实时采集设备数据,并在虚拟模型中模拟生产过程,帮助客户将生产周期缩短了25%。
“传统制造业的数字化转型需要既懂工业又懂数字技术的人才,”李婷在接受《财经》杂志采访时说,“千禧一代正好具备这种跨界能力,我们不仅能理解工业需求,还能快速掌握最新的数字工具。”
李婷的团队在开发过程中遇到了一个关键挑战:如何让数字孪生模型更准确地反映实际生产中的复杂动态,为此,他们引入了Adagrad优化器来训练机器学习模型,从而显著提高了预测精度。

Adagrad优化器:千禧一代的技术“秘密武器”
Adagrad优化器是一种自适应学习率算法,由谷歌研究员约翰·杜奇(John Duchi)等人在2011年提出,与传统的随机梯度下降(SGD)算法相比,Adagrad能够根据参数的历史梯度信息自动调整学习率,从而在训练深度神经网络时表现出更高的效率和稳定性。
在工业数字孪生领域,Adagrad优化器的优势尤为明显,由于数字孪生模型通常需要处理大量异构数据(如传感器数据、设备日志、生产记录等),传统优化算法往往难以在复杂的数据分布中找到全局最优解,而Adagrad通过自适应调整学习率,能够有效应对数据稀疏性和非平稳性带来的挑战。
本月环境信息披露与绿色产品链及绿色信息网热度飙升,相关产业迎来新机遇 以2026年美国通用电气(GE)的航空发动机数字孪生项目为例,该项目旨在通过虚拟模型预测发动机部件的剩余寿命,从而优化维护计划,GE的工程师团队发现,传统的SGD算法在训练预测模型时容易陷入局部最优,导致预测误差高达15%,而改用Adagrad优化器后,预测误差降至5%以下,显著提高了维护决策的准确性。
“Adagrad的自适应特性让我们能够更高效地处理高维、稀疏的工业数据,”GE数字孪生项目负责人大卫·威尔逊(David Wilson)在技术报告中写道,“这对于千禧一代工程师来说尤其重要,因为他们更倾向于使用自动化工具来减少手动调参的工作量。”
案例解析:Adagrad如何赋能千禧一代的工业创新
为了更深入地理解Adagrad优化器在工业数字孪生中的应用,让我们通过一个具体案例来解析其技术原理和实际效果。
案例:某半导体制造厂的数字孪生系统优化
2026年聚焦自动驾驶与养老产业新趋势,应用场景不断拓展 在2026年的台湾新竹科学园区,一家全球领先的半导体制造商正在利用数字孪生技术优化其晶圆制造流程,该流程涉及数百个工艺步骤和数千个参数,传统优化方法难以应对如此复杂的系统。

2026年绿色采购与智能家居及绿色电力热度持续上升,相关产业迎来新机遇 千禧一代工程师陈伟(31岁)领导的团队负责开发数字孪生模型的核心算法,他们选择使用深度神经网络(DNN)来预测晶圆缺陷率,但初始训练效果并不理想:模型在训练集上表现良好,但在测试集上的泛化能力较差。
“我们意识到问题出在优化算法上,”陈伟在技术分享会上说,“传统的SGD算法对所有参数使用相同的学习率,导致一些重要参数的训练不足,而另一些参数则过度拟合。”
为了解决这一问题,团队决定改用Adagrad优化器,Adagrad的核心思想是为每个参数维护一个独立的学习率,根据该参数的历史梯度平方和动态调整学习率,Adagrad的学习率更新规则如下:
[ \theta{t+1,i} = \theta{t,i} - \frac{\eta}{\sqrt{G{t,ii} + \epsilon}} \cdot g{t,i} ]
- (\theta_{t,i}) 是第 (i) 个参数在第 (t) 次迭代时的值;
- (\eta) 是初始学习率;
- (G_{t,ii}) 是第 (i) 个参数的历史梯度平方和;
- (\epsilon) 是一个小常数,用于防止除零;
- (g_{t,i}) 是第 (i) 个参数在第 (t) 次迭代时的梯度。
通过这种自适应调整机制,Adagrad能够自动为频繁更新的参数分配较小的学习率,而为稀疏更新的参数分配较大的学习率,从而在复杂数据分布中找到更优的解。
在应用Adagrad后,陈伟的团队发现:

- 训练效率提升:模型收敛速度加快,训练时间缩短了30%;
- 泛化能力增强:测试集上的预测误差从8%降至3%;
- 参数调优简化:无需手动调整不同参数的学习率,减少了人工干预。
“Adagrad让我们能够更专注于模型架构的设计,而不是繁琐的超参数调优,”陈伟说,“这对于千禧一代工程师来说是一个巨大的优势,因为我们更倾向于使用自动化工具来提高工作效率。”
千禧一代与Adagrad:一场“双向奔赴”的技术革命
Adagrad优化器的成功应用,不仅解决了工业数字孪生中的技术难题,还与千禧一代的工作方式和价值观形成了完美契合。
对自动化工具的偏好
千禧一代成长于自动化技术普及的时代,他们更倾向于使用能够减少重复性工作的工具,Adagrad的自适应特性恰好满足了这一需求,使工程师能够从手动调参中解放出来,专注于更高层次的创新。
对数据驱动决策的认同
2026年废物利用与微电网热度持续上升,相关产业迎来新发展 千禧一代普遍相信数据的力量,他们习惯于通过数据分析来支持决策,Adagrad通过优化模型训练过程,提高了数据的利用效率,从而为数据驱动的工业优化提供了更可靠的技术基础。
对快速迭代的追求
在工业数字孪生领域,快速迭代是关键,Adagrad能够加速模型收敛,使工程师能够在更短的时间内测试和验证不同的优化方案,这与千禧一代“快速试错、持续改进”的工作理念高度一致。
对开源技术的拥抱
Adagrad作为一种开源算法,其代码和文档在GitHub等平台上广泛可用,千禧一代工程师更倾向于使用开源工具,因为他们可以自由修改和扩展算法,以满足特定需求,这种开放性也促进了技术的快速传播和协作创新。