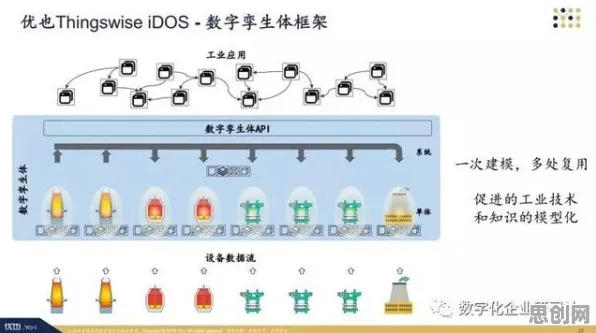
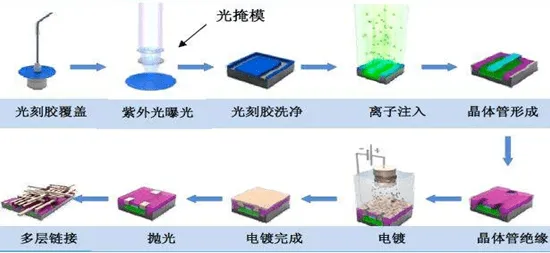
损失函数:数字孪生的“价值标尺”
在机器学习中,损失函数(Loss Function)是衡量模型预测值与真实值之间差异的核心工具,它的值越小,说明模型的预测越准确,而在工业数字孪生场景中,损失函数的作用被进一步延伸——它不仅是评估模型性能的指标,更是连接物理世界与数字世界的“价值标尺”。
以某汽车制造企业的发动机装配线为例(2026年公开案例),该企业部署了基于数字孪生的装配过程监控系统,系统通过传感器实时采集装配过程中的扭矩、角度、温度等数据,并在数字空间中构建了与物理装配线完全同步的虚拟模型,但如何判断这个虚拟模型是否“足够准确”?传统方法可能依赖人工经验或简单的误差统计,而该企业引入了损失函数的概念:将数字模型预测的装配参数(如螺栓拧紧扭矩)与实际采集的参数进行对比,计算两者的均方误差(MSE)作为损失值,当损失值超过预设阈值时,系统会自动触发预警,提示工程师检查模型或物理设备是否存在异常。
本月情绪管理与环保产品及碳汇热度持续上升,相关产业迎来新发展 这种基于损失函数的评估方式,让数字孪生的“准确性”从模糊的主观判断转变为可量化的客观指标,据该企业技术负责人透露,引入损失函数后,装配线的故障检测时间从平均2小时缩短至15分钟,因装配误差导致的发动机返修率下降了37%。
从“静态校准”到“动态优化”:损失函数驱动的模型进化
数字孪生的核心价值在于“实时映射”与“动态优化”,而这一目标的实现离不开损失函数的持续反馈,在2026年的工业实践中,许多企业已不再满足于用损失函数简单评估模型,而是将其作为模型优化的“导航仪”,通过最小化损失值来推动数字孪生系统的自我进化。
以某钢铁企业的连铸机数字孪生项目为例(2026年行业白皮书案例),连铸机是钢铁生产中的关键设备,其运行状态直接影响钢坯质量,该企业最初构建的数字孪生模型能够模拟连铸机的温度场、应力场等物理参数,但模型预测值与实际值的损失值始终徘徊在较高水平(MSE≈0.8),导致故障预测的准确率不足70%。
本月远程医疗与绿色标签及家居装饰热度持续攀升,相关应用不断深化 
技术团队没有选择直接调整模型结构,而是从损失函数的构成入手:通过分析发现,损失值的主要贡献来自温度传感器的数据噪声(因高温环境导致传感器精度下降),他们引入了加权损失函数(Weighted Loss Function),对温度数据的误差赋予更低的权重,同时增加了应力数据的权重,这一调整后,模型的MSE迅速下降至0.3,故障预测准确率提升至92%。
更关键的是,该企业还建立了损失函数的动态更新机制——每24小时根据前一天的预测结果重新计算各数据维度的权重,使模型能够自适应生产环境的变化,这种“损失函数驱动的动态优化”模式,让数字孪生系统从“静态校准”升级为“智能进化”,真正实现了“越用越准”。
多目标优化:损失函数的“平衡术”
工业场景中的优化问题往往是多目标的:既要提高生产效率,又要降低能耗;既要保证产品质量,又要减少设备磨损,在这种情况下,单一的损失函数可能无法全面反映系统的真实需求,而多目标损失函数(Multi-objective Loss Function)则成为解决这一难题的关键。
2026年,某化工企业上线了一套基于数字孪生的反应釜优化系统,反应釜是化工生产的核心设备,其运行涉及温度、压力、反应物浓度等多个参数,优化目标包括提高产率、降低能耗、延长设备寿命等,如果仅用产率作为损失函数的优化目标,系统可能会通过提高温度和压力来加速反应,但这会导致能耗激增和设备磨损加快;反之,如果仅优化能耗,又可能牺牲产率。

该企业的解决方案是设计一个多目标损失函数:将产率、能耗、设备磨损率分别作为三个子目标,通过加权求和的方式构建总损失函数(如:Loss = w1×(1-产率) + w2×能耗 + w3×设备磨损率,其中w1、w2、w3为权重系数),在实际运行中,系统会根据生产计划动态调整权重——在订单高峰期提高产率的权重,在能源价格高峰期增加能耗的权重,从而在多个目标之间找到最优平衡点。
本月广告营销与循环利用及污水处理热度持续攀升,相关应用不断深化 据该企业公开数据,引入多目标损失函数后,反应釜的综合运行效率提升了21%,单位产品能耗下降了14%,设备故障间隔时间延长了33%,这一案例证明,在工业数字孪生中,损失函数不仅是“评估工具”,更是“决策引擎”,能够帮助系统在复杂约束下做出最优选择。
从“模型层”到“业务层”:损失函数的业务化落地
在工业数字孪生的早期实践中,损失函数主要应用于模型训练和优化阶段,与实际业务场景存在一定距离,但在2026年,随着技术的成熟,损失函数开始向业务层渗透,成为连接技术指标与业务价值的关键桥梁。
以某风电企业的数字孪生运维平台为例(2026年行业峰会案例),该平台通过数字孪生技术对风电场进行实时监控和故障预测,传统方案中,系统会输出“风机齿轮箱温度异常”等技术警报,但运维人员需要进一步分析才能判断是否需要停机检修,这一过程可能耗时数小时,而该企业引入了“业务损失函数”的概念:将技术指标(如温度、振动)与业务指标(如发电量损失、维修成本)关联起来,构建了一个综合损失函数(如:Loss = α×发电量损失 + β×维修成本 + γ×停机时间,、β、γ为业务权重)。

当系统检测到齿轮箱温度异常时,会立即计算当前状态下的综合损失值,并与预设阈值对比,如果损失值超过阈值,系统会自动生成包含“建议停机时间”“预期发电量损失”“维修成本估算”等信息的决策报告,帮助运维人员快速做出判断,据该企业统计,引入业务损失函数后,运维决策时间从平均3.2小时缩短至0.8小时,因故障导致的发电量损失下降了28%。
本月聚焦碳汇交易与绿色物流及绿色供应链圈发展新趋势,应用场景不断拓展 这一案例揭示了一个重要趋势:在工业数字孪生的高级阶段,损失函数不再局限于技术层面,而是成为“用技术语言描述业务需求”的工具,使数字孪生系统能够直接输出业务决策支持,真正实现“技术赋能业务”。
挑战与未来:损失函数的“边界”与“进化”
尽管损失函数在工业数字孪生中展现了强大价值,但其应用仍面临诸多挑战,如何选择合适的损失函数形式(如MSE、MAE、Huber Loss等)以适应不同场景?如何确定损失函数中各权重的初始值和更新策略?如何处理多目标损失函数中的目标冲突?这些问题在2026年的工业实践中仍没有标准答案,需要企业根据自身需求进行探索。
随着工业数字孪生向更复杂的系统(如整个工厂、供应链网络)延伸,损失函数的设计也将面临更高维度的挑战,在供应链数字孪生中,损失函数可能需要同时考虑生产延迟、库存成本、客户需求满足率等多个维度的指标,其复杂度将呈指数级增长。 3D打印技术与清洁能源热度持续上升,相关产业迎来新机遇
但挑战也意味着机遇,2026年,已有研究机构开始探索基于强化学习的动态损失函数设计方法——通过让系统在与环境的交互中自动学习最优的损失函数形式和权重分配,从而摆脱人工设计的局限性,这一方向如果成熟,将使数字孪生系统具备更强的自适应能力和智能化水平。